test
This commit is contained in:
parent
a6d75291c3
commit
14f4cb5c9f
3
.obsidian/app.json
vendored
3
.obsidian/app.json
vendored
@ -1,4 +1,5 @@
|
||||
{
|
||||
"attachmentFolderPath": "Attachments",
|
||||
"alwaysUpdateLinks": true
|
||||
"alwaysUpdateLinks": true,
|
||||
"showLineNumber": false
|
||||
}
|
||||
6
.obsidian/core-plugins.json
vendored
6
.obsidian/core-plugins.json
vendored
@ -4,14 +4,14 @@
|
||||
"switcher": true,
|
||||
"graph": true,
|
||||
"backlink": true,
|
||||
"outgoing-link": false,
|
||||
"outgoing-link": true,
|
||||
"tag-pane": true,
|
||||
"page-preview": true,
|
||||
"daily-notes": true,
|
||||
"templates": true,
|
||||
"note-composer": true,
|
||||
"command-palette": true,
|
||||
"slash-command": false,
|
||||
"slash-command": true,
|
||||
"editor-status": true,
|
||||
"markdown-importer": true,
|
||||
"zk-prefixer": true,
|
||||
@ -29,5 +29,5 @@
|
||||
"bookmarks": true,
|
||||
"footnotes": false,
|
||||
"bases": true,
|
||||
"webviewer": false
|
||||
"webviewer": true
|
||||
}
|
||||
4
.obsidian/note-composer.json
vendored
Normal file
4
.obsidian/note-composer.json
vendored
Normal file
@ -0,0 +1,4 @@
|
||||
{
|
||||
"askBeforeMerging": true,
|
||||
"template": "Templates/Journal Template"
|
||||
}
|
||||
5
.obsidian/types.json
vendored
5
.obsidian/types.json
vendored
@ -25,7 +25,7 @@
|
||||
"season": "number",
|
||||
"series": "multitext",
|
||||
"source": "text",
|
||||
"status": "multitext",
|
||||
"status": "text",
|
||||
"twitter": "text",
|
||||
"trade": "text",
|
||||
"purchased": "date",
|
||||
@ -50,6 +50,7 @@
|
||||
"monthly-uses": "number",
|
||||
"runtime": "number",
|
||||
"pages": "number",
|
||||
"acquired": "date"
|
||||
"acquired": "date",
|
||||
"stat": "checkbox"
|
||||
}
|
||||
}
|
||||
7
2026-02-16 1548 Redis Client Local Dev Setup ergänzt.md
Normal file
7
2026-02-16 1548 Redis Client Local Dev Setup ergänzt.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
created: 2026-02-16
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
Siehe https://github1.vg.vector.int/pmc/vcf-library-redis/pull/7
|
||||
23
2026-02-17 0953 Abstimmung mit Klaus.md
Normal file
23
2026-02-17 0953 Abstimmung mit Klaus.md
Normal file
@ -0,0 +1,23 @@
|
||||
---
|
||||
created: 2026-02-17
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Meetings]]"
|
||||
type:
|
||||
- "[[Abstimmung]]"
|
||||
date: 2026-02-17
|
||||
org:
|
||||
- "[[Vector]]"
|
||||
loc:
|
||||
people:
|
||||
- "[[Klaus Bergdolt]]"
|
||||
topics:
|
||||
- "[[RMS]]"
|
||||
- "[[Gantt France]]"
|
||||
---
|
||||
- Könnten theoretisch das ganze Thema ablehnen wollen wir aber nicht
|
||||
- Idealerweise setzen wir ein System auf, dass genau diesen Usecase umfasst. Sprich, die Leute können sich über einen Self-Service ihre Applikationen ins unsere Platform anmelden, welche das Deployment übernimmt. Anschließend werden über eine Konfiguration die erlaubten AD Gruppen/User eingestellt. Die Authentifizierung/Authorisierung übernimmt dann die Platform während alle Requests zur Applikation bereits verifiziert sind.
|
||||
So ein System können wir allerdings nicht adhoc bieten sondern wir müssen Felicien vermutlich vertrösten, dass wir das Thema im Laufe des Jahres angehen allerdings noch nicht genau wissen wann.
|
||||
- RMS CAT3 wollen wir die Requirements nochmal erneut aufschlüsseln (mehr Kontext als die XMind Datei) um besser verstehen zu können, was das MVP wäre.
|
||||
38
2026-02-17 1217 RMS Anforderungen XMind.md
Normal file
38
2026-02-17 1217 RMS Anforderungen XMind.md
Normal file
@ -0,0 +1,38 @@
|
||||
---
|
||||
created: 2026-02-17
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
project: "[[RMS]]"
|
||||
---
|
||||
- Anforderung an RMS
|
||||
- Alokation der Ressourcen im Projekt
|
||||
- Rollenspezifisch
|
||||
- Notwendig für die Auswertung Richtung PrOServ Cluster
|
||||
- Es sollen die Rollen aus dem Prozess umgesetzt werden
|
||||
- Einer Person soll mehrere Rollen zugewiesen werden können
|
||||
- Eine Person soll im Projekt mehrere Rollen begleiten können
|
||||
- *Externe MA mit Rolle (Ausserhalb von PES8; bzw. nicht in der Employee-Liste von RMS enthalten)*
|
||||
- Graphische Auswertung
|
||||
- Anzahl MA im Project pro Zeitraum
|
||||
- Anzahl Rollen im Projekt/Cluster pro Zeitraum
|
||||
- Der rollenspezifische Bedarf über alle Cluster (Virtuelle Bereiche) soll dargestellt werden (Nicht auf CAT3 beschränkt; Ist + Soll/Potentielle Planung PreSales)
|
||||
- Der PreSales Bereich sollte sichtbar gemacht werden, als potentielle Planung
|
||||
- Soll / Ist Vergleich im Projekt
|
||||
- Es soll ein konkrete und virtuelle Zuweisung ersichtlich sein (z.B. Es soll sichtbar sein, dass Rollen noch nicht konkret besetzt sind)
|
||||
- ==Es soll dargestellt werden können, ob freie Ressourcen vorhanden wären (Prio1 Tasks vs. Prio 2 Tasks).==
|
||||
- Planspiel (z.B. PreSales)
|
||||
- Virtuelle Projekte PreSales
|
||||
- Zuordnung von viruellen MA/Rollen (z.B. alter NN im alten TRP) aus den Clustern
|
||||
- Zuordnung von Konkreten MA
|
||||
- Projekte sollen ausgeblendet werden können ("an/aus schalten")
|
||||
- Projekte sollen von PreSales auf produktiv geschalten werden können
|
||||
- Es muss unterschiedliche Sichtweisen geben
|
||||
- PreSales Projekte sollen von laufenden Projekten unterscheidbar sein (z.B. Attribut)
|
||||
- Benötigte Rollen aus den Clustern
|
||||
- Virtuelles Projekt muss gelöscht werden können
|
||||
- Virtuelles Projekt muss ein DueDate haben und in der Ansicht gekennzeichnet werden (z.B. Projekt wird rot)
|
||||
- Bestellte Umfänge, welche durch Ressourcen abgedeckt werden müssen
|
||||
- Nicht Funktionale Anforderung
|
||||
- Darstellung sollte in einem Tool erfolgen können
|
||||
- Es soll eine einfache Möglichkeit geben die Ressourcen anzupassen
|
||||
22
2026-02-17 PI Planung.canvas
Normal file
22
2026-02-17 PI Planung.canvas
Normal file
@ -0,0 +1,22 @@
|
||||
{
|
||||
"nodes":[
|
||||
{"id":"7cebdc271187a3a9","type":"file","file":"Evaluierung eines generischen Frontend‑ und API‑Ansatzes in XaD.md","x":-1280,"y":-160,"width":360,"height":120,"color":"3"},
|
||||
{"id":"1518759312c54c1c","type":"file","file":"Standardisierter Credential‑Prozess für Data Mesh eingeführt.md","x":-1280,"y":0,"width":360,"height":123,"color":"3"},
|
||||
{"id":"3c058ecc96c12ba1","type":"file","file":"Zertifikatsaustausch in allen Diensten abgeschlossen.md","x":-1280,"y":160,"width":360,"height":120,"color":"3"},
|
||||
{"id":"af3a32efe38421a0","type":"text","text":"Single‑Sign‑On für React Admin funktionsfähig","x":-780,"y":-140,"width":360,"height":80},
|
||||
{"id":"832f717268208530","type":"file","file":"Jira‑Changelog als Datenprodukt verfügbar.md","x":-1280,"y":320,"width":360,"height":100,"color":"3"},
|
||||
{"id":"f4bdef93f1e80d95","type":"file","file":"TISAX‑konforme Datenbank‑Access‑Logs verfügbar in DataMesh.md","x":-1280,"y":460,"width":360,"height":120,"color":"3"},
|
||||
{"id":"78f0137d59cb2342","type":"file","file":"Standard Checks test specification wird dynamisch generiert.md","x":-1280,"y":620,"width":360,"height":130,"color":"3"},
|
||||
{"id":"99e07d991815875e","type":"file","file":"Anforderungsliste zur Verbesserung des Entwicklererlebnisses im Data Mesh erstellt.md","x":-1280,"y":780,"width":360,"height":160,"color":"3"},
|
||||
{"id":"570da2c32b38130c","type":"file","file":"Basis‑Branch‑Handling und Pull Requests in XaC umgesetzt.md","x":-1280,"y":980,"width":360,"height":120,"color":"3"},
|
||||
{"id":"6cd82bb45335c110","type":"file","file":"Data‑Mesh‑Datenprodukte werden als Paket veröffentlicht.md","x":-1280,"y":1140,"width":360,"height":140,"color":"3"},
|
||||
{"id":"5a78cc1ac92a6484","type":"text","text":"# ⌛In Progress","x":40,"y":-179,"width":360,"height":79},
|
||||
{"id":"fed5c92502e19820","type":"file","file":"Eventbasierte Datenintegration im XaD validiert.md","x":40,"y":-58,"width":360,"height":120,"color":"3"},
|
||||
{"id":"f633064bfe210ed8","type":"text","text":"# ✅Done","x":560,"y":-179,"width":360,"height":79},
|
||||
{"id":"8fec743c5e716348","type":"file","file":"Generalisierte Jira‑Views als Datenprodukt.md","x":560,"y":-58,"width":360,"height":80,"color":"4"},
|
||||
{"id":"d79509ac582c7881","type":"file","file":"Wartungsaufwand für InvoiceService VM eliminiert.md","x":-1280,"y":1340,"width":360,"height":120,"color":"3"}
|
||||
],
|
||||
"edges":[
|
||||
{"id":"dcfcd535ea181160","fromNode":"7cebdc271187a3a9","fromSide":"right","toNode":"af3a32efe38421a0","toSide":"left"}
|
||||
]
|
||||
}
|
||||
9
2026-02-19 1558 Transferiere die lokale Dev CI.md
Normal file
9
2026-02-19 1558 Transferiere die lokale Dev CI.md
Normal file
@ -0,0 +1,9 @@
|
||||
---
|
||||
created: 2026-02-19
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Tasks]]"
|
||||
stat: false
|
||||
---
|
||||
7
2026-02-19 1851 Zabuton.md
Normal file
7
2026-02-19 1851 Zabuton.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
created: 2026-02-19
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
Zabuton nennt man die Sitzkissen, mit denen die Japaner auf dem Boden hocken
|
||||
7
2026-02-19 2039 Docker from Docker.md
Normal file
7
2026-02-19 2039 Docker from Docker.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
created: 2026-02-19
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
The Docker client runs inside the container, communicating with the external Docker service. The images remain on the hosted system. Containerized applications are run as sidecars, but they appear to be part of the current container.
|
||||
7
2026-02-19 2040 Docker-in-Docker.md
Normal file
7
2026-02-19 2040 Docker-in-Docker.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
created: 2026-02-19
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
The Docker services run inside the container, with images preserved in the container. This is similar to nested virtualization with VMs. This can require a bit more setup and privileges.
|
||||
7
2026-02-20 1048 AD Apps.md
Normal file
7
2026-02-20 1048 AD Apps.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
created: 2026-02-20
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
[[René Zauner]] befragen
|
||||
@ -0,0 +1,64 @@
|
||||
---
|
||||
created: 2026-02-23
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
type:
|
||||
- "[[Exploratory]]"
|
||||
---
|
||||
## Kontext
|
||||
*Wo tritt das Problem auf?*
|
||||
*Welches System? Welche Annahmen habe ich?*
|
||||
|
||||
- Authentik statet nicht ohne diese beiden Services. Welche Daten landen wo und was passiert, wenn einer der beiden ausfällt?
|
||||
|
||||
|
||||
> [!NOTE] Denkanstöße
|
||||
> - Was speichert ein Identity Provider dauerhaft?
|
||||
> - Was muss schnell und flüchtig abrufbar sein?
|
||||
> - Warum reicht nicht einfach SQLite?
|
||||
|
||||
|
||||
---
|
||||
|
||||
## Beobachtung
|
||||
*Was sehe ich konkret?*
|
||||
*Logs, Verhalten, Fehlermeldungen, Performance-Werte …*
|
||||
|
||||
- Das Authentik Docker Compose beinhaltet: Authentik Server, Authentik Worker, Postgresql und Redis
|
||||
|
||||
---
|
||||
|
||||
## Hypothesen
|
||||
- H1:
|
||||
- H2:
|
||||
- H3:
|
||||
|
||||
*Welche Annahmen erkläre ich mir gerade selbst?*
|
||||
|
||||
---
|
||||
|
||||
## Experimente
|
||||
- [ ] Stoppe Redis mit `docker compose stop redis` während du eingeloggt bist. Was passiert beim nächsten Seitenaufruf? Warum?
|
||||
|
||||
*Was teste ich gezielt?*
|
||||
Verhalten von Authentik wenn abhängige Services unerreichbar werden.
|
||||
|
||||
---
|
||||
|
||||
## Ergebnisse
|
||||
*Was ist tatsächlich passiert?*
|
||||
*Welche Hypothesen wurden widerlegt?*
|
||||
|
||||
---
|
||||
|
||||
## Offene Fragen
|
||||
- ?
|
||||
- ?
|
||||
- ?
|
||||
|
||||
---
|
||||
|
||||
## Verdichtungsansatz (Evergreen-Kandidat)
|
||||
Welches strukturelle Prinzip könnte hier sichtbar werden?
|
||||
Ist das spezifisch oder allgemeingültig?
|
||||
@ -0,0 +1,17 @@
|
||||
---
|
||||
created: 2026-02-23
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Meetings]]"
|
||||
type: []
|
||||
date: 2026-02-23
|
||||
org:
|
||||
loc:
|
||||
people:
|
||||
- "[[Stefan Schorer]]"
|
||||
- "[[Alexander Gronbach]]"
|
||||
topics: []
|
||||
---
|
||||
- Rollen in vPeople?
|
||||
22
2026-02-23 General Business Applications Platform.md
Normal file
22
2026-02-23 General Business Applications Platform.md
Normal file
@ -0,0 +1,22 @@
|
||||
---
|
||||
created: 2026-02-23
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Projects]]"
|
||||
type:
|
||||
- "[[Platform]]"
|
||||
org:
|
||||
- "[[Vector]]"
|
||||
start: 2026-02-23
|
||||
year: 2026
|
||||
url:
|
||||
status: "[[Planned]]"
|
||||
---
|
||||
|
||||
We want to establish a simple, low maintenance platform to allow vector employees to host their small little applications. Things we want to consider:
|
||||
- Authentication/Authorisation is part of the platform
|
||||
- Deployment and Maintenance should be a self service (if possible)
|
||||
|
||||
Siehe [[2026-02-17 0953 Abstimmung mit Klaus]]
|
||||
9
2026-02-24 0750 SNDS Delete Fehler beheben.md
Normal file
9
2026-02-24 0750 SNDS Delete Fehler beheben.md
Normal file
@ -0,0 +1,9 @@
|
||||
---
|
||||
created: 2026-02-24
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
- Musste erstmal den DevContainer wieder aufbereiten, damit ich da arbeiten kann
|
||||
- Das Projekt baut leider noch nicht
|
||||
-
|
||||
24
2026-02-24 1003 Vorstellung des AI-Code-Reviewers.md
Normal file
24
2026-02-24 1003 Vorstellung des AI-Code-Reviewers.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
created: 2026-02-24
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Meetings]]"
|
||||
type:
|
||||
- "[[Vorstellung]]"
|
||||
date: 2026-02-24
|
||||
org:
|
||||
- "[[Vector]]"
|
||||
loc:
|
||||
people:
|
||||
- "[[Jan Felix Röhrle]]"
|
||||
- "[[Jens Rochau]]"
|
||||
- "[[Klaus Bergdolt]]"
|
||||
- "[[Pavel Parfuntseu]]"
|
||||
- "[[Pascal Brostean]]"
|
||||
topics:
|
||||
- Vorstellung des AI-Code-Reviewers
|
||||
---
|
||||
- Verbesserungsvorschläge eingebaut
|
||||
- Unklar, wer abgestimmt hat, in welchen Projekten dies bereits implementiert werden soll
|
||||
6
2026-02-24 1132 Rollendatenbank.md
Normal file
6
2026-02-24 1132 Rollendatenbank.md
Normal file
@ -0,0 +1,6 @@
|
||||
---
|
||||
created: 2026-02-24
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
---
|
||||
9
Alena.md
Normal file
9
Alena.md
Normal file
@ -0,0 +1,9 @@
|
||||
---
|
||||
categories:
|
||||
- "[[People]]"
|
||||
tags:
|
||||
- people
|
||||
birthday:
|
||||
created: 2026-01-09
|
||||
company: Vector Informatik GmbH
|
||||
---
|
||||
76
Alessio Gallucci.md
Normal file
76
Alessio Gallucci.md
Normal file
@ -0,0 +1,76 @@
|
||||
---
|
||||
tags:
|
||||
- person
|
||||
company: Luminovo GmbH
|
||||
location: München
|
||||
title:
|
||||
email:
|
||||
- alessio.gallucci@luminovo.ai
|
||||
date_last_spoken: 2023-08-15
|
||||
categories:
|
||||
- "[[People]]"
|
||||
---
|
||||
# Alessio Gallucci
|
||||
![[Bildschirmfoto_2020-09-20_um_14.47.54.png|200]]
|
||||
## Agenda
|
||||
|
||||
### How we met
|
||||
|
||||
### History
|
||||
|
||||
### Family
|
||||
|
||||
### Hobbies
|
||||
|
||||
- Ukulele
|
||||
- Music
|
||||
- Coffee
|
||||
- Meditation
|
||||
- Badminton
|
||||
|
||||
Requested recipe: [[Classic Focaccia]]
|
||||
|
||||
### Bio in Notion
|
||||
|
||||
I grew up in a small town in the middle of Italy and when I was 18, I decided to move to Germany to study Psychology - and eventually become a new italian version of Sigmund Freud. _(Me not liking cigars was only the first hint that this vision was doomed to fail)_.
|
||||
|
||||
During my Bachelor's in Münster, I started questioning whether being a psychotherapist would be the right path for me. After various internships in quantitative research, HR and psychotherapy I moved to Munich to join the Amazon EU recruitment team and started my Master's in Industrial & Organizational Psychology at LMU. I kept working in the talent management space at Amazon and later in a People Analytics start-up, where I discovered my interest in UX. I then joined NavVis as a UX-Design working student, where I had the chance to professionalize my self-taught design skills, working on the development of two hardware products and a mobile app.
|
||||
|
||||
While I enjoy both Research & Design, I am mostly interested in the process bridging the two phases and in how to use Psychology to deliver products that are pleasing and user-centered.
|
||||
|
||||
## Ask Me About
|
||||
|
||||
- Figma and UI Design
|
||||
- My obsession for the italian indie band [i Cani](https://www.youtube.com/watch?v=ulZMdQyhfWQ)
|
||||
- Design magazines and graphic novels
|
||||
- Great illustrators and data visualizers as Ilya Milstein, Christoph Nieman & Giorgia Lupi
|
||||
- How great John Oliver actually is
|
||||
|
||||
# Role & Performance Objectives
|
||||
|
||||
**Sourcing Designer**
|
||||
|
||||
- Nailing the Sourcing problem space together with our PM and domain experts before moving to brainstorming and shaping solutions for our users.
|
||||
- Leading the design and creation of new prototypes (ranging from low-fidelity sketches to high-fidelity Figma prototypes) and finding creative solutions to make our UI look great without compromising technical feasibility and consistency with the rest of the app.
|
||||
- Reducing the value and usability risk of our product together with our PM and engineers by user-testing new and existing features with our customers.
|
||||
- Anticipating the needs of our Frontend Engineers with detailed specifications and handoffs to reduce their guesswork.
|
||||
|
||||
**Design MGMT**
|
||||
|
||||
- Create and maintain an onboarding plan for new Designers, making their transition as new DPD @ Luminovo as frictionless as possible.
|
||||
- Ensuring the growth of our Junior Designers, mentoring them to further develop their Design skills as well as helping them finding and growing their own area of expertise.
|
||||
- Proactively support the People team in attracting and assessing design talent for Luminovo.
|
||||
|
||||
**Design lead**
|
||||
|
||||
- Build and maintain a Figma environment that is scalable and addresses the needs of our internal user groups (designers, engineers, PMs)
|
||||
- Create and maintain processes that ensure alignment and consistency of design across all the product teams.
|
||||
- Lead the continuous expansion of our design system based on the feedback and requests from our designers, and facilitate the transition to its digital twin in the Frontend.
|
||||
|
||||
# Working with me
|
||||
|
||||
- I really enjoy working in close collaboration and in quick iterations. So rather than presenting the whole bunch of work just at the end of the sprint, I prefer doing quick check-ins with developers during the process, so that both sides are aligned and flaws in the design or in the concept can be spotted early.
|
||||
- I am really interested in understanding the technology behind the product, so please don't spare me with details about it! In case the conversation would get too technical for me I might ask you to "translate" it in a more accessible language.
|
||||
- Sometimes you don't need actual customers to validate some design assumptions and your colleagues can become great test users. I will probably ask you here and then to test my prototypes and to give me your unfiltered feedback - no matter in which team you are. While a diverse testing pool is better, I understand that some people are very motivated to do it, some less. Please let me know in which section of this spectrum you are so that I can use my test requests wisely ;)
|
||||
- I personally tend to prefer direct pings over emails for internal communication. I am also a big fan of short calls (or conversations if we both are in the office) especially when we need to explain or clarify something.
|
||||
- For work-related topics please use one of the _official_ channels, for private topics feel free to reach out to me per WhatsApp!
|
||||
9
Alte Vault Informationen übertragen.md
Normal file
9
Alte Vault Informationen übertragen.md
Normal file
@ -0,0 +1,9 @@
|
||||
---
|
||||
created: 2026-02-17
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Tasks]]"
|
||||
stat: true
|
||||
---
|
||||
28
Andreas Fogados.md
Normal file
28
Andreas Fogados.md
Normal file
@ -0,0 +1,28 @@
|
||||
---
|
||||
tags:
|
||||
- person
|
||||
company: Vector Informatik GmbH
|
||||
location: Regensburg
|
||||
email:
|
||||
date_last_spoken: 2023-08-09
|
||||
categories:
|
||||
- "[[People]]"
|
||||
---
|
||||
# Andreas Fogados
|
||||
|
||||
![[Screenshot_20230705-112223.png|200]]
|
||||
|
||||
## Agenda
|
||||
|
||||
### How we met
|
||||
|
||||
We both worked at Timing Architects back then in 2018. Then TA got acquired by Vector Informatik GmbH where we both transitioned.
|
||||
|
||||
### History
|
||||
|
||||
24.10.2023: hat meinen Geburtstag 4 Tage!!! vergessen
|
||||
|
||||
### Family
|
||||
|
||||
> [!SUMMARY]
|
||||
> Content
|
||||
22
Andreas Schindlbeck.md
Normal file
22
Andreas Schindlbeck.md
Normal file
@ -0,0 +1,22 @@
|
||||
---
|
||||
tags:
|
||||
- person
|
||||
company: Vector Informatik GmbH
|
||||
location: Regensburg
|
||||
title:
|
||||
email:
|
||||
date_last_spoken: 2023-08-09
|
||||
categories:
|
||||
- "[[People]]"
|
||||
---
|
||||
# Andreas Schindlbeck
|
||||
![[Screenshot_20230705-112919.png|200]]
|
||||
## Agenda
|
||||
|
||||
### How we met
|
||||
|
||||
We both worked at Timing Architects back then in 2018. Then TA got acquired by Vector Informatik GmbH where we both transitioned.
|
||||
|
||||
### History
|
||||
|
||||
### Family
|
||||
@ -0,0 +1,8 @@
|
||||
---
|
||||
created: 2026-02-17
|
||||
jira: https://jira.vi.vector.int/browse/VTR-4193
|
||||
categories:
|
||||
- "[[Jira Tickets]]"
|
||||
---
|
||||
|
||||
|
||||
6
Archive/Emails durcharbeiten.md
Normal file
6
Archive/Emails durcharbeiten.md
Normal file
@ -0,0 +1,6 @@
|
||||
---
|
||||
categories:
|
||||
- "[[Tasks]]"
|
||||
stat: true
|
||||
created: 2026-02-16
|
||||
---
|
||||
10
Archive/Reisekostenabrechnung Stuttgart Januar.md
Normal file
10
Archive/Reisekostenabrechnung Stuttgart Januar.md
Normal file
@ -0,0 +1,10 @@
|
||||
---
|
||||
created: 2026-02-16
|
||||
tags:
|
||||
- note
|
||||
- journal
|
||||
categories:
|
||||
- "[[Tasks]]"
|
||||
stat: true
|
||||
---
|
||||
~~Ich muss noch einen Beleg einreichen, damit ich das abschicken kann.~~
|
||||
7
Archive/SystemDemo anschauen.md
Normal file
7
Archive/SystemDemo anschauen.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
categories:
|
||||
- "[[Tasks]]"
|
||||
stat: true
|
||||
created: 2026-02-16
|
||||
---
|
||||
**Fazit**: Mir gefiel die SystemDemo. Wir haben allerdings zu lange gebraucht (vorallem der konkrete Vorstellungstermin - also die Dashboards sowie die Data Products) weswegen CAT3 nicht vorgestellt werden konnte.
|
||||
BIN
Attachments/Pasted image 20240710153551.png
Normal file
BIN
Attachments/Pasted image 20240710153551.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 195 KiB |
BIN
Attachments/RMS Requirements CAT3 - Planung.pdf
Normal file
BIN
Attachments/RMS Requirements CAT3 - Planung.pdf
Normal file
Binary file not shown.
@ -0,0 +1,6 @@
|
||||
---
|
||||
created: 2026-02-17
|
||||
jira: https://jira.vi.vector.int/browse/VTR-4041
|
||||
categories:
|
||||
- "[[Jira Tickets]]"
|
||||
---
|
||||
17
Big Picture Sync - Service.md
Normal file
17
Big Picture Sync - Service.md
Normal file
@ -0,0 +1,17 @@
|
||||
---
|
||||
project: "[[OldVault/System/Archive/Templates/Bases/RMS|RMS]]"
|
||||
---
|
||||
# Sync Service
|
||||
|
||||
## How
|
||||
|
||||
The Trigger of VTime always recreates the complete absences for a specific year of a specific employee, and two solving strategies can be employed:
|
||||
|
||||
1. Recreating the Big Picture Absences for a year for an employee.
|
||||
1. It's important to note that this approach may remove manual entries on Big Picture.
|
||||
2. Calculating the difference between the current state and the state at the moment, and then adjusting only the differences
|
||||
1. It's worth noting that VTime does not allow shifting elements, so this method always involves both a removal and an addition operation. Therefore, the update endpoint is not used in any case (at least for VTime).
|
||||
|
||||
## Where
|
||||
|
||||
The update trigger mechanism is currently located in RMS and will be done periodically. From a technical point of view it would make sense to split out this service from RMS and run it independently. But its also possible that RMS will sync periodically.
|
||||
25
BigPicture replacement VF Réunion.md
Normal file
25
BigPicture replacement VF Réunion.md
Normal file
@ -0,0 +1,25 @@
|
||||
---
|
||||
categories:
|
||||
- "[[Meetings]]"
|
||||
type:
|
||||
- "[[Abstimmung]]"
|
||||
date: 2026-01-09
|
||||
org:
|
||||
- "[[Vector]]"
|
||||
loc:
|
||||
people:
|
||||
- "[[Klaus Bergdolt]]"
|
||||
topics:
|
||||
- "[[Gantt France]]"
|
||||
---
|
||||
Félicien presents the application he created for replacement
|
||||
|
||||
`pes-vf-gantt`
|
||||
Nodejs, React
|
||||
Electron app just for executing locally
|
||||
Relies on Personal Access Token
|
||||
|
||||
Daily Basis is fine
|
||||
|
||||
No authentication
|
||||
|
||||
47
Bootstrap for Worker.md
Normal file
47
Bootstrap for Worker.md
Normal file
@ -0,0 +1,47 @@
|
||||
---
|
||||
project: "[[NVRam Endurance Simulation]]"
|
||||
---
|
||||
# Throw Bootstrap for Worker
|
||||
|
||||
- Der Bootstrap für den [[Worker]] ist unabhängig von der TeamArea und grundsätzlich auch unabhängig von der Pod Anzahl. Jedoch gibt es verschiedene TeamArea's mit unterschiedlichen Datenbanken. Damit in jeder Datenbank die FeeVersion/Varianten eingetragen werden müssen alle TeamAreas eine Message zum [[Worker]] senden und alle beantwortet werden.
|
||||
## Sequencediagram
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
autonumber
|
||||
participant TAO
|
||||
participant NES App
|
||||
participant Worker
|
||||
participant TeamAreaDB
|
||||
TAO ->> NES App: Bootstrap (per TeamArea)
|
||||
NES App ->> Worker: Bootstrap (per TeamArea)
|
||||
Worker ->> NES App: FeeVariants/Versions (per TeamArea)
|
||||
NES App ->> TeamAreaDB: save the possible variants and versions
|
||||
```
|
||||
|
||||
```mermaid
|
||||
flowchart TB
|
||||
|
||||
TAO[TAO]
|
||||
NES[NES App]
|
||||
Worker[Worker]
|
||||
Simulator[Simulator]
|
||||
Migrate[Migrate DB if necessary]
|
||||
Save[Save FEE Versions/Variants for TeamArea]
|
||||
|
||||
%% 1) Bootstrap
|
||||
TAO -->|1 Bootstrap| NES
|
||||
TAO -->|1 Bootstrap| Worker
|
||||
|
||||
%% 2) Get FEE Versions/Variants
|
||||
Worker -->|2 Get FEE Versions/Variants| Simulator
|
||||
Simulator --> Worker
|
||||
|
||||
%% 3) Send FEE Versions/Variants
|
||||
Worker -->|3 Send FEE Versions/Variants| NES
|
||||
|
||||
%% NES internal handling
|
||||
NES --> Migrate
|
||||
NES --> Save
|
||||
|
||||
```
|
||||
6
Buildprozess für RMS Frontend.md
Normal file
6
Buildprozess für RMS Frontend.md
Normal file
@ -0,0 +1,6 @@
|
||||
---
|
||||
tags:
|
||||
project: "[[RMS]]"
|
||||
---
|
||||
1. Baue Frontend-Code via `npm install && npm run build:image`
|
||||
2. Kopiere gebautest Frontend in src/main/resources/static
|
||||
410
CAT 3 Planung.canvas
Normal file
410
CAT 3 Planung.canvas
Normal file
@ -0,0 +1,410 @@
|
||||
{
|
||||
"edges":[
|
||||
{
|
||||
"id":"cf430fa161bfb82d",
|
||||
"styleAttributes":{},
|
||||
"fromNode":"9351af2976d6c405",
|
||||
"fromSide":"right",
|
||||
"toNode":"c30777fe43e137ef",
|
||||
"toSide":"left",
|
||||
"label":"Kann in IST Zustand überführt werden"
|
||||
},
|
||||
{"id":"099e15520a6108aa","fromNode":"3caa05d9527eab67","fromSide":"right","toNode":"62ac87df2e43ad8a","toSide":"left"},
|
||||
{"id":"7dbdcdef15ca9858","fromNode":"62ac87df2e43ad8a","fromSide":"right","toNode":"89240df246190a0b","toSide":"left"},
|
||||
{"id":"936e20afba84cb54","fromNode":"89240df246190a0b","fromSide":"right","toNode":"138cdf4ceb067ee7","toSide":"left"},
|
||||
{"id":"71924660e4d0e47b","fromNode":"138cdf4ceb067ee7","fromSide":"bottom","toNode":"0184ca0c110e9083","toSide":"top"},
|
||||
{"id":"47bf2ceb90eb84c9","fromNode":"0184ca0c110e9083","fromSide":"left","toNode":"71556076a25055bb","toSide":"right"},
|
||||
{"id":"208e22c9395b0e15","fromNode":"a1b5ca020ff28939","fromSide":"right","toNode":"fec3707fc6a2c5dc","toSide":"left"},
|
||||
{"id":"e025abab48f03a4f","fromNode":"fec3707fc6a2c5dc","fromSide":"right","toNode":"137922cc410cb12e","toSide":"left"},
|
||||
{"id":"12cbffe0b5e9591a","fromNode":"137922cc410cb12e","fromSide":"right","toNode":"91491a1a601bb714","toSide":"left"},
|
||||
{"id":"9341c37fbc72a50c","fromNode":"91491a1a601bb714","fromSide":"bottom","toNode":"de895e885f5f4a49","toSide":"right"},
|
||||
{"id":"cbce371c17c9c67d","fromNode":"de895e885f5f4a49","fromSide":"left","toNode":"2a6ed75012510a04","toSide":"right"},
|
||||
{"id":"a5c64978ffec71d6","fromNode":"716906ca86fee779","fromSide":"right","toNode":"a532cce70788089c","toSide":"left"},
|
||||
{"id":"bf457524e80bf966","fromNode":"a532cce70788089c","fromSide":"right","toNode":"7abb030a7ff65f23","toSide":"left"},
|
||||
{
|
||||
"id":"93140deb6c963078",
|
||||
"styleAttributes":{"pathfindingMethod":"a-star"},
|
||||
"toFloating":false,
|
||||
"fromFloating":false,
|
||||
"fromNode":"47b28fe3ea426b3b",
|
||||
"fromSide":"right",
|
||||
"toNode":"4bb3ec8da0df59ab",
|
||||
"toSide":"left",
|
||||
"label":"new PreSales Project"
|
||||
},
|
||||
{
|
||||
"id":"7507ad7acf67141f",
|
||||
"styleAttributes":{"pathfindingMethod":"a-star"},
|
||||
"toFloating":false,
|
||||
"fromNode":"4bb3ec8da0df59ab",
|
||||
"fromSide":"bottom",
|
||||
"toNode":"d499fead28fe59b5",
|
||||
"toSide":"top"
|
||||
},
|
||||
{
|
||||
"id":"755557d6101653e9",
|
||||
"styleAttributes":{"pathfindingMethod":"a-star"},
|
||||
"toFloating":false,
|
||||
"fromNode":"d499fead28fe59b5",
|
||||
"fromSide":"bottom",
|
||||
"toNode":"db8f7ad4d9c89986",
|
||||
"toSide":"top"
|
||||
},
|
||||
{
|
||||
"id":"43c73391b1eb9d28",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"e4977353c95d90ba",
|
||||
"fromSide":"right",
|
||||
"toNode":"8f1b5dddef3bad52",
|
||||
"toSide":"left",
|
||||
"label":"Transfer to RMS"
|
||||
},
|
||||
{
|
||||
"id":"955aaa90d88bdd7c",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"8f1b5dddef3bad52",
|
||||
"fromSide":"right",
|
||||
"toNode":"29d234df73d2d4f0",
|
||||
"toSide":"left"
|
||||
},
|
||||
{
|
||||
"id":"0868f0a1e2f11e76",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"29d234df73d2d4f0",
|
||||
"fromSide":"bottom",
|
||||
"toNode":"081a58d1044d9e2b",
|
||||
"toSide":"top"
|
||||
},
|
||||
{
|
||||
"id":"22d01d79e894cc70",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"081a58d1044d9e2b",
|
||||
"fromSide":"bottom",
|
||||
"toNode":"7a9cecd0cc6a42d2",
|
||||
"toSide":"top"
|
||||
},
|
||||
{
|
||||
"id":"6e618fd4a693aaa7",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"081a58d1044d9e2b",
|
||||
"fromSide":"left",
|
||||
"toNode":"f05f0dd182c78deb",
|
||||
"toSide":"right"
|
||||
},
|
||||
{
|
||||
"id":"bf5089689a2073cf",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"0d1b8ee791651c8b",
|
||||
"fromSide":"bottom",
|
||||
"toNode":"6ec4267822e3aa49",
|
||||
"toSide":"top"
|
||||
},
|
||||
{
|
||||
"id":"b13e56131af91a0f",
|
||||
"styleAttributes":{},
|
||||
"toFloating":false,
|
||||
"fromNode":"779314259e9ebd14",
|
||||
"fromSide":"bottom",
|
||||
"toNode":"2eee6afef452b045",
|
||||
"toSide":"top"
|
||||
}
|
||||
],
|
||||
"metadata":{
|
||||
"frontmatter":{"project":"RMS"},
|
||||
"version":"1.0-1.0"
|
||||
},
|
||||
"nodes":[
|
||||
{
|
||||
"id":"9351af2976d6c405",
|
||||
"styleAttributes":{},
|
||||
"text":"SOLL (CAT 3)\n\n- Projektplanung unabhängig von IST Zustand\n- Definiert Rollen\n- Definiert Resourcen in Form von Rollen\n- Definiert Phasen mit Start und End",
|
||||
"type":"text",
|
||||
"x":-900,
|
||||
"y":-620,
|
||||
"width":340,
|
||||
"height":320
|
||||
},
|
||||
{
|
||||
"id":"c30777fe43e137ef",
|
||||
"styleAttributes":{},
|
||||
"text":"IST",
|
||||
"type":"text",
|
||||
"x":420,
|
||||
"y":-620,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"cf32211e348dba83",
|
||||
"styleAttributes":{},
|
||||
"text":"Ziel: Übersicht der notwendigen Rollen erlangen verteilt über Kalenderwochen",
|
||||
"type":"text",
|
||||
"x":-900,
|
||||
"y":-220,
|
||||
"width":340,
|
||||
"height":260
|
||||
},
|
||||
{"id":"2322038a036694bf","text":"Möglichkeit 1: Zuordnung der Mitarbeiter in CAT3 Capaplan","type":"text","x":380,"y":-460,"width":380,"height":100},
|
||||
{"id":"3caa05d9527eab67","text":"CAT3 Capaplan","type":"text","x":445,"y":-300,"width":250,"height":60},
|
||||
{"id":"62ac87df2e43ad8a","text":"Rechtsklick auf Resource -> Assign...","type":"text","x":880,"y":-300,"width":320,"height":60},
|
||||
{"id":"89240df246190a0b","text":"Übertrage Start, End, Role an RMS","type":"text","x":1294,"y":-300,"width":250,"height":60},
|
||||
{"id":"138cdf4ceb067ee7","text":"Zeige mögliche Mitarbeiter und deren freie Resourcen","type":"text","x":1660,"y":-319,"width":250,"height":98},
|
||||
{"file":"Attachments/Pasted image 20250509092629.png","id":"0184ca0c110e9083","type":"file","x":1800,"y":-160,"width":400,"height":285},
|
||||
{"id":"a569f79080d5bb77","text":"Möglichkeit 2: Zuordnung der Mitarbeiter in RMS","type":"text","x":380,"y":180,"width":380,"height":100},
|
||||
{"id":"a1b5ca020ff28939","text":"Zeige Projektauswahl in RMS (via fest definiertem Repo)","type":"text","x":390,"y":340,"width":321,"height":69},
|
||||
{"id":"fec3707fc6a2c5dc","text":"Wähle Projekt aus und wähle Projektrolle","type":"text","x":915,"y":344,"width":250,"height":60},
|
||||
{"id":"137922cc410cb12e","text":"Zeige mögliche Mitarbeiter und deren freie Resourcen","type":"text","x":1360,"y":325,"width":250,"height":98},
|
||||
{"file":"Attachments/Pasted image 20250509092629.png","id":"91491a1a601bb714","type":"file","x":1785,"y":325,"width":400,"height":285},
|
||||
{"id":"71556076a25055bb","text":"Drag and Drop der Kandidaten um die FTE zu erfüllen\n\n==Frage: ist ein FTE 80% eines 40 Stunden Tages? Sprich sprechen wir immer von 32 Stunden im Zusammenhang von einem FTE?==","type":"text","x":1335,"y":-140,"width":300,"height":246},
|
||||
{"id":"de895e885f5f4a49","text":"Drag and Drop der Kandidaten um die FTE zu erfüllen\n\n==Frage: ist ein FTE 80% eines 40 Stunden Tages? Sprich sprechen wir immer von 32 Stunden im Zusammenhang von einem FTE?==","type":"text","x":1335,"y":580,"width":300,"height":246},
|
||||
{"id":"2a6ed75012510a04","text":"Überführung der Zuweisung in Mitgliedschaften\n\nNicht erfüllte FTE mit generischem User füllen","type":"text","x":921,"y":610,"width":250,"height":183},
|
||||
{"id":"548016107285ef77","text":"Merke die ID der TaskData um erneute Operation wiederherstellen zu können -> Ermöglicht die Zuweisung zu ändern","type":"text","x":635,"y":613,"width":250,"height":180},
|
||||
{"id":"d48c1cb2e3d1adb6","text":"Prozente für Mitarbeiter eher suboptimal - Umrechung auf Stunden vermutlich besser (auch wenn wir intern mit Prozenten abgeleitet von der Vertragsarbeitszeit rechnen)","type":"text","x":2260,"y":125,"width":250,"height":224},
|
||||
{"file":"Vector/CAT3.md","id":"fa0f0d02f31454ca","subpath":"#Dinge die als Vorbedingung notwendig sind","type":"file","x":1710,"y":-620,"width":400,"height":200},
|
||||
{"id":"22625858fea5c871","text":"Überführung der Zuweisung in Mitgliedschaften via RMS\n\nNicht erfüllte FTE mit generischem User füllen","type":"text","x":380,"y":-98,"width":250,"height":161},
|
||||
{"id":"6612873f68590aeb","text":"Merke die ID der TaskData um erneute Operation wiederherstellen zu können -> Ermöglicht die Zuweisung zu ändern","type":"text","x":95,"y":-98,"width":250,"height":180},
|
||||
{"id":"81ed4a4231363374","text":"Erstelle Request (via Jira)","type":"text","x":1000,"y":-140,"width":250,"height":60},
|
||||
{"id":"a532cce70788089c","text":"Wähle Projekt aus und wähle Projektrolle","type":"text","x":825,"y":1084,"width":250,"height":60},
|
||||
{"id":"7abb030a7ff65f23","text":"Übertrag nach RMS\n\nMit generischen Usern\n\nErstelle Secondary Orga (falls nicht existent)","type":"text","x":1335,"y":1060,"width":250,"height":180},
|
||||
{"id":"d2eed5c0bd5e2345","text":"40 Stunden sind 1 FTE - Beibehalten","type":"text","x":1715,"y":811,"width":250,"height":60},
|
||||
{"id":"bf9dbc18e4953be0","text":"---\n\n---\ntags: RMS","type":"text","x":-802,"y":-765,"width":250,"height":60},
|
||||
{"id":"716906ca86fee779","text":"Zeige Projektauswahl in RMS (via fest definiertem Repo)","type":"text","x":360,"y":1080,"width":321,"height":69},
|
||||
{
|
||||
"id":"47b28fe3ea426b3b",
|
||||
"type":"text",
|
||||
"text":"Übertragung der Capaplan Informationen nach RMS",
|
||||
"styleAttributes":{},
|
||||
"x":-700,
|
||||
"y":1560,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"d499fead28fe59b5",
|
||||
"type":"text",
|
||||
"text":"Add unnamed employees for the roles.\n\n- The unnamed role should have a full FTE contract. The utilization should be the count of the FTE of the role * 100 (a 1.5 FTE role will end up as a utilization 150%)\n- The naming scheme: projectname_rolename",
|
||||
"styleAttributes":{},
|
||||
"x":-160,
|
||||
"y":1680,
|
||||
"width":260,
|
||||
"height":380
|
||||
},
|
||||
{
|
||||
"id":"4bb3ec8da0df59ab",
|
||||
"type":"text",
|
||||
"text":"Create new secondary Organization",
|
||||
"styleAttributes":{},
|
||||
"x":-160,
|
||||
"y":1560,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"db8f7ad4d9c89986",
|
||||
"type":"text",
|
||||
"text":"Create Resource Requests for each unnamed employee",
|
||||
"styleAttributes":{},
|
||||
"x":-160,
|
||||
"y":2120,
|
||||
"width":260,
|
||||
"height":100
|
||||
},
|
||||
{
|
||||
"id":"6d3b934c99e61ce9",
|
||||
"type":"text",
|
||||
"text":"Check if ",
|
||||
"styleAttributes":{},
|
||||
"x":-380,
|
||||
"y":1220,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"29d234df73d2d4f0",
|
||||
"type":"text",
|
||||
"text":"Create/Modify Project",
|
||||
"styleAttributes":{},
|
||||
"x":2245,
|
||||
"y":1710,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"9cc1cc8c907deefd",
|
||||
"type":"text",
|
||||
"text":"Projektleiter",
|
||||
"styleAttributes":{"shape":"pill"},
|
||||
"x":1605,
|
||||
"y":1750,
|
||||
"width":180,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"8f1b5dddef3bad52",
|
||||
"type":"text",
|
||||
"text":"RMS",
|
||||
"styleAttributes":{},
|
||||
"x":1825,
|
||||
"y":1850,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"081a58d1044d9e2b",
|
||||
"type":"text",
|
||||
"text":"Complete Resource Aquisition",
|
||||
"styleAttributes":{},
|
||||
"x":2245,
|
||||
"y":1880,
|
||||
"width":260,
|
||||
"height":100
|
||||
},
|
||||
{
|
||||
"id":"7a9cecd0cc6a42d2",
|
||||
"type":"text",
|
||||
"text":"Start Project",
|
||||
"styleAttributes":{},
|
||||
"x":2245,
|
||||
"y":2070,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"972d023c5576db6f",
|
||||
"type":"text",
|
||||
"text":"Teamleiter",
|
||||
"styleAttributes":{"shape":"pill"},
|
||||
"x":2185,
|
||||
"y":1810,
|
||||
"width":180,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"e4977353c95d90ba",
|
||||
"type":"text",
|
||||
"text":"CAT 3 Capaplan",
|
||||
"styleAttributes":{},
|
||||
"x":1325,
|
||||
"y":1850,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{"id":"0654c5da846b35e2","type":"file","file":"Vector/drawio_20251112105136.drawio.svg","x":2529,"y":1500,"width":711,"height":270},
|
||||
{
|
||||
"id":"f05f0dd182c78deb",
|
||||
"type":"text",
|
||||
"text":"Noch keine Resource Aquisition Automation",
|
||||
"styleAttributes":{},
|
||||
"x":1760,
|
||||
"y":2120,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"0d1b8ee791651c8b",
|
||||
"type":"text",
|
||||
"text":"Änderung in RMS",
|
||||
"styleAttributes":{},
|
||||
"x":1520,
|
||||
"y":2580,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"6ec4267822e3aa49",
|
||||
"type":"text",
|
||||
"text":"Sync nach CapaPlan",
|
||||
"styleAttributes":{},
|
||||
"x":1520,
|
||||
"y":2740,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"779314259e9ebd14",
|
||||
"type":"text",
|
||||
"text":"Änderung in CapaPlan CAT3",
|
||||
"styleAttributes":{},
|
||||
"x":1825,
|
||||
"y":2580,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"2eee6afef452b045",
|
||||
"type":"text",
|
||||
"text":"Sync nach RMS",
|
||||
"styleAttributes":{},
|
||||
"x":1825,
|
||||
"y":2740,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"f9ae8711dc5a33eb",
|
||||
"type":"text",
|
||||
"text":"Schleife",
|
||||
"styleAttributes":{},
|
||||
"x":1300,
|
||||
"y":2480,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"5228cf0ad295553a",
|
||||
"type":"text",
|
||||
"text":"Angebotsphase",
|
||||
"styleAttributes":{},
|
||||
"x":700,
|
||||
"y":3000,
|
||||
"width":1000,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"056e6d43a32a690f",
|
||||
"type":"text",
|
||||
"text":"Bestellt / Start",
|
||||
"styleAttributes":{},
|
||||
"x":1700,
|
||||
"y":3000,
|
||||
"width":1000,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"70a3633e6094b443",
|
||||
"type":"text",
|
||||
"text":"Erstelle Secondary Organization",
|
||||
"styleAttributes":{},
|
||||
"x":1700,
|
||||
"y":3080,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"863a065b68dbf65b",
|
||||
"type":"text",
|
||||
"text":"Plane Rollen und FTE sowie Start und End",
|
||||
"styleAttributes":{},
|
||||
"x":700,
|
||||
"y":3080,
|
||||
"width":260,
|
||||
"height":60
|
||||
},
|
||||
{
|
||||
"id":"588797752c77ef07",
|
||||
"type":"text",
|
||||
"text":"Virtuelles Assignment\n(CapaPlan oder RMS? offen)",
|
||||
"styleAttributes":{},
|
||||
"x":960,
|
||||
"y":3080,
|
||||
"width":260,
|
||||
"height":60
|
||||
}
|
||||
]
|
||||
}
|
||||
37
CAT3.md
Normal file
37
CAT3.md
Normal file
@ -0,0 +1,37 @@
|
||||
---
|
||||
project: "[[RMS]]"
|
||||
---
|
||||
Die zentrale Fragestellung für CAT3 PreSales Planung: *Sind wir in der Lage Akquise zu betreiben?*
|
||||
Darunter die etwas genauere Fragestellung: *Wer könnte theoretisch die verschiedenen Rollen in dem Projekt übernehmen (ohne den IST-Zustand zu verändern)*
|
||||
|
||||
Die Angebotsphase braucht Rollen (Rollen kommen vom Prozess und können sich theoretisch ändern) für jedes virtuelle Projekt. Die Planungsphase betrachtet die Projekte immer nur einzeln, **keine** Varianten von verschiedenen Zuordnungen der gleichen Projekte.
|
||||
|
||||
Falls ein virtuelles Projekt bestellt wird -> übernahme in den IST-Zustand von RMS (direktes Mapping auf secondary Organization)
|
||||
|
||||
Jeder Employee kann jede Rolle übernehmen (auch wenn das nur theoretisch gilt und nicht so gelebt wird).
|
||||
|
||||
Bedarfsansicht über alle Projekte hinweg, aber auch einzeln (nach Möglichkeit definierbar welche Projekte man aktuell sehen will).
|
||||
|
||||
![[Pasted image 20240710153551.png]]
|
||||
|
||||
![[RMS Requirements CAT3 - Planung.pdf]]
|
||||
|
||||
## CAT3 Requirements
|
||||
|
||||
- Planungsansicht als neuer Reiter
|
||||
- Planungsprojekte können Phasen und Rollen definieren
|
||||
- Rollen sind Freitext Elemente, aber verwendete Rollen sollen im Autocomplete auftauchen
|
||||
- Phasendefinition: man kann mit Startdatum, Anzahl an Phasen und jeder Phase eine Wochendauer beginnen. Lücken erstmal nicht nötig und könnten mit 0 Bedarf auch erstellt werden (workaround)
|
||||
- Jede Phase definiert für jede Rolle einen Bedarf
|
||||
- Wenn die Projektplanung für den Pre-Sales genauer geplant werden solle -> assignment von Mitarbeitern an Rollen in spezifischer Phase
|
||||
- Notwendige Sicht: Rollen-assignments über Phasen und Projekte hinweg. Man könnte sich vorstellen, dafür eine View zu bauen, in der erstmal alle Rollen unbesetzt sind und diese mit einem Klick und dem dazugehörigen Dialog besetzt werden können.
|
||||
|
||||
![[CAT 3 Planung.canvas|CAT 3 Planung]]
|
||||
|
||||
# Dinge die als Vorbedingung notwendig sind:
|
||||
|
||||
Rollen in RMS
|
||||
|
||||
[[Agenda CAT3 RMS]]
|
||||
![[CAT 3 Planung.canvas]]![[drawio_20251112105136.drawio.svg]]
|
||||
[[RMS Capaplan Workshop]]
|
||||
11
Christina Georgieva.md
Normal file
11
Christina Georgieva.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
categories:
|
||||
- "[[People]]"
|
||||
birthday:
|
||||
org:
|
||||
- "[[Vector]]"
|
||||
created: 2026-02-19
|
||||
---
|
||||
## Meetings
|
||||
|
||||
![[Meetings.base#Person]]
|
||||
75
Christine Reichert.md
Normal file
75
Christine Reichert.md
Normal file
@ -0,0 +1,75 @@
|
||||
---
|
||||
tags:
|
||||
- person
|
||||
company: Luminovo GmbH
|
||||
location: Bergisch Gladbach
|
||||
title:
|
||||
email:
|
||||
- christine.reichert@luminovo.ai
|
||||
date_last_spoken: 2023-08-15
|
||||
categories:
|
||||
- "[[People]]"
|
||||
---
|
||||
# Christine Reichert
|
||||
|
||||
![[ID-3 (3).jpg|200]]
|
||||
|
||||
## Agenda
|
||||
|
||||
### How we met
|
||||
|
||||
### History
|
||||
|
||||
### Family
|
||||
|
||||
### Hobbies
|
||||
|
||||
- Pilates
|
||||
- Reading
|
||||
- Running
|
||||
- Gardening
|
||||
|
||||
### Bio in Notion
|
||||
|
||||
_A fun management summary of your CV._
|
||||
|
||||
I’m Tine, 32 years old and live in Bergisch Gladbach, in the middle of Rheinland, the home region of Karneval. 🥳
|
||||
|
||||
I grew up in a tiny village (more or less) close to Frankfurt together with 3 older brothers and a sister. I am used to having many people around me and I love that! At the same time, I enjoy some me-time where I read a book, take long walks or try new handicrafts such as knitting or Macramé (even though I’m not very good at it 😄).
|
||||
|
||||
I started my professional path in a Business Travel Agency where I worked for 3 years. I quickly understood that this couldn’t be the “end” for me so I decided to study translation and interpretation in Heidelberg which I called my home for 5 years. During this time I also spent a few months in Paris and London.
|
||||
|
||||
After finishing my Master’s, love led me to Trier where I live with my boyfriend François our two cats Cosmo & Wanda. ❤️
|
||||
|
||||
For the past 4 years I’ve been working in Luxembourg, first as a Translation Project Manager and then as Customer Success Manager. Last year I realised that the financial sector wasn’t a field where I see myself in 20 years. I was looking for other opportunities and wanted to do something I really feel passionate about. That’s when I decided to start my own business as a wedding speaker and last summer, I could already accompany three couples on their big day. ❤️
|
||||
|
||||
When my good friend Flo recommended a dynamic start-up to me I decided to also switch jobs and this is when my Luminovo journey began. 😃
|
||||
|
||||
## Ask Me About
|
||||
|
||||
- Wedding ceremonies 💑
|
||||
- Growing up with 4 siblings and 6 cousins in the flat next door 😄
|
||||
- Studying Conference Interpreting (it does not mean you’re a living dictionary 📖)
|
||||
- How I built my first furniture 🪛🔧
|
||||
|
||||
# Role & Performance Objectives
|
||||
|
||||
_Describe your role and performance objectives. They should explain what excellent performance for your role looks like and what others can (and should!) hold you accountable for. Make sure to coordinate these with your manager._
|
||||
|
||||
# Working with me
|
||||
|
||||
### Availability
|
||||
|
||||
I’m more of an early-bird and will start my work some time between 8 and 8:30 h. I prefer doing demanding tasks early in the day as I am still fresh and full of energy then. If possible, I prefer having meetings before 5 pm but I do realise that this is not always feasible.
|
||||
|
||||
As I will be working remotely it is super important for me to separate my working hours from my free time. Unless there is an urgency I will neither work during the weekends nor will I check my work related messages after my normal working hours. If needed, you can reach my via WhatsApp. 🙂
|
||||
|
||||
### Idiosyncrasies
|
||||
|
||||
I am a perfectionist and when I do something I want to do it right. That being sad, if I need more time to finish a task (especially during my first weeks @Luminovo) this means that I put all my energy in it to be sure that I will meet expectations and requirements. In case you need something from me within a certain time just let me know and I’ll make sure to stick to the deadline.
|
||||
|
||||
### Common failure modes
|
||||
|
||||
I tend to overthink things. I am constantly working on this, but I guess it’s a life-long process. 😉
|
||||
|
||||
When I’m hungry, I need to eat something. FAST. 😄 I can’t concentrate well when I’m hungry.
|
||||
108
Clippings/Getting Things Done with Obsidian.md
Normal file
108
Clippings/Getting Things Done with Obsidian.md
Normal file
@ -0,0 +1,108 @@
|
||||
---
|
||||
title: "Getting Things Done with Obsidian"
|
||||
source: "https://sergesreport.com/PROJECTS/Blog/All+Posts/Getting+Things+Done+with+Obsidian"
|
||||
author:
|
||||
- "[[Serge's Report]]"
|
||||
published:
|
||||
created: 2025-06-07
|
||||
description: "Getting Things Done with Obsidian - Serge's Report"
|
||||
tags:
|
||||
- "clippings"
|
||||
---
|
||||
|
||||
|
||||
PROJECTS/Blog/\_resources/Getting things done with Obsidian/1.png
|
||||
|
||||
Back in 2020, I wrote [this post](https://sergesreport.com/PROJECTS/Blog/All+Posts/My+hi-techlo-tech+hybrid+Information+Management+System+in+2020) about getting things done and managing information with Evernote. In late 2024, I made the decision to switch from [Evernote](https://evernote.com/) to [Obsidian](https://obsidian.md/). Obsidian is a powerful, customizable, and scalable note-taking and information management software. It is perfect as your “second brain” and can be setup with GTD methodology.
|
||||
|
||||
In this post I will discuss the reasons for my move to Obsidian, as well as walk through how I set up my new system. I’m hoping by sharing my setup, it may help someone to become more productive, organized, and free of clutter.
|
||||
|
||||
## Switching from Evernote to Obsidian
|
||||
|
||||
Over the years, as I grew and changed my thinking in some ways, I was getting frustrated with limited customization options in Evernote. At least the level of customization that I needed for my system. Evernote is a good app and works for a lot of people; but I needed more flexibility to set up my system the way I work, not to mold my ways to fit the system.
|
||||
|
||||
I am not the one to chase the latest and greatest tech; for context, I have used the Evernote for 15 years as part of my information management system. It worked well for my needs at the time. But in 2024, I felt it was time to ditch Evernote. I switched to Obsidian for the following reasons:
|
||||
|
||||
1. Evernote’s lack of local data in universal format. In Obsidian, the data is local and belongs to me, in [markdown format.](https://en.wikipedia.org/wiki/Markdown)
|
||||
2. Limited customization options in Evernote. Great customization options in Obsidian.
|
||||
3. Lack of trust in the new company owner of Evernote. Great confidence in the philosophy of Obsidian’s developers.
|
||||
|
||||
In late 2024, I started learning how to use Obsidian and transferred my 5000 notes to Obsidian. Couple of years ago, Evernote got bought out by Bending Spoons, and while the company started making great improvements to the app, it no longer served my needs. Part of the issue for me was the fact that I really didn't own my data. It was in the cloud, managed by the company I didn't trust, in some proprietary format. While I could export my data and convert it, I realized that I'd rather have my data locally. Evernote did not offer that option.
|
||||
|
||||
It took me five months to transfer everything over from Evernote to Obsidian. The transfer wasn’t perfect or easy, but I took my time to clean everything up and setup a perfect system for me. I was not in a rush. Plus I was learning Obsidian as I went, and beware: it does have a steep learning curve, if you want to take full advantage of customization.
|
||||
|
||||
## The hybrid approach to information management
|
||||
|
||||
If you read my 2020 post, you know that I utilize a hybrid analog/digital system for productivity, information management, and getting things done. I did not depart from this architecture in 2025, however I realized that I relied on the analog part of the system (my physical notebook) less than I did before. Perhaps because I really enjoy using Obsidian or maybe because Obsidian is new and exciting for me for now... time will tell. I still carry my physical notebook with me everywhere. It’s always with me.
|
||||
|
||||
> ### “Use your mind to think about things, rather than think of them. You want to be adding value as you think about projects and people, not simply reminding yourself they exist.”
|
||||
|
||||
## My new system engine: Obsidian
|
||||
|
||||
I am still using David Allen’s "Mind Like Water" GTD methodology of capturing, clarifying, organizing, reflecting, and engaging. I have been using it for 20 years now and really like that system. Read about GTD [here](https://gettingthingsdone.com/what-is-gtd/).
|
||||
|
||||
In Obsidian, same as I did in Evernote, I set up for GTD with a sprinkle of The Secret Weapon (TSW) offering, for context tags. The notebooks I have are Inbox, Journal, Projects, Assets, and Filing Cabinet. And speaking of Journal, Obsidian’s Daily Note feature helped me journal consistently, which I was not able to achieve before.
|
||||
|
||||
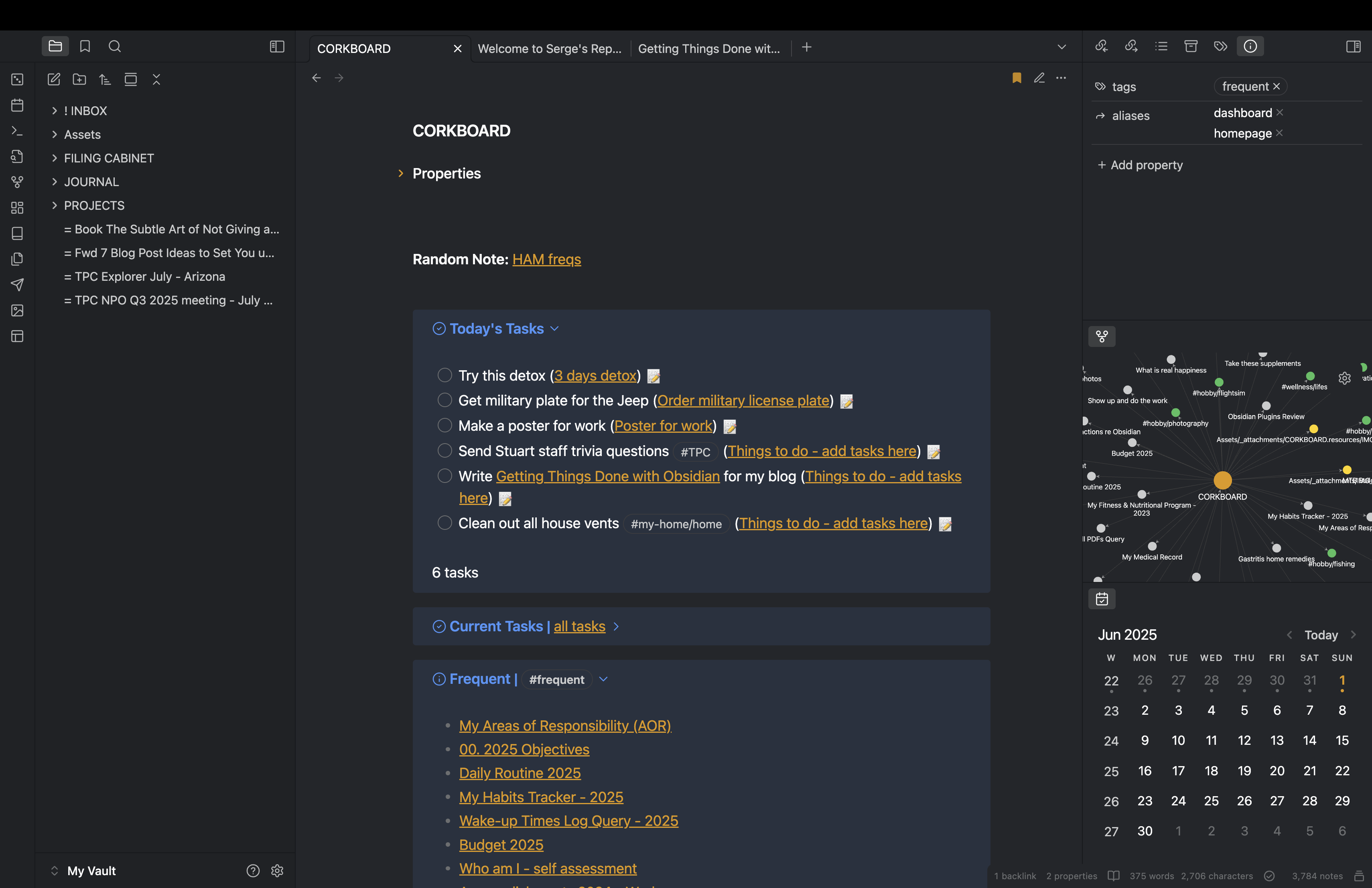
For organization and ability to recall information quickly I utilize DataView (community plugin) queries, and Bookmarks feature. Bookmarks reside in the left sidebar. I also created a homepage I call CORKBOARD, where I put both static and dynamically-generated content (more on that later).
|
||||
|
||||
As far as my GTD inboxes, I still have three primary inboxes: one in Obsidian, one in my physical notebook, and one for my physical mail, receipts, and other physical pieces of paper (needed items there get digitized into Obsidian).
|
||||
|
||||
Since I like to have everything in one place, I run my task management in Obsidian as well. And tasks are an integral part of GTD, of course. I use a community plugin called Tasks, which allows me to keep track of everything I need to get done. I recall tasks via queries to show up in my daily tasks, upcoming tasks, ongoing tasks, and anytime tasks in my CORKBOARD and in a dedicated Tasks space as well.
|
||||
|
||||
Part of GTD process is to review and organize incoming information. I do this via the Weekly Note feature where I do weekly review and organization every Sunday. By using DataView community plugin for Obsidian, pull all the notes I created in a given week, so that I could review them.
|
||||
|
||||
## The Daily Note
|
||||
|
||||
Another great feature in Obsidian is Daily Note. Every morning, part of my routine, I create a daily note where I log the events of the day, journal, recall past journal entries, and track my habits. Speaking of habits, by using Habits Tracker community plugin, I’m able to track and visualize my daily habits. There I track my daily mood, wake-up times, reading, and workouts.
|
||||
|
||||
The Daily Note feature helped me with my journaling as well. It forced me to journal consistently - something I struggled with over the years. In the Journal section of my daily note I have 4 questions:
|
||||
|
||||
1. Who or what am I thankful for?
|
||||
2. What went well today?
|
||||
3. What did I learn?
|
||||
4. What could I improve tomorrow?
|
||||
|
||||
These daily notes live in my Journal folder and I can use queries to aggregate the necessary information from that folder, like my wake-up times or recall my dreams that I log.
|
||||
|
||||
The graph feature in Obsidian provides a visual view of links and connections between all my notes. While I don’t utilize the global graph view, I do use the local graph, as it allows me to view local connections.
|
||||
|
||||
> ### “Writing in your journal gives you a chance to go back over your day and extract meaning from a hurried meeting with a friend or retrieve the significance of some fleeting event.”
|
||||
|
||||
## Home Page
|
||||
|
||||
In order to have quick access to the information I need, I created a home page note in Obsidian. It serves as a hub for my most useful and quick access content. I can access this note quickly from Bookmarks in the sidebar. So far, I added the following sections to the CORKBOARD:
|
||||
|
||||
- Today’s Tasks
|
||||
- Current (ongoing) Tasks
|
||||
- Frequent
|
||||
- Recently Modified
|
||||
- Motivational
|
||||
- Hobbies
|
||||
- Lifestyle
|
||||
- Read/Watch Later
|
||||
- Misc. Info
|
||||
- Scratch Pad
|
||||
|
||||
I check this note multiple times per day to see my tasks and to reference information within my system. I built this note using the callouts feature, keeping everything neat and organized.
|
||||
|
||||
## Other Features
|
||||
|
||||
The other two features I love using in Obsidian are Sync and Publish. Sync allows me to synchronize Obsidian across devices, and Publish allows me to publish my blog (which you are reading). Both work well.
|
||||
|
||||
## Closing
|
||||
|
||||
I hope you found this post useful. If you have any questions - [Email Me](https://sergesreport.com/PROJECTS/Blog/All+Posts/)
|
||||
|
||||
My Obsidian-based system allows me to get the information out of my brain and into a trusted system, allowing me to be creative in my thinking, to never forget anything, and to manage my life in a organized and effective way. I hope it can do the same for you!
|
||||
|
||||
|
||||
|
||||
Screenshot 2025-06-01 at 17.46.56.png
|
||||
|
||||

|
||||
|
||||
Screenshot 2025-06-01 at 17.47.44.png
|
||||
|
||||
|
||||
|
||||
Screenshot 2025-06-01 at 17.45.29.png
|
||||
@ -0,0 +1,54 @@
|
||||
---
|
||||
title: "Interstitial journaling: combining notes, to-do and time tracking"
|
||||
source: "https://nesslabs.com/interstitial-journaling"
|
||||
author:
|
||||
- "[[Anne-Laure Le Cunff]]"
|
||||
published: 2020-04-15
|
||||
created: 2025-08-09
|
||||
description: "Interstitial journaling is a productivity technique created by Tony Stubblebine. To my knowledge, it’s the simplest way to combine note-taking, tasks, and time tracking in one unique workflow. You don’t need any special software, but Roam Research makes it even easier to do thanks to the flexibility of daily notes. Interstitial journaling has had an ... Read More"
|
||||
tags:
|
||||
- "clippings"
|
||||
---
|
||||
Interstitial journaling is a productivity technique created by Tony Stubblebine. To my knowledge, it’s the simplest way to combine note-taking, tasks, and time tracking in one unique workflow. You don’t need any special software, but [Roam Research](https://nesslabs.com/roam-research) makes it even easier to do thanks to the flexibility of daily notes. Interstitial journaling has had an amazing impact on my productivity and creativity, and I think many people would enjoy it.
|
||||
|
||||
The basic idea of interstitial journaling is to write a few lines every time you take a break, and to track the exact time you are taking these notes. For instance:
|
||||
|
||||
```
|
||||
10:04 - Going to finish the first draft of the mindful productivity article.
|
||||
10:46 - I fell into a Twitter blackhole again! Back to work.
|
||||
11:45 - Made good progress. Need to get ready for meeting with Charlie.
|
||||
11:49 - Reviewed agenda and docs. Feeling a bit anxious, but I think it will go fine. Need to call Anna after the meeting to debrief.
|
||||
```
|
||||
|
||||
Notice the mix of goals (“finish the first draft”), self-awareness (“fell into a Twitter blackhole”, “feeling anxious”), self-review (“good progress”), and actionable items (“call Anna”)?
|
||||
|
||||
I love interstitial journaling because it’s a great way to make your breaks more mindful.
|
||||
|
||||
- **Proactive breaks:** reflect on your previous task, plan for the next one, take your own mental pulse, jot down anything else that comes to mind so as to reduce your cognitive load.
|
||||
- **Procrastination breaks:** become aware of these breaks and how long they actually take. When you create the habit of writing down all your breaks, it becomes easier to not open a new tab to “quickly” check Twitter. You don’t want to have to admit that failure to yourself.
|
||||
|
||||
Your interstitial journal is not only a journal, it’s a to-do list, a note-taking system, and a way to track your time meaningfully. As I mentioned, you can keep an interstitial journal anywhere. Even a text file would work well.
|
||||
|
||||
If you’re a Roam Research user, let’s see how you can easily set it up there. I’m saying “setting it up”, but really… The work has been done for you already.
|
||||
|
||||
## Keeping an interstitial journal in Roam Research
|
||||
|
||||
In my [beginner’s guide to Roam](https://nesslabs.com/roam-research-beginner-guide), I completely left out the Daily Notes section to keep things simple. Let’s now have a look together. This is what a daily note with interstitial journaling looks like.
|
||||
|
||||

|
||||
|
||||
- **Track time.** Type */time* to insert the current time, then type whatever you are thinking about.
|
||||
- **Track tasks.** Type */todo* to create to-do items. Check off these to-do items when done.
|
||||
- **Track content.** When you stumble upon something interesting that would disturb your workflow, add it to master lists such as \[\[To read\]\]. You can see I have done it in this screenshot with an interesting-looking article that had nothing to do with the essay I was trying to write.
|
||||
- **Track ideas.** Similarly, if you think of something else you’d like to do today, just add it as a to-do where and when you think about it. For people using the \[\[Today\]\], \[\[Tomorrow\]\], \[\[Someday\]\] system, you can also add that to the to-do items, or add a specific date, as I have done with “call Morgane.”
|
||||
- **Track well-being.** I like to start my work day with a quick note checking in on how I feel, anything that’s been sometimes literally keeping me up at night, any major roadblock I’m anticipating for the day. It’s rarely longer than one bullet point, but it’s a great way to take care of my general well-being. I also finish the work day with a similar quick closing note.
|
||||
|
||||
I genuinely feel silly writing out these instructions. It’s an incredibly simple system to make your journal more actionable—or to actually start a journaling practice. As always, it may not be for everyone, but it’s done wonders for me. I still use [Plus Minus Next](https://nesslabs.com/plus-minus-next) journaling for my weekly review, and interstitial journaling makes it even easier to go back to see what went well and what didn’t during your week.
|
||||
|
||||
|
||||
|
||||
## Join 100,000 mindful makers!
|
||||
|
||||
Ness Labs is a weekly newsletter with science-based insights on creativity, mindful productivity, better thinking and lifelong learning.
|
||||
|
||||
One email a week, no spam, ever. See our [Privacy policy](https://nesslabs.com/privacy).
|
||||
290
Clippings/Knockdown English Workbench.md
Normal file
290
Clippings/Knockdown English Workbench.md
Normal file
@ -0,0 +1,290 @@
|
||||
---
|
||||
title: "Knockdown English Workbench"
|
||||
source: "https://www.popularwoodworking.com/article/knockdown-english-workbench/"
|
||||
author:
|
||||
- "[[Christopher Schwarz]]"
|
||||
published: 2020-06-02
|
||||
created: 2025-06-19
|
||||
description: "Many knockdown workbenches suffer from unfortunate compromises. Inexpensive commercial benches that can be knocked down for shipping use skimpy hardware and…"
|
||||
tags:
|
||||
- "clippings"
|
||||
---
|
||||
We may receive a commission when you use our affiliate links. However, this does not impact our recommendations.
|
||||
|
||||
#### With $100 in lumber and two days, you can build this sturdy stowaway bench.
|
||||
|
||||
M any knockdown workbenches suffer from unfortunate compromises.
|
||||
|
||||
Inexpensive commercial benches that can be knocked down for shipping use skimpy hardware and thin components to reduce shipping weight. The result is that the bench never feels sturdy. Plus, assembly usually takes a good hour.
|
||||
|
||||
Custom knockdown benches, on the other hand, are generally sturdier, but they are usually too complex and take considerable time to set up.
|
||||
|
||||
In other words, most knockdown workbenches are designed to be taken apart only when you move your household. When I designed this bench, I took pains to ensure it was as sturdy as a permanent bench, it could be assembled in about 10 minutes and you would need only one tool to do it.
|
||||
|
||||
The design here is an English-style workbench that’s sized for an apartment or small shop at 6′ long. It’s made from construction lumber and uses a basic crochet and holdfasts for workholding. As a result, the lumber bill for this bench is about $100. You’ll need four 2″ x 12″ x 16′ boards and one 1″ x 10″ x 8′ board.
|
||||
|
||||
I used yellow pine for this bench, but any heavy framing lumber will do, including fir, hemlock or even spruce.
|
||||
|
||||
The hardware is another $75. The supplies list notes high-quality hardware from McMaster-Carr; you could easily save money by doing a little shopping or assembling the bench with hardware that is slower to bolt and un-bolt.
|
||||
|
||||
## About the Raw Materials
|
||||
|
||||

|
||||
|
||||
Mounted for work. The ductile mounting plates are easy to install and durable.
|
||||
|
||||
The core of this workbench is ductile iron mounting plates that are threaded to receive cap screws. This hardware is easy to install and robust. The rest of the hardware is standard off-the-rack stuff from any hardware store.
|
||||
|
||||
No matter where you buy your lumber, make sure it has acclimated to your shop before you begin construction. This workbench is made up of flat panels, so having stable wood will make construction easier and will reduce any warping that comes with home-center softwoods.
|
||||
|
||||

|
||||
|
||||
Four legs good. By gluing a short piece and a long piece together, you create a thick leg and the notch for the workbench’s apron.
|
||||
|
||||
When I bring a new load of lumber into my shop, I cut it to rough length and sticker it. I have a moisture meter that tells me when the wood is at equilibrium. If you don’t have a moisture meter, wait a couple of weeks before building the bench. Also, if the end grain of any board feels cooler to the touch than its neighbors, then that board is still wet-ish and giving off moisture. So you might want to give that stick some more time to adjust.
|
||||
|
||||
This workbench is made up of five major assemblies that bolt together: two end pieces, two aprons and a top. Each assembly needs some cutting and gluing. Let’s start by building the legs.
|
||||
|
||||
## Glued-up Legs
|
||||
|
||||

|
||||
|
||||
Aprons at work. Here you can see the 2×12 apron glued to the 1×10 interior piece. The legs will then butt against the 1×10.
|
||||
|
||||
The joinery for this workbench is mostly glue, screws and a few notches. All those joints are in the two end assemblies. Each end assembly consists of two legs made by face-gluing two boards together. The act of gluing these two boards together creates a notch for the bench’s aprons.
|
||||
|
||||

|
||||
|
||||
Can’t miss. By drilling these holes while the pieces are together, you ensure they will mate up again.
|
||||
|
||||
So begin making the end assemblies by gluing the 5 1 ⁄ 2 “-wide leg parts together for each of the four legs. If you don’t own clamps, glue and screw these parts together, then remove the screws after the glue has dried. If you own clamps, I recommend sprinking a pinch of dry sand on the wet layer of glue between the laminations to prevent the pieces from shifting during the clamping process.
|
||||
|
||||

|
||||
|
||||
Mounting plates. Here is how the mounting plates look when they are installed. First you tighten the bolts, then you screw the mounting plate down. This way you can’t miss.
|
||||
|
||||
While the glue in the legs is drying, turn your attention to the aprons.
|
||||
|
||||
## Laminated Aprons
|
||||
|
||||

|
||||
|
||||
Legs & aprons. With the legs and aprons bolted together, you can glue up the parts for the benchtop.
|
||||
|
||||
Like the legs, the front and rear aprons of the workbench are made by face-gluing two parts together to thicken the piece and create notches for the other assemblies.
|
||||
|
||||
Each apron consists of a 2×12 glued to a smaller 1×10 piece. The 2×12 is the exterior of the workbench. The 1×10 makes notches for the legs.
|
||||
|
||||
The length of the 1×10 is the distance between the left legs of the bench and the right legs. In this 6′ workbench, the 1×10 is 45″ long. If your bench is longer, make these parts longer.
|
||||
|
||||

|
||||
|
||||
Easy & accurate. I use aluminum angle pieces for winding sticks. I also use them as edge guides for my circular saw. Clamp the aluminum angle to your benchtop and make your cut.
|
||||
|
||||
Glue and affix a 1×10 to its 2×12 – and make sure the smaller piece is centered on the length of the larger. I used glue and nails to put these parts together. Any combination of glue, screws and nails will do.
|
||||
|
||||
Once the aprons are assembled, you can then clip the corners of the aprons if you like. The 45° corners are cut 4″ from the ends of each apron with a handsaw. The next step is to use the heavy-duty ductile hardware to bolt the legs and aprons together.
|
||||
|
||||
## Knockdown English Workbench Cut List
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
3D View
|
||||
|
||||

|
||||
|
||||
Elevation
|
||||
|
||||

|
||||
|
||||
Plan
|
||||
|
||||

|
||||
|
||||
Profile
|
||||
|
||||
## Hardware Install
|
||||
|
||||

|
||||
|
||||
Leg up. With the bench temporarily assembled like this, you can fit the pieces between the legs so they match the space available.
|
||||
|
||||
Clamp a leg to one of the aprons, making sure the leg is snug against the notch created by the apron’s 1 x10. Now lay out and drill the counterbore for the washer and the clearance hole for the bolt’s shaft. The clearance hole should go all the way through the apron and leg. The counterbore should be deep enough to hold the head of the bolt, the washer and the lock washer.
|
||||
|
||||

|
||||
|
||||
Can’t miss II. With the top plate between the legs, you can put each stretcher on with screws (skip the glue because this is a cross-grain construction).
|
||||
|
||||
Now lock the leg and apron together with the hardware. Thread the bolt through a lock washer and then a washer. Push the bolt through the clearance hole. Spin a ductile mounting plate onto the bolt on the other side.
|
||||
|
||||

|
||||
|
||||
An end, assembled. I know this is an odd construction, but it works. And once you see it, you’ll get it. Here you can see the finished end assembly with the lower stretcher ready for trimming and screwing.
|
||||
|
||||
Snug up the mounting plate, then tighten the nut with a socket wrench. Once both bolts are snugged up on the leg, you can permanently install the mounting plates with screws.
|
||||
|
||||
Repeat this process with the other three legs. When you are done you will have two aprons with their legs attached.
|
||||
|
||||
## Beefy Benchtop
|
||||
|
||||

|
||||
|
||||
Flat makes flat. If your bench base is twisted, your benchtop will be twisted. It pays to get all the base bits in the same plane.
|
||||
|
||||
One of the downsides to many English workbenches is that the top is springy because it is thin or unsupported from below. The traditional solution was to add “bearers” under the benchtop.
|
||||
|
||||
These cross members ran between the front apron to the rear apron. And while they do make the benchtop stouter, I have never liked these tops as much as I like a simple thick benchtop.
|
||||
|
||||

|
||||
|
||||
Bench, flatten thyself. Traverse the underside of the benchtop with a jack plane to get the surface fairly true.
|
||||
|
||||
The top surface of the benchtop is made from 2x12s that have been edge-glued to create a flat panel. This benchtop is 22 1 ⁄ 2 ” wide because it is made from two 2x12s. You can make it narrower if you like – an 18″- to 20″-wide bench is stable enough for handwork.
|
||||
|
||||
Glue up your two planks for your benchtop and cut the top to its finished width and length.
|
||||
|
||||

|
||||
|
||||
Boring for strength. I put three bolts through each assembly. This keeps things flat. Yellow pine doesn’t move much, so I allowed for only a little expansion and contraction by making my clearance holes 1⁄16″ larger than the diameter of my bolts.
|
||||
|
||||
It might be tempting to glue on the second layer of 2×12 to make the benchtop its final thickness. Resist. It is easier to first attach the aprons, legs and thin top. Then, once you finish building the end assemblies, you will know the exact size of this second top piece and exactly where it will go without measuring.
|
||||
|
||||
## Viseless Workholding
|
||||
|
||||

|
||||
|
||||
Face planing. Face planing is accomplished by using a planing stop in combination with either battens or a doe’s foot. A holdfast keeps the doe’s foot in place at the corner of the workpiece to push it against a toothed planing stop. The wedge under the workpiece corner keeps a high corner from rocking. Plane toward your stop and the battens, and don’t drag your plane on the return stroke, or the board will pull away from the stop. Flip the doe’s foot over if the angle is wrong for a holdfast hole.
|
||||
|
||||

|
||||
|
||||
Edge planing. Here are two positions for edge planing: One board is in the crochet and supported by pegs (in holes in the apron) and a batten; the other is supported by the benchtop and held against the planing stop. If the pegs are too far apart, place a batten on the pegs and place the edge of your stock upon that. If the workpiece is narrow and flexes under the plane, or doesn’t reach above the benchtop with the pegs in their highest position, plane the board against the planing stop on the benchtop. If there are hollows under the board, place wedges in them to keep the board from flexing away from the plane. If the board tips over, you are not planing with even pressure. End grain can be planed in the same manner, but to avoid splintering, plane almost to the corner, then flip the workpiece and finish planing.
|
||||
|
||||
Y ou have probably used benches with vises your entire woodworking career. A face vise and tail vise are pretty much the way to go, right?
|
||||
|
||||

|
||||
|
||||
End grain. A bench hook can be used as a simple shooting board for longer or wider boards; the plane rides on the benchtop.
|
||||
|
||||

|
||||
|
||||
Dovetail chopping. Stacking the parts to be chopped saves the need to reset the holdfast individually for each workpiece.
|
||||
|
||||
Maybe. Maybe not.
|
||||
|
||||

|
||||
|
||||
Tenons. Tenoning can be accomplished with the material in the crochet, angled against a peg and held with a holdfast. Angle the board away from you and saw the corners, reverse the board to saw the opposite corners, then square across the bottom. Cut the shoulders in the bench hook (or at the end of the bench using pegs and a holdfast).
|
||||
|
||||
Once you get the hang of it, viseless workholding becomes very fast and can be liberating and fun. Many of these techniques are quite useful, even if you have a vise on your bench. I find them useful for the entry-level person on a budget as well as for the seasoned woodworker seeking to expand his or her options.
|
||||
|
||||

|
||||
|
||||
Dovetail saw cuts. Secure the workpiece against the apron with a thick batten held flush to the benchtop with two holdfasts, and supported by two pegs in the apron’s holdfast holes. I like to take a scrap of stock the same thickness as the material being dovetailed and put it to one edge of the chop. I place my holdfast just to the inside of the scrap and give it a good whack. This will keep that end of the chop fixed so that I need only to loosen the other holdfast when changing out parts to be worked.
|
||||
|
||||
Let’s look at how to accomplish some of the more common tasks at a bench: planing faces, edges and ends of boards; crosscutting and ripping; and sawing a couple of joints.
|
||||
|
||||
— Mike Siemsen
|
||||
|
||||
## Feet in the Air
|
||||
|
||||

|
||||
|
||||
Overkill. After gluing and screwing the second benchtop piece in place I also clamped things together while the glue dried.
|
||||
|
||||
This next step ensures that the end assemblies will be the correct size for the width of your top. Assemble the bench upside down on sawbenches. Clamp the aprons to the top and push things around until the legs are square to the underside of the top and the aprons line up with the top all around.
|
||||
|
||||
Once you have everything clamped as you like it, you can fit the pieces for the end assemblies that go between the front legs and the back legs. There is a top plate that is the same width as the legs, plus a top stretcher made from a 2×12 that fits between the front apron and the rear apron.
|
||||
|
||||
Cut these pieces to fit. Then wedge the top plate pieces between the legs and screw the stretchers to the legs.
|
||||
|
||||
With the top stretchers screwed to the legs, you can take the bench apart, then glue and screw the top plates in place. Don’t forget to glue the edge of the top plate to the face of the top stretcher. There is a lot of strength to be found there.
|
||||
|
||||
The last bit of work is to attach the lower stretchers to the legs. These stretchers are in a notch in each leg. Cut the notch with a handsaw and clear the waste with a chisel. Then screw and glue the lower stretchers into their notches.
|
||||
|
||||
Reassemble the bench’s base so you can get the top complete.
|
||||
|
||||
## The Top (& Details)
|
||||
|
||||

|
||||
|
||||
Apron holes. Here I’m drawing the diagonal lines for the holdfast holes in the aprons. Many people use wooden pegs in the aprons instead of holdfasts. Both solutions defy gravity just fine.
|
||||
|
||||
With the base assembled, level the top edges of the aprons and the end assemblies so they are coplanar – that’s the first step toward a flat benchtop.
|
||||
|
||||
I dressed these parts with a jointer plane and [block plane](https://www.popularwoodworking.com/review/block-plane/) and checked my work with winding sticks and a straightedge.
|
||||
|
||||
Before you put the top on the base, I recommend one little addition at this stage. I attached glue blocks – for the lack of a better word – to the aprons so the end assemblies would be captured. You can see in the photo above that I used an offcut from a 2×12 and oriented the grain sympathetically with the apron. This five-minute upgrade makes the bench easier to assemble and a bit stouter.
|
||||
|
||||
Now you can flatten the underside of the benchtop by using the bench’s base for support.
|
||||
|
||||
Put the benchtop on the base and plane the underside of the top flat with a jack plane – don’t worry about flattening the top of the benchtop. A couple of F-style clamps on the bench base will keep the top in place during this operation.
|
||||
|
||||
Test your benchtop by flipping it over and showing it to the workbench’s base. When the two parts meet without any rocking, you are done. Clamp the benchtop in place with the worksurface facing up. Now install the bolts, washers and mounting plates through the top and the top plate of the end assemblies. Do this in the same way you attached the legs to the aprons.
|
||||
|
||||
Now flip the assembled bench over. You now can see the precise hole where the second benchtop piece should go. Glue up a panel using 2×12 material and cut it to fit that hole exactly. Glue and screw it to the underside of the benchtop. Then lift the workbench base off the benchtop and clamp the top pieces together for extra bonding power.
|
||||
|
||||
When the glue is dry, use a block plane to bevel the mating surfaces so they will slide together easily during assembly.
|
||||
|
||||
## Holes & Holding
|
||||
|
||||

|
||||
|
||||
Square hole. This is a great first mortise for a beginning woodworker. Take your time in squaring up the walls.
|
||||
|
||||
You just made a table. Now you need to make it a workbench. To do that you need to add three things: a crochet, a planing stop and holdfast holes. The holdfast holes restrain your work on the benchtop and front apron. The crochet is for edge planing. The planing stop is for lots of things. Let’s make the holdfast holes first.
|
||||
|
||||
To lay out the holdfast holes on the aprons, draw two or three rectangles on the aprons between the positions of your bench legs. Two rectangles for a 6′ bench; three for an 8′ model.
|
||||
|
||||
Connect two corners of each rectangle with a diagonal line. Then use dividers to equally space six holes from corner to corner on the diagonal lines. Then divide the vertical ends of each rectangle into three using your dividers.
|
||||
|
||||
Drill 3 ⁄ 4 “-diameter through-holes at each of these locations. These holes in the aprons are great for supporting work from below, especially when edge-planing or dovetailing.
|
||||
|
||||
Now lay out the holdfast holes on the benchtop. My preference is to have two rows of holdfast holes on the benchtop (you can always add more later). One row is about 3″ from the back edge of the benchtop. These should be spaced every 10″ to 16″ depending on the reach of your holdfast. Then make another row of holdfast holes about 6″ in front of your back row. These should be spaced similarly, but these holes should be offset from the first row, as shown in the drawings and photos.
|
||||
|
||||
Be sure to drill some holdfast holes in the legs – both to store holdfasts and to support large work, such as passageway doors. Hold off on drilling any additional holdfast holes until you really need them.
|
||||
|
||||
## The Planing Stop
|
||||
|
||||
The traditional planing stop is a workhorse. I push workpieces against it to saw them, plane them, stick moulding on them, you name it. The stop is a piece of dense wood (yellow pine is dense enough) that is friction-fit into a mortise in the benchtop.
|
||||
|
||||
First make the mortise, then make the planing stop to fit.
|
||||
|
||||
The mortise for the planing stop is right in front of the end assembly and typically 3″ or so in from the front edge of the benchtop. This planing stop is 2 1 ⁄ 2 ” x 2 1 ⁄ 2 ” x 12″ – a fairly traditional size.
|
||||
|
||||
Lay out the mortise on both faces of the benchtop. Then bore out most of the waste with a large-diameter bit. Finish the walls with a chisel. It pays to check the walls so they are perfectly square to the benchtop.
|
||||
|
||||
Then plane the planing stop until it is a tight fit in the mortise and it requires mallet blows to move it up and down. Some planing stops also have a toothy metal bit in the middle that helps restrain your work. You can add that later if you like. It can be a blacksmith-made stop, a piece of scrap metal screwed to the top of the planing stop or even a few nails that are driven through the stop so their tips poke out.
|
||||
|
||||
## Le Crochet
|
||||
|
||||
For this workbench I decided to make a crochet that looks exactly like the one in Roubo’s “l’Art du menuisier.” But to be honest, I don’t think the shape matters much. I’ve used a lot of different shapes and they all seem to work fine as long as they are vaguely “hook-shaped.”
|
||||
|
||||
I made this crochet from scraps. I glued them together, then shaped the hook on the band saw, finishing it up with rasps.
|
||||
|
||||
I attached the crochet with two lag screws and one cap screw, which was backed by a ductile mounting plate. This allows me to remove the crochet from the apron. As you might notice in the illustration, and in the photo above, the crochet slightly interferes with one of the cap screws through the apron. You can avoid this by altering the shape of your crochet or moving the hole for the cap screw.
|
||||
|
||||
## A Shelf if You Like
|
||||
|
||||
I always like having a shelf below my bench to store bench planes and other assemblies. I haven’t included the shelf in the calculation for buying materials, so you’ll need some extra wood and screws to get the job done.
|
||||
|
||||
The shelf is simply a panel that rests on cleats that are glued and screwed to the lower stretchers of the end assemblies. You can also screw some battens to the underside (and/or top) of the shelf to help keep it flat.
|
||||
|
||||
The only thing holding the shelf in place is gravity.
|
||||
|
||||
## And Finish
|
||||
|
||||

|
||||
|
||||
The hook. You can bolt your crochet on. Some early accounts indicate it was nailed on. You probably could get away with glue alone.
|
||||
|
||||
You don’t want to make your bench too slippery, so stay away from film finishes (or French polish). I recommend using little or no finish. For most workbenches, I usually just add a coat of boiled linseed oil. You can use an equal blend of oil, varnish and mineral spirits or just leave the wood bare.
|
||||
|
||||
In the end, this really is a remarkably sturdy bench. Most people who use it cannot even tell that it is designed to be knocked down. It is only after they notice the cap screws in the benchtop that they suspect anything.
|
||||
|
||||
**Plan:** Download a [free SketchUp model](https://3dwarehouse.sketchup.com/model.html?id=uc53c1fce-de6c-4203-b11d-faa9afc58901) of this project.
|
||||
|
||||

|
||||
|
||||
---
|
||||
964
Clippings/Master Hexagonal Architecture in Rust 1.md
Normal file
964
Clippings/Master Hexagonal Architecture in Rust 1.md
Normal file
@ -0,0 +1,964 @@
|
||||
---
|
||||
title: "Master Hexagonal Architecture in Rust"
|
||||
source: "https://www.howtocodeit.com/articles/master-hexagonal-architecture-rust"
|
||||
author:
|
||||
- "[[How To Code It]]"
|
||||
published:
|
||||
created: 2025-08-14
|
||||
description: "Everything you need to write flexible, future-proof Rust applications using hexagonal architecture."
|
||||
tags:
|
||||
- "clippings"
|
||||
---
|
||||
Contents[Introduction](https://www.howtocodeit.com/articles/#introduction)
|
||||
|
||||
[
|
||||
|
||||
Part I:Anatomy of a bad Rust application
|
||||
|
||||
](https://www.howtocodeit.com/articles/#anatomy-of-a-bad-rust-application)
|
||||
1. [What problems does hexagonal architecture solve?](https://www.howtocodeit.com/articles/#what-problems-does-hexagonal-architecture-solve)
|
||||
2. [Hard dependencies and hexagonal architecture: how to make the right call](https://www.howtocodeit.com/articles/#hard-dependencies-and-hexagonal-architecture-how-to-make-the-right-call)
|
||||
|
||||
[
|
||||
|
||||
Part II:Separation of concerns, the Rust way
|
||||
|
||||
](https://www.howtocodeit.com/articles/#separation-of-concerns-the-rust-way)
|
||||
1. [Getting started with hexagonal architecture](https://www.howtocodeit.com/articles/#getting-started-with-hexagonal-architecture)
|
||||
2. [The repository pattern in Rust](https://www.howtocodeit.com/articles/#the-repository-pattern-in-rust)
|
||||
3. [Domain models](https://www.howtocodeit.com/articles/#domain-models)
|
||||
4. [Error types and hexagonal architecture](https://www.howtocodeit.com/articles/#error-types-and-hexagonal-architecture)
|
||||
1. [Don't panic](https://www.howtocodeit.com/articles/#dont-panic)
|
||||
6. [Everything but the kitchen async](https://www.howtocodeit.com/articles/#everything-but-the-kitchen-async)
|
||||
7. [From the Very Bad Application to the merely Bad Application](https://www.howtocodeit.com/articles/#from-the-very-bad-application-to-the-merely-bad-application)
|
||||
8. [Testing HTTP handlers with injected repositories](https://www.howtocodeit.com/articles/#testing-http-handlers-with-injected-repositories)
|
||||
|
||||
[
|
||||
|
||||
Part III:`Service`, the heart of hexagonal architecture
|
||||
|
||||
](https://www.howtocodeit.com/articles/#service-the-heart-of-hexagonal-architecture)
|
||||
1. [Introducing the `Service` trait](https://www.howtocodeit.com/articles/#introducing-the-service-trait)
|
||||
2. [Why hexagons?](https://www.howtocodeit.com/articles/#why-hexagons)
|
||||
3. [How to choose the right domain boundaries](https://www.howtocodeit.com/articles/#how-to-choose-the-right-domain-boundaries)
|
||||
1. [Start with large domains](https://www.howtocodeit.com/articles/#start-with-large-domains)
|
||||
5. [A Rust project template for hexagonal architecture](https://www.howtocodeit.com/articles/#a-rust-project-template-for-hexagonal-architecture)
|
||||
6. [Make an informed decision](https://www.howtocodeit.com/articles/#make-an-informed-decision)
|
||||
|
||||
[
|
||||
|
||||
Part IV:Trade-offs of hexagonal architecture in Rust
|
||||
|
||||
](https://www.howtocodeit.com/articles/#trade-offs-of-hexagonal-architecture-in-rust)
|
||||
1. [Put down the Kool-Aid](https://www.howtocodeit.com/articles/#put-down-the-kool-aid)
|
||||
2. [Strengths and weaknesses of hexagonal architecture](https://www.howtocodeit.com/articles/#strengths-and-weaknesses-of-hexagonal-architecture)
|
||||
3. [Is hexagonal architecture right for you?](https://www.howtocodeit.com/articles/#is-hexagonal-architecture-right-for-you)
|
||||
1. [Solo developers and personal projects](https://www.howtocodeit.com/articles/#solo-developers-and-personal-projects)
|
||||
2. [Applications with little business logic](https://www.howtocodeit.com/articles/#applications-with-little-business-logic)
|
||||
3. [Startups that want to scale hard](https://www.howtocodeit.com/articles/#startups-that-want-to-scale-hard)
|
||||
4. [Big team, big monolith, big headache](https://www.howtocodeit.com/articles/#big-team-big-monolith-big-headache)
|
||||
5. [Greenfield projects in established companies](https://www.howtocodeit.com/articles/#greenfield-projects-in-established-companies)
|
||||
6. [High-performance applications](https://www.howtocodeit.com/articles/#high-performance-applications)
|
||||
5. [Adopting hexagonal architecture](https://www.howtocodeit.com/articles/#adopting-hexagonal-architecture)[Part V:Advanced hexagonal architecture in Rust](https://www.howtocodeit.com/articles/#advanced-hexagonal-architecture-in-rust)[Exercises](https://www.howtocodeit.com/articles/#exercises)[Discussion](https://www.howtocodeit.com/articles/#discussion)
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
## Introduction
|
||||
|
||||
Hexagonal Architecture. You've heard the buzzwords. You've wondered, "why hexagons?". You think domain-driven design is involved, somehow. Your company probably says they're using it, but you suspect they're doing it wrong.
|
||||
|
||||
Let me clear things up for you.
|
||||
|
||||
By the end of this guide, you'll have everything you need to write ironclad Rust applications using hexagonal architecture.
|
||||
|
||||
I will get you writing the most maintainable Rust of your life. Your production errors will fall. Test coverage with skyrocket. Scaling will get less painful.
|
||||
|
||||
If you haven't read [*The Ultimate Guide to Rust Newtypes*](https://www.howtocodeit.com/articles/ultimate-guide-rust-newtypes) yet, I recommend doing so first – type-driven design is the cherry to hexagonal architecture's sundae, and you'll see many examples of newtypes in this tutorial.
|
||||
|
||||
Now, this is a big topic. Huge (O'Reilly, hit me up). I'm going to publish it section by section, releasing the next only once you've had a chance to digest the last and tackle the [exercises](https://www.howtocodeit.com/articles/#exercises) for each new concept. Bookmark this page if you don't want to miss anything – I'll add every new section here.
|
||||
|
||||
I'll be using a blogging engine with an [axum](https://docs.rs/axum/latest/axum/) web server as our primary example throughout this guide. Over time, we'll build it into an application of substantial complexity.
|
||||
|
||||
The type of app and the crates it uses are ultimately irrelevant, though. The principles of hexagonal architecture are not confined to web apps – any application that receives external input or makes requests to the outside world can benefit.
|
||||
|
||||
Let's get into it.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
### What problems does hexagonal architecture solve?
|
||||
|
||||
The answer to the question "why hexagons?" is boring, so we're not going to start there.
|
||||
|
||||
How To Code It is all about code! I'm going to start by showing you how *not* to write applications in Rust. By studying a Very Bad Application, you'll see the problems that hexagonal architecture solves clearly.
|
||||
|
||||
The Very Bad Application is the most common way to write production services. Your company will have code that looks just like it. [*Zero To Production In Rust*](https://www.zero2prod.com/index.html) writes its tutorial app in a similar way. In fairness, it has its hands full with teaching us Rust, and it only promised to *get* us to production, not keep us there.
|
||||
|
||||
The Very Bad Application is a scaling and maintainability time bomb. It is a misery to test and refactor. It will increase your staff turnover and lower your annual bonus.
|
||||
|
||||
Here's my take on `main.rs` for such a program:
|
||||
|
||||
```
|
||||
rustsrc/bin/server/main.rs#[tokio::main]async fn main() -> anyhow::Result<()> { let config = Config::from_env()?;
|
||||
// A minimal tracing middleware for request logging. tracing_subscriber::fmt::init(); let trace_layer = tower_http::trace::TraceLayer::new_for_http().make_span_with( |request: &axum::extract::Request<_>| { let uri = request.uri().to_string(); tracing::info_span!("http_request", method = ?request.method(), uri) },1 );
|
||||
let sqlite = SqlitePool::connect_with(2 SqliteConnectOptions::from_str(&config.database_url) .with_context(|| format!("invalid database path {}", &config.database_url))? .pragma("foreign_keys", "ON"), ) .await .with_context(|| format!("failed to open database at {}", &config.database_url))?;
|
||||
let app_state = AppState { sqlite: Arc::new(sqlite),3 }; let router = axum::Router::new()4 .route("/authors", post(create_author)) .layer(trace_layer) .with_state(app_state); let listener = net::TcpListener::bind(format!("0.0.0.0:{}", &config.server_port)) .await .with_context(|| format!("failed to listen on {}", &config.server_port))?;
|
||||
tracing::debug!("listening on {}", listener.local_addr().unwrap()); axum::serve(listener, router) .await .context("received error from running server")?;
|
||||
Ok(())}
|
||||
```
|
||||
|
||||
This code loads the application config from the environment, configures some tracing middleware, creates an Sqlite connection pool, and injects it into an axum HTTP router. We have one route: `POST /authors`, for creating blog post authors. Finally, it binds Tokio `TcpListener` to the application port and fires up the server.
|
||||
|
||||
We're concerned about *architecture*, so I've omitted details like a panic recovery layer, the finer points of tracing, graceful shutdown, and most of the routes a full app would have.
|
||||
|
||||
Even so, this is fat `main` function. If you're tempted to say that it could be improved by moving the application setup logic to a dedicated `setup` module, you're not wrong – but your priorities are. There is much greater evil here.
|
||||
|
||||
Firstly, why is `main` configuring HTTP middleware [`1`](https://www.howtocodeit.com/articles/#code-ref-1)? In fact, it looks like `main` needs an intimate understanding of the whole axum crate just to get the server running [`4`](https://www.howtocodeit.com/articles/#code-ref-4)! axum isn't even part of our application – it's a third-party dependency that has escaped containment.
|
||||
|
||||
You'd have the same problem if this code lived in a `setup` module. It's not the location of the setup, but the failure to encapsulate and abstract dependencies that makes this code hard to maintain.
|
||||
|
||||
If you ever change your HTTP server, `main` has to change too. To add middleware, you modify `main`. Major version changes in axum could force you to change `main`.
|
||||
|
||||
We have the same issue with the database at [`2`](https://www.howtocodeit.com/articles/#code-ref-2), where we shackle our `main` function to one particular, third-party implementation of an Sqlite client. Next, we make things *so* much worse by flowing this concrete representation – an imported struct entirely outside our control – through the *entire application*. See how we pass `sqlite` into axum as a field of `AppState` [`3`](https://www.howtocodeit.com/articles/#code-ref-3) to make it accessible to our HTTP handlers?
|
||||
|
||||
To change your database client – not even to change the kind of database, just the code that calls it – you'd have to rip out this hard dependency from every corner of your application.
|
||||
|
||||
This isn't a leaky abstraction, it's a broken dam.
|
||||
|
||||
Take a moment to recover, because I'm about to show you the `create_author` handler, and it's a bloodbath.
|
||||
|
||||
```
|
||||
rustsrc/lib/routes.rspub async fn create_author( State(state): State<AppState>,5 Json(author): Json<CreateAuthorRequestBody>,) -> Result<ApiSuccess<CreateAuthorResponseData>, ApiError> { if author.name.is_empty() {6 return Err(ApiError::UnprocessableEntity( "author name cannot be empty".to_string(), )); }
|
||||
let mut tx = state7 .sqlite .begin() .await .context("failed to start transaction")?;
|
||||
let author_id = save_author(&mut tx, &author.name).await.map_err(|e| { if is_unique_constraint_violation(&e) {8 ApiError::UnprocessableEntity(format!( "author with name {} already exists", &author.name )) } else { anyhow!(e).into() } })?;
|
||||
tx.commit().await.context("failed to commit transaction")?;
|
||||
Ok(ApiSuccess::new( StatusCode::CREATED, CreateAuthorResponseData { id: author_id.to_string(), }, ))}
|
||||
```
|
||||
|
||||
Stay with me! Suppress the urge to vomit. We'll get through this together and come out as better Rust devs.
|
||||
|
||||
Look, there's that hard dependency on sqlx [`5`](https://www.howtocodeit.com/articles/#code-ref-5), polluting the system on cue 🙄. And holy good god, our HTTP handler is orchestrating database transactions [`7`](https://www.howtocodeit.com/articles/#code-ref-7). An HTTP handler shouldn't even know what a database *is*, but this one knows SQL!
|
||||
|
||||
```
|
||||
rustsrc/lib/routes.rsasync fn save_author(tx: &mut Transaction<'_, Sqlite>, name: &str) -> Result<Uuid, sqlx::Error> { let id = Uuid::new_v4(); let id_as_string = id.to_string(); let query = sqlx::query!( "INSERT INTO authors (id, name) VALUES ($1, $2)", id_as_string, name ); tx.execute(query).await?; Ok(id)}
|
||||
```
|
||||
|
||||
And the horrifying consequence of this is that the handler also has to understand the specific error type of the database crate – and the database itself [`8`](https://www.howtocodeit.com/articles/#code-ref-8):
|
||||
|
||||
```
|
||||
rustsrc/lib/routes.rsconst UNIQUE_CONSTRAINT_VIOLATION_CODE: &str = "2067";
|
||||
fn is_unique_constraint_violation(err: &sqlx::Error) -> bool { if let sqlx::Error::Database(db_err) = err { if let Some(code) = db_err.code() { if code == UNIQUE_CONSTRAINT_VIOLATION_CODE { return true; } } }
|
||||
false}
|
||||
```
|
||||
|
||||
Refactoring this kind of code is miserable, you get that. But here's the kicker – unit testing this kind of code is impossible.
|
||||
|
||||
You cannot call this handler without a real, concrete instance of an sqlx SQLite connection pool.
|
||||
|
||||
And don't come at me with "it's fine, we can still integration test it", because that's not enough. Look at how complex the error handling is. We've got inline request body validation [`6`](https://www.howtocodeit.com/articles/#code-ref-6), transaction management [`7`](https://www.howtocodeit.com/articles/#code-ref-7), and sqlx errors [`8`](https://www.howtocodeit.com/articles/#code-ref-8) in one function.
|
||||
|
||||
Integration tests are slow and expensive – they aren't suited to exhaustive coverage. And how are you going to test the scenario where the transaction fails to start? Will you make the real database fall over?
|
||||
|
||||
This architecture is game over for maintainability. Nightmare fuel.
|
||||
|
||||
### Hard dependencies and hexagonal architecture: how to make the right call
|
||||
|
||||
Hard dependencies aren't irredeemably evil – you'll see several as we build our hexagonal answer to the Very Bad Application – but they are use-case-dependent.
|
||||
|
||||
Tokio is a hard dependency of most production Rust applications. This is by necessity. An async runtime is a dependency on a grand scale, practically part of the language itself. Your application can't function without it, and its purpose is so fundamental that you'd gain nothing from attempting to abstract it away.
|
||||
|
||||
In these situations, consider the few alternatives carefully, and accept that changing your mind later will mean a painful refactor. Most of all, look for evidence of widespread community adoption and support.
|
||||
|
||||
HTTP packages, database clients, message queues, etc. do not fall into this category. Teams opt to change these dependencies regularly, for reasons including:
|
||||
|
||||
- scaling pressures that require new technical solutions,
|
||||
- deprecation of key libraries,
|
||||
- security threats,
|
||||
- someone more senior said so.
|
||||
|
||||
It's critical that we abstract these packages behind our own, clean interfaces, forcing conformity with our application. In the next part of this guide, you'll learn how to do exactly that.
|
||||
|
||||
Hexagonal architecture brings order to chaos and flexibility to fragile programs by making it easy to create modular applications where connections to the outside world always adhere to the most important API of all: your business domain.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
Part II
|
||||
|
||||
## Separation of concerns, the Rust way
|
||||
|
||||
### Getting started with hexagonal architecture
|
||||
|
||||
Our transition to hexagonal architecture begins here. We'll move from a tightly coupled, untestable nightmare to a happy place where production doesn't fall over at 3am.
|
||||
|
||||
We're going to transform the Very Bad Application gradually, zooming out a little at a time until you see the whole hexagon. Then I'll answer "why hexagons?". Promise.
|
||||
|
||||
I've omitted details like module names and folder structure for simplicity. Don't worry, though. Before this guide is over, you'll have a complete application template you can reuse across all your projects.
|
||||
|
||||
### The repository pattern in Rust
|
||||
|
||||
The worst part of the Very Bad Application is undoubtedly having an HTTP handler making direct queries to an SQL database. This is a plus-sized violation of the Single Responsibility Principle.
|
||||
|
||||
Code that understands the HTTP request-response cycle shouldn't also understand SQL. Code that needs a database doesn't need to know how that database is implemented. These could not be more different concerns.
|
||||
|
||||
Hard-coding your handler to manage SQL transactions will come back to bite you if you switch to Mongo. That Mongo connection will need ripping out if you move to event streaming, to querying a CQRS service, or to making an intern do it by hand.
|
||||
|
||||
All of these are valid data stores. If you overcommit by hard-wiring any one of them into your system, you guarantee future pain when you can least afford it – when you need to scale.
|
||||
|
||||
Repository is the general term for "some store of data". Our first step is to move the `create_author` handler away from SQL and towards the abstract concept of a repository.
|
||||
|
||||
A handler that says "give me any store of data" is much better than a handler that says "give me this specific store of data, because it's the only one I know how to use".
|
||||
|
||||
Your mind has undoubtedly turned to traits as Rust's way of defining behaviour as opposed to structure. How very astute of you. Let's define an `AuthorRepository` trait:
|
||||
|
||||
```
|
||||
rust/// \`AuthorRepository\` represents a store of author data.pub trait AuthorRepository { /// Persist a new [Author]. /// /// # Errors /// /// - MUST return [CreateAuthorError::Duplicate] if an [Author] with the same [AuthorName] /// already exists. fn create_author( &self, req: &CreateAuthorRequest,9 ) -> Result<Author, CreateAuthorError>>;10}
|
||||
```
|
||||
|
||||
An `AuthorRepository` is some store of author data with (currently) one method: `create_author`.
|
||||
|
||||
`create_author` takes a reference to the data required to create an author [`9`](https://www.howtocodeit.com/articles/#code-ref-9), and returns a `Result` containing either a saved `Author`, or a specific error type describing everything that might go wrong while creating an author [`10`](https://www.howtocodeit.com/articles/#code-ref-10). Right now, that's just the existence of duplicate authors, but we'll come back to error handling.
|
||||
|
||||
`AuthorRepository` is what's known as a domain trait. You might also have heard the term "port" before – a point of entry to your business logic. A concrete implementation of a port (say, an SQLite `AuthorRepository`) is called an adapter. Starting to sound familiar?
|
||||
|
||||
For any code that requires access to a store of author data, this port is the source of truth for how every implementation behaves. Callers no longer have to think about SQL or message queues, they just invoke this API, and the underlying adapter does all the hard work.
|
||||
|
||||
### Domain models
|
||||
|
||||
`CreateAuthorRequest`, `Author` and `CreateAuthorError` are all examples of *domain models*.
|
||||
|
||||
Domain models are the canonical representations of data accepted by your business logic. Nothing else will do. Let's see some definitions:
|
||||
|
||||
```
|
||||
rust/// A uniquely identifiable author of blog posts.#[derive(Clone, Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]pub struct Author {11 id: Uuid, name: AuthorName,}
|
||||
impl Author { pub fn new(id: Uuid, name: &str) -> Self { Self { id, name: AuthorName::new(name), } }
|
||||
pub fn id(&self) -> &Uuid { &self.id }
|
||||
pub fn name(&self) -> &AuthorName { &self.name }}
|
||||
/// A validated and formatted name.#[derive(Clone, Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]pub struct AuthorName(String);
|
||||
#[derive(Clone, Debug, Error)]#[error("author name cannot be empty")]pub struct AuthorNameEmptyError;
|
||||
impl AuthorName { pub fn new(raw: &str) -> Result<Self, AuthorNameEmptyError> { let trimmed = raw.trim(); if trimmed.is_empty() { Err(AuthorNameEmptyError) } else { Ok(Self(trimmed.to_string())) } }}
|
||||
/// The fields required by the domain to create an [Author].#[derive(Clone, Debug, PartialEq, Eq, PartialOrd, Ord, Hash, From)]pub struct CreateAuthorRequest {12 name: AuthorName,}
|
||||
impl CreateAuthorRequest { // Constructor and getters ommitted}
|
||||
#[derive(Debug, Clone, PartialEq, Eq, Error)]pub enum CreateAuthorError {13 #[error("author with name {name} already exists")] Duplicate { name: AuthorName }, // to be extended as new error scenarios are introduced}
|
||||
```
|
||||
|
||||
Now, these aren't very exciting models (they'll get more exciting when we talk about identifying the correct domain boundaries and the special concern of authentication in [Part III](https://www.howtocodeit.com/articles/#service-the-heart-of-hexagonal-architecture)). But they demonstrate how the domain defines what data flowing through the system must look like.
|
||||
|
||||
If you don't construct a valid `CreateAuthorRequest` from the raw parts you've received over the wire (or from that intern), you can't call `AuthorRepository::create_author`. Sorry, jog on. 🤷
|
||||
|
||||
This pattern of newtyping should be familiar if you've read [*The Ultimate Guide to Rust Newtypes*](https://www.howtocodeit.com/articles/ultimate-guide-rust-newtypes). If you haven't, I'll wait for you here.
|
||||
|
||||
Four special properties arise from this:
|
||||
|
||||
1. Your business domain becomes the single source of truth for what it means to be an author, user, bank transaction or stock trade.
|
||||
2. The flow of dependencies in your application points in only one direction: towards your domain.
|
||||
3. Data structures within your domain are guaranteed to be in a valid state.
|
||||
4. You don't allow third-party implementation details, like SQL transactions or RPC messages to flow through unrelated code.
|
||||
|
||||
And this has immediate practical benefits:
|
||||
|
||||
- Easier navigation of the codebase for veterans and new joiners.
|
||||
- It's trivial to implement new data stores or input sources – you just implement the corresponding domain trait.
|
||||
- Refactoring is dramatically simplified thanks to the absence of hard-coded implementation details. If an implementation of a domain trait changes, nothing about the domain code or anything downstream from it needs to change.
|
||||
- Testability skyrockets, because any domain trait, like `AuthorRepository` can be mocked. We'll see this in action shortly.
|
||||
|
||||
Why do we distinguish `CreateAuthorRequest` [`12`](https://www.howtocodeit.com/articles/#code-ref-12) from `Author` [`11`](https://www.howtocodeit.com/articles/#code-ref-11)? Surely we could represent both saved and unsaved `Author` s as
|
||||
|
||||
```
|
||||
rustpub struct Author { id: Option<Uuid>, name: AuthorName,}
|
||||
```
|
||||
|
||||
Right now, with this exact application, this would be fine. It might be annoying to check whether `id` is `Some` or `None` to distinguish whether `Author` is saved or unsaved, but it would work.
|
||||
|
||||
However, we'd be mistaken in assuming that the data required to create an `Author` and the representation of an existing `Author` will never diverge. This is not at all true of real applications.
|
||||
|
||||
I've done a lot of work in onboarding and ID verification for fintechs. The data required to fully represent a customer is extensive. It can take many weeks to collect it and make an account fully operational.
|
||||
|
||||
This is pretty poor as a customer experience, and abandonment would be high if you took an all-or-nothing approach to account creation.
|
||||
|
||||
Instead, an initial outline of a customer's details is usually enough to create a basic profile. You get the customer interacting with the platform as soon as possible, and stagger the collection of the remaining data, fleshing out the model over time.
|
||||
|
||||
In this scenario, you don't want to represent some `CreateCustomerRequest` and `Customer` in the same way. `Customer` may contain dozens of optional fields and relations that aren't required to create a record in the database. It would be brittle and inefficient to pass such a needlessly large struct when creating a customer.
|
||||
|
||||
What happens when the domain representation of a customer changes, but the data required to create one remains the same? You'd be forced to change your request handling code too. Or, you'd be forced to do what you should have done from the start – decouple these models.
|
||||
|
||||
Hexagonal architecture is about building for change. Although these models may look like duplicative boilerplate to begin with, don't be fooled. Your application will change. Your API *will* diverge from your domain representation.
|
||||
|
||||
By modeling persistent entities separately from requests to create them, you encode an incredible capacity to scale.
|
||||
|
||||
Let's zoom in on `CreateAuthorError` [`13`](https://www.howtocodeit.com/articles/#code-ref-13). It reveals some important properties of domain models and traits.
|
||||
|
||||
`CreateAuthorError` doesn't define failure cases such as an input name being invalid. This is the responsibility of the `CreateAuthorRequest` constructor (which in this case delegates to the `AuthorName` constructor). Here's more on [using newtype constructors as the source of truth](https://www.howtocodeit.com/articles/ultimate-guide-rust-newtypes#constructors-as-the-source-of-truth) if you're unclear on this point.
|
||||
|
||||
`CreateAuthorError` defines failures that arise from coordinating the action of adapters. There are two categories: violations of business rules, like attempting to create a duplicate author, and unexpected errors that the domain doesn't know how to handle.
|
||||
|
||||
Much as our domain would like to pretend the real world doesn't exist, *many* things can go wrong when calling a database. We could fail to start a transaction, or fail to commit it. The database could literally catch fire in the course of a request.
|
||||
|
||||
The domain doesn't know anything about database implementations. It doesn't know about transactions. It doesn't know about the fire hazards posed by large datacenters and your pyromaniac intern. It's oblivious to retry strategies, cache layers and dead letter queues (we'll talk about these in [Part V: *Advanced Hexagonal Architecture in Rust*](https://www.howtocodeit.com/articles/#advanced-hexagonal-architecture-in-rust)).
|
||||
|
||||
But it needs some mechanism to propagate unexpected errors back up the call chain. This is typically achieved with a catch-all variant, `Unknown`, which wraps a general error type. `anyhow::Error` is particularly convenient for this, since it includes a backtrace for any error it wraps.
|
||||
|
||||
As a result (no pun intended), `CreateAuthorError` is a complete description of everything that can go wrong when creating an author.
|
||||
|
||||
This is incredible news for callers of domain traits – immensely powerful. Any code calling a port has a complete description of every error scenario it's expected to handle, and the compiler will make sure that it does.
|
||||
|
||||
But enough theorizing! Let's see this in practice.
|
||||
|
||||
### Implementing AuthorRepository
|
||||
|
||||
Here, I move the code required to interact with an SQLite database out of the Very Bad Application's `create_author` handler and into an implementation of `AuthorRepository`.
|
||||
|
||||
We start by wrapping an sqlx connection pool in our own `Sqlite` type. Module paths for sqlx types are fully qualified to avoid confusion:
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]pub struct Sqlite { pool: sqlx::SqlitePool,}
|
||||
impl Sqlite { pub async fn new(path: &str) -> anyhow::Result<Sqlite> {14 let pool = sqlx::SqlitePool::connect_with( sqlx::sqlite::SqliteConnectOptions::from_str(path) .with_context(|| format!("invalid database path {}", path))?15 .pragma("foreign_keys", "ON"), ) .await .with_context(|| format!("failed to open database at {}", path))?;
|
||||
Ok(Sqlite { pool }) }}
|
||||
```
|
||||
|
||||
Wrapping types like `sqlx::SqlitePool` has the benefit of encapsulating a third-party dependencies within code of our own design. Remember the Very Bad Application's leaky `main` function [`1`](https://www.howtocodeit.com/articles/#code-ref-1)? Wrapping external libraries and exposing only the functionality your application needs is how we plug the leaks.
|
||||
|
||||
Again, don't worry about module structure for now. Get comfortable with the type definitions, then we'll assemble the pieces.
|
||||
|
||||
This constructor does what you'd expect, with the possible exception of the result it returns. This constructor isn't part of the `AuthorRepository` trait, so we're not bound by its strict opinions on the types of allowable error.
|
||||
|
||||
[anyhow](https://docs.rs/anyhow/latest/anyhow/) is an excellent crate for working with non-specific errors. `anyhow::Result` is equivalent to `Result<T, anyhow::Error>`, and `anyhow::Error` says we don't care *which* error occurred, just that one did.
|
||||
|
||||
At the point where most applications are instantiating databases, the only reasonable thing to do with an error is log it to `stdout` or some log aggregation service. `Sqlite::new` simply wraps any sqlx error it encounters with some extra context [`15`](https://www.howtocodeit.com/articles/#code-ref-15).
|
||||
|
||||
Now, the exciting stuff – the implementation of `AuthorRepository`:
|
||||
|
||||
```
|
||||
rustimpl AuthorRepository for Sqlite { async fn create_author(&self, req: &CreateAuthorRequest) -> Result<Author, CreateAuthorError> { let mut tx = self16 .pool .begin() .await .unwrap_or_else(|e| panic!("failed to start SQLite transaction: {}", e));
|
||||
let author_id = self.save_author(&mut tx, req.name())17 .await .map_err(|e| { if is_unique_constraint_violation(&e) {18 CreateAuthorError::Duplicate { name: req.name().clone(), } } else { anyhow!(e) .context(format!("failed to save author with name {:?}", req.name())) .into()19 } })?;
|
||||
tx.commit() .await .unwrap_or_else(|e| panic!("failed to commit SQLite transaction: {}", e));
|
||||
Ok(Author::new(author_id, req.name().clone())) }}
|
||||
```
|
||||
|
||||
Look! Transaction management is now encapsulated within our `Sqlite` implementation of `AuthorRepository`. The HTTP handler no longer has to know about it.
|
||||
|
||||
`create_author` invokes the `save_author` method on `Sqlite`, which isn't specified by the `AuthorRepository` trait, but gives `Sqlite` the freedom to set up and pass around transactions as it requires.
|
||||
|
||||
This is the beauty of abstracting implementation details behind traits. The trait defines what needs to happen, and the implementation decides how. None of the *how* is visible to code calling a trait method.
|
||||
|
||||
`Sqlite` 's implementation of `AuthorRepository` knows all about SQLite error codes, and transforms any error corresponding to a duplicate author into the domain's preferred representation [`18`](https://www.howtocodeit.com/articles/#code-ref-18).
|
||||
|
||||
Of course, `Sqlite`, not being part of the domain's Garden of Eden, may encounter an error that the domain can't do much with [`19`](https://www.howtocodeit.com/articles/#code-ref-19).
|
||||
|
||||
This is a `500 Internal Server Error` in the making, but repositories shouldn't know about HTTP status codes. We need to pass it back up the chain in the form of `CreateAuthorError::Unknown`, both to inform the end user that something fell over, and to capture for debugging.
|
||||
|
||||
This is a situation that the program – or at least the request handler – can't recover from. Couldn't we `panic`? The domain can't do anything useful here, so why not skip the middleman and let the panic recovery middleware handle it?
|
||||
|
||||
#### Don't panic
|
||||
|
||||
Until very recently, I would have said yes – if the domain can't do any useful work with an error, panicking will save you from duplicating error handling logic between your request handler and your panic-catching middleware.
|
||||
|
||||
However, thanks to [a comment from matta](https://www.howtocodeit.com/articles/master-hexagonal-architecture-rust#discussion) and a horrible realization I had in the shower, I've reversed my position.
|
||||
|
||||
Whether or not you consider the database falling over a recoverable error, there are two incontrovertible reasons not to panic:
|
||||
|
||||
1. Panicking poisons held mutexes. If your application state is protected by an `Arc<Mutex<T>>`, panicking while you hold the guard will mean no other thread will ever be able to acquire it again. Your program is dead, and no amount of panic recovery middleware will bring it back.
|
||||
2. Other Rust devs won't expect you to panic. Most likely, you won't be the person woken at 3am to debug your code. Strive to make it as unsurprising as possible. Follow established error handling conventions diligently. Return errors, don't panic.
|
||||
|
||||
What about retry handling? Good question. We'll cover that in [Part V: *Advanced Hexagonal Architecture in Rust*](https://www.howtocodeit.com/articles/#advanced-hexagonal-architecture-in-rust).
|
||||
|
||||
### Everything but the kitchen async
|
||||
|
||||
Have you spotted it? The mismatch between our repository implementation and the trait definition.
|
||||
|
||||
Ok, you caught me. I simplified the definition of `AuthorRepository`. There's actually more to it, because of course we want database calls to be async.
|
||||
|
||||
Writing to a file or calling a database server is precisely the kind of slow, blocking IO that we don't want to stall on.
|
||||
|
||||
We need to make `AuthorRepository` an async trait. Unfortunately, it's not quite as simple as writing
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository { async fn create_author( &self, req: &CreateAuthorRequest, ) -> Result<Author, CreateAuthorError>>;}
|
||||
```
|
||||
|
||||
Rust understands this, and it will compile, but probably won't do what you expect.
|
||||
|
||||
Although writing `async fn` will cause your method's return value to be sugared into `Future<Output = Result<Author, CreateAuthorError>>`, it *won't* get an automatic `Send` bound.
|
||||
|
||||
As a result, your future can't be sent between threads. For web applications, this is useless.
|
||||
|
||||
Let's spell things out for the compiler!
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository { fn create_author( &self, req: &CreateAuthorRequest, ) -> impl Future<Output = Result<Author, CreateAuthorError>> + Send;20}
|
||||
```
|
||||
|
||||
Since our `Author` and `CreateAuthorError` are both `Send`, a `Future` that wraps them can be too [`20`](https://www.howtocodeit.com/articles/#code-ref-20).
|
||||
|
||||
But what good is a repository if its methods return thread-safe `Future` s, but the repo itself is bound to a single thread? Let's ensure `AuthorRepository` is `Send` too.
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Send { // ...}
|
||||
```
|
||||
|
||||
Ugh, we're not done. Remember about 4,000 words ago when we wrapped our application state in an `Arc` to inject into an HTTP handler? Well, trust me, we did.
|
||||
|
||||
`Arc` requires its contents to be both `Send` and `Sync` to be either `Send` *or* `Sync` itself! [Here's a good discussion](https://stackoverflow.com/questions/41909811/why-does-arct-require-t-to-be-both-send-and-sync-in-order-to-be-send) on the topic if you'd like to know more.
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Send + Sync { // ...}
|
||||
```
|
||||
|
||||
Your instinct might now be to implement `AuthorRepository` for `&Sqlite` instead of `Sqlite`, since `&T` is immutable and therefore `Send + Sync`. However, sqlx's connection pools are themselves `Send + Sync`, meaning `Sqlite` is too.
|
||||
|
||||
Are we done yet?
|
||||
|
||||
🙃
|
||||
|
||||
Naturally, if we're shuffling a repo between threads, Rust wants to be sure it won't be dropped unexpectedly. Let's reassure the compiler that every `AuthorRepository` will live for the whole program:
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Send + Sync + 'static { // ...}
|
||||
```
|
||||
|
||||
Finally, our web server, axum, requires injected data to be `Clone`, giving our final trait definition:
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Clone + Send + Sync + 'static { /// Asynchronously persist a new [Author]. /// /// # Errors /// /// - MUST return [CreateAuthorError::Duplicate] if an [Author] with the same [AuthorName] /// already exists. fn create_author( &self, req: &CreateAuthorRequest, ) -> impl Future<Output = Result<Author, CreateAuthorError>> + Send;}
|
||||
```
|
||||
|
||||
### From the Very Bad Application to the merely Bad Application
|
||||
|
||||
It's time to start putting these pieces together. Let's reassemble our `create_author` HTTP handler to take advantage of the `AuthorRepository` abstraction.
|
||||
|
||||
First, the definition of `AppState`, which is the struct that contains the resources that should be available to every HTTP handler. This pattern should be familiar to users of both [axum](https://docs.rs/axum/latest/axum/) and [Actix Web](https://actix.rs/).
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]/// The application state available to all request handlers.struct AppState<AR: AuthorRepository> { author_repo: Arc<AR>,21}
|
||||
```
|
||||
|
||||
`AppState` is now generic over `AuthorRepository`. That is, `AppState` provides HTTP handlers with access to "some store of author data", giving them the ability to create authors without knowledge of the implementation.
|
||||
|
||||
We wrap whatever instance of `AuthorRepository` we receive in an `Arc`, because axum is going to share it between as many async tasks as there are requests to our application.
|
||||
|
||||
This isn't our final destination – eventually our HTTP handler won't even know it has to save something (ah, sweet oblivion).
|
||||
|
||||
We're not quite there yet, but this is a vast improvement. Check out the handler!
|
||||
|
||||
```
|
||||
rustpub async fn create_author<AR: AuthorRepository>( State(state): State<AppState<AR>>,22 Json(body): Json<CreateAuthorHttpRequestBody>,) -> Result<ApiSuccess<CreateAuthorResponseData>, ApiError> { let domain_req = body.try_into_domain()?;23 state .author_repo .create_author(&domain_req) .await .map_err(ApiError::from)24 .map(|ref author| ApiSuccess::new(StatusCode::CREATED, author.into()))25}
|
||||
```
|
||||
|
||||
Oh my.
|
||||
|
||||
Isn't it beautiful?
|
||||
|
||||
Doesn't your nervous system feel calmer to behold it?
|
||||
|
||||
Go on, take some deep breaths. Enjoy the moment. [Here's the crime scene we started from](https://www.howtocodeit.com/articles/master-hexagonal-architecture-rust#code-ref-5) if you need a reminder.
|
||||
|
||||
Ok, the walkthrough. `create_author` has access to an `AuthorRepository` [`22`](https://www.howtocodeit.com/articles/#code-ref-22), which it makes good use of. But first, it converts the raw `CreateAuthorHttpRequestBody` it received from the client into the holy domain representation [`23`](https://www.howtocodeit.com/articles/#code-ref-23). Here's how:
|
||||
|
||||
```
|
||||
rust/// The body of an [Author] creation request.#[derive(Debug, Clone, PartialEq, Eq, Deserialize)]pub struct CreateAuthorHttpRequestBody { name: String,}
|
||||
impl CreateAuthorHttpRequestBody { /// Converts the HTTP request body into a domain request. fn try_into_domain(self) -> Result<CreateAuthorRequest, AuthorNameEmptyError> { let author_name = AuthorName::new(&self.name)?; Ok(CreateAuthorRequest::new(author_name)) }}
|
||||
```
|
||||
|
||||
Nothing fancy! Boilerplatey, you might think. This is by design. We have preemptively decoupled the HTTP API our application exposes to the world from the internal domain representation.
|
||||
|
||||
As you scale, you will thank this so-called boilerplate. You will name your firstborn child for it.
|
||||
|
||||
These two things can now change independently. Changing the domain doesn't necessarily force a new web API version. Changing the HTTP request structure does not require any change to the domain. Only the mapping in `CreateAuthorHttpRequestBody::into_domain` and its corresponding unit tests get updated.
|
||||
|
||||
This is a very special property. Changes to transport concerns or business logic no longer spread through your program like wildfire. Abstraction has been achieved.
|
||||
|
||||
Thanks to the pains we took to define all the errors an `AuthorRepository` is allowed to return, constructing an HTTP response is dreamy. In the error case, we map seamlessly to a serializable `ApiError` using `ApiError::from` [`24`](https://www.howtocodeit.com/articles/#code-ref-24):
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone, PartialEq, Eq)]pub enum ApiError { InternalServerError(String),26 UnprocessableEntity(String),27}
|
||||
impl From<CreateAuthorError> for ApiError { fn from(e: CreateAuthorError) -> Self { match e { CreateAuthorError::Duplicate { name } => { Self::UnprocessableEntity(format!("author with name {} already exists", name))28 } CreateAuthorError::Unknown(cause) => { tracing::error!("{:?}\n{}", cause, cause.backtrace()); Self::InternalServerError("Internal server error".to_string()) } } }}
|
||||
impl From<AuthorNameEmptyError> for ApiError { fn from(_: AuthorNameEmptyError) -> Self { Self::UnprocessableEntity("author name cannot be empty".to_string()) }}
|
||||
```
|
||||
|
||||
If the author was found to be a duplicate, it means the client's request was correctly structured, but that the contents were unprocessable. Hence, we're aiming to respond `422 Unprocessable Entity` [`27`](https://www.howtocodeit.com/articles/#code-ref-27).
|
||||
|
||||
Important detail alert! Do you see how we're manually building an error message at [`28`](https://www.howtocodeit.com/articles/#code-ref-28), even though `CreateAuthorError::to_string` could have produced this error for us?
|
||||
|
||||
This is another instance of aggressive decoupling of our transport concern (JSON over HTTP) from the domain. Returning full-fat, unpasteurised domain errors to users is an easy way to leak private details of your application. It also results in unexpected changes to HTTP responses when domain implementation details change!
|
||||
|
||||
If we get an error the domain didn't expect – `CreateAuthorError::Unknown` here – that maps straight to `InternalServerError` [`26`](https://www.howtocodeit.com/articles/#code-ref-26).
|
||||
|
||||
The finer points of how you log the underlying cause will vary according to your needs. Crucially, however, the error itself is not exposed to the end user.
|
||||
|
||||
Finally, our success case [`25`](https://www.howtocodeit.com/articles/#code-ref-25). We take a reference to the returned `Author` and transform it into its public API counterpart. It gets sent on its way with status `201 Created`.
|
||||
|
||||
```
|
||||
rust/// The response body data field for successful [Author] creation.#[derive(Debug, Clone, PartialEq, Eq, Serialize)]pub struct CreateAuthorResponseData { id: String,}
|
||||
impl From<&Author> for CreateAuthorResponseData { fn from(author: &Author) -> Self { Self { id: author.id().to_string(), } }}
|
||||
```
|
||||
|
||||
Chef's kiss. 🧑🍳
|
||||
|
||||
### Testing HTTP handlers with injected repositories
|
||||
|
||||
Oh, it gets better.
|
||||
|
||||
Previously, our handler code was impossible to unit test, because we needed a real database instance to call them. Trying to exercise every failure mode of a database call with a real database is pure pain.
|
||||
|
||||
Those days are over. By injecting any type that implements `AuthorRepository`, we open our HTTP handlers to unit testing with mock repositories.
|
||||
|
||||
```
|
||||
rust#[cfg(test)]mod tests { // Imports omitted.
|
||||
#[derive(Clone)] struct MockAuthorRepository { create_author_result: Arc<Mutex<Result<Author, CreateAuthorError>>>,29 }
|
||||
impl AuthorRepository for MockAuthorRepository { async fn create_author( &self, _: &CreateAuthorRequest, ) -> Result<Author, CreateAuthorError> { let mut guard = self.create_author_result.lock().await; let mut result = Err(CreateAuthorError::Unknown(anyhow!("substitute error"))); mem::swap(guard.deref_mut(), &mut result); result30 } }}
|
||||
```
|
||||
|
||||
`MockAuthorRepository` is defined to hold the `Result` it should return in response `AuthorRepository::create_author` calls [`29`](https://www.howtocodeit.com/articles/#code-ref-29) [`30`](https://www.howtocodeit.com/articles/#code-ref-30).
|
||||
|
||||
The rather nasty type signature at [`29`](https://www.howtocodeit.com/articles/#code-ref-29) is due to the fact that `AuthorRepository` has a `Clone` bound, which means `MockAuthorRespository` must be `Clone`.
|
||||
|
||||
Unfortunately for us, `CreateAuthorError` isn't `Clone`, because its `Unknown` variant contains `anyhow::Error`. `anyhow::Error` isn't `Clone` since it's designed to wrap unknown errors, which may not be `Clone` themselves. `std::io::Error` is one common non- `Clone` error.
|
||||
|
||||
Rather than passing `MockAuthorRepository` a convenient `Result<Author, CreateAuthorError>`, we need to give it something cloneable – `Arc`. But, as discussed, `Arc` 's contents need to be `Send + Sync` for `Arc` to be `Send + Sync`, so we're forced to wrap the `Result` in a `Mutex`. (I'm using a `tokio::sync::Mutex` here, hence the `await`, but `std::sync::Mutex` also works with minor changes to the supporting code).
|
||||
|
||||
The mock implementation of `create_author` then deals with swapping a dummy value with the real result in order to return it to the test caller.
|
||||
|
||||
Here's the test for the case where the repository call succeeds. I leave the error case to your powerful imagination, but if you crave more Rust testing pearls, I'll have a comprehensive guide to unit testing for you soon!
|
||||
|
||||
```
|
||||
rust#[tokio::test(flavor = "multi_thread")]async fn test_create_author_success() { let author_name = AuthorName::new("Angus").unwrap(); let author_id = Uuid::new_v4(); let repo = MockAuthorRepository {31 create_author_result: Arc::new(Mutex::new(Ok(Author::new( author_id, author_name.clone(), )))), }; let state = axum::extract::State(AppState { author_repo: Arc::new(repo), }); let body = axum::extract::Json(CreateAuthorHttpRequestBody { name: author_name.to_string(), }); let expected = ApiSuccess::new(32 StatusCode::CREATED, CreateAuthorResponseData { id: author_id.to_string(), }, );
|
||||
let actual = create_author(state, body).await;33 assert!( actual.is_ok(), "expected create_author to succeed, but got {:?}", actual );
|
||||
let actual = actual.unwrap(); assert_eq!( actual, expected, "expected ApiSuccess {:?}, but got {:?}", expected, actual )}
|
||||
```
|
||||
|
||||
At [`31`](https://www.howtocodeit.com/articles/#code-ref-31), we construct a `MockAuthorRepository` with an arbitrary success `Result`. We expect that a `Result::Ok(Author)` from the repo should produce a `Result::Ok(ApiSuccess<CreateAuthorResponseData>)` from the handler [`32`](https://www.howtocodeit.com/articles/#code-ref-32).
|
||||
|
||||
This situation is simple to set up – we just call the `create_author` handler with a `State` object constructed from the `MockAuthorRepository` in place of a real one [`33`](https://www.howtocodeit.com/articles/#code-ref-33). The assertions are self-explanatory.
|
||||
|
||||
I know, I know – you're itching to see what `main` looks like with these improvements, but we're about to take a much bigger and more important leap in our understanding of hexagonal architecture.
|
||||
|
||||
In Part III, coming next, I'll introduce you to the beating heart of an application domain: the `Service`.
|
||||
|
||||
We'll ratchet up the complexity of our example application to understand how to set domain boundaries. We'll confront the tricky problem of *master records* through the lens of authentication, and explore the interface between hexagonal applications and distributed systems.
|
||||
|
||||
And yes, we'll finally answer, "why hexagons?".
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
Part III
|
||||
|
||||
## Service, the heart of hexagonal architecture
|
||||
|
||||
### Introducing the Service trait
|
||||
|
||||
The `Repository` trait does a great job at getting datastore implementation details out of code that handles incoming requests.
|
||||
|
||||
If our application really was as simple as the one I've described so far, this would be good enough.
|
||||
|
||||
But most real applications aren't this simple, and their domain logic involves more than writing to a database and responding `201`.
|
||||
|
||||
For example, each time a new author is successfully created, we may want to dispatch an event for other parts of our system to consume asynchronously.
|
||||
|
||||
Perhaps we want to track metrics related to author creation in a time series database like Prometheus? Or send a welcome email?
|
||||
|
||||
This sequence of conditional steps is domain logic. We've already seen that domain logic doesn't belong in adapters. Otherwise, when you swap out the adapter, you have to rewrite domain code that has nothing to do with the adapter implementation.
|
||||
|
||||
So, domain logic can't go in our HTTP handler, and it can't go in our `AuthorRepository`. Where does it live?
|
||||
|
||||
A `Service`.
|
||||
|
||||
A `Service` refers to both a trait that declares the methods of your business API, and an implementation that's provided by the domain to your inbound adapters.
|
||||
|
||||
It encapsulates calls to databases, sending of notifications and collection of metrics from your handlers behind a clean, mockable interface.
|
||||
|
||||
Currently, our axum application state looks like this:
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]/// The application state available to all request handlers.struct AppState<AR: AuthorRepository> { author_repo: Arc<AR>,}
|
||||
```
|
||||
|
||||
Let's spice up our application with some more domain traits:
|
||||
|
||||
```
|
||||
rust
|
||||
```
|
||||
|
||||
Together with `AuthorRepository`, these ports illustrate the kinds of dependencies you might expect of a real production app.
|
||||
|
||||
`AuthorMetrics` [`34`](https://www.howtocodeit.com/articles/#code-ref-34) describes an aggregator of author-related metrics, such as a time-series database. `AuthorNotifier` [`35`](https://www.howtocodeit.com/articles/#code-ref-35) triggers notifications to authors.
|
||||
|
||||
Rather than stuffing these domain dependencies into `AppState` directly, we're aiming for this:
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]/// The application state available to all request handlers.struct AppState<AS: AuthorService> { author_service: Arc<AS>,}
|
||||
```
|
||||
|
||||
How do we get there? Let's start with the `Service` trait definition:
|
||||
|
||||
```
|
||||
rustpub trait AuthorService: Clone + Send + Sync + 'static { /// Asynchronously create a new [Author]. /// /// # Errors /// /// - [CreateAuthorError::Duplicate] if an [Author] with the same [AuthorName] already exists. fn create_author( &self, req: &CreateAuthorRequest, ) -> impl Future<Output = Result<Author, CreateAuthorError>> + Send;}
|
||||
```
|
||||
|
||||
Much like `AuthorRepository`, the `Service` trait has an async method, `create_author`, that takes a `CreateAuthorRequest` by reference and returns a `Future` that outputs either an `Author`, if creation was successful, or a `CreateAuthorError` if not.
|
||||
|
||||
Although the signatures of `AuthorService` and `AuthorRepository` look similar, this is a byproduct of a simple domain. They aren't required to match, and by separating our concerns with traits in this way, we allow them to diverge in future.
|
||||
|
||||
Now, the implementation of `AuthorService`:
|
||||
|
||||
```
|
||||
rust/// Canonical implementation of the [AuthorService] port, through which the author domain API is/// consumed.#[derive(Debug, Clone)]pub struct Service<R, M, N>36where R: AuthorRepository, M: AuthorMetrics, N: AuthorNotifier,{ repo: R, metrics: M, notifier: N,}
|
||||
// Constructor implementation omitted
|
||||
impl<R, M, N> AuthorService for Service<R, M, N>where R: AuthorRepository, M: AuthorMetrics, N: AuthorNotifier,{ /// Create the [Author] specified in \`req\` and trigger notifications. /// /// # Errors /// /// - Propagates any [CreateAuthorError] returned by the [AuthorRepository]. async fn create_author(&self, req: &CreateAuthorRequest) -> Result<Author, CreateAuthorError> { let result = self.repo.create_author(req).await;37 if result.is_err() { self.metrics.record_creation_failure().await; } else { self.metrics.record_creation_success().await; self.notifier.author_created(result.as_ref().unwrap()).await; }
|
||||
result }}
|
||||
```
|
||||
|
||||
The `Service` struct encapsulates the dependencies required to execute our business logic [`36`](https://www.howtocodeit.com/articles/#code-ref-36).
|
||||
|
||||
The implementation of `AuthorService::create_author` [`37`](https://www.howtocodeit.com/articles/#code-ref-37) illustrates why we don't want to embed these calls directly in handler code, which has enough work to do just managing the request-response cycle.
|
||||
|
||||
First, we call the `AuthorRepository` to persist the new author, then we branch. On a failed repository call, we call `AuthorMetrics` to track the failure. On success, we submit success metrics, then trigger notifications. In both cases, we propagate the repository `Result` to the caller.
|
||||
|
||||
I defined the `AuthorMetrics` and `AuthorNotifier` methods as infallible, since metric aggregation and notification dispatch typically takes place concurrently, with separate error handling paths.
|
||||
|
||||
Not always, though. Imagine if the metrics and notifier calls also returned errors. Suddenly, our test scenarios include:
|
||||
|
||||
- Calls to all three dependencies succeed.
|
||||
- The repo call fails, and the metrics call fails too.
|
||||
- The repo call fails, and the metrics call succeeds.
|
||||
- The repo call succeeds, but the metrics fall over.
|
||||
- The repo and metrics calls succeed, but the notifier returns an error.
|
||||
|
||||
Now picture every permutation of these cases with all of the `Result` s produced when receiving, parsing and responding to HTTP requests 🤯.
|
||||
|
||||
This is what happens if you stick domain logic in your handlers. Without a `Service` abstraction, you have to *integration* test this hell.
|
||||
|
||||
Nope. No. Not today, thank you.
|
||||
|
||||
To test handlers that call a `Service`, you just mock the service, returning whatever success or error variant you need to check the handler's output.
|
||||
|
||||
To test a `Service`, you mock each of its dependencies, returning the successes and errors required to exercise all of the paths described above.
|
||||
|
||||
Finally, you integration test the whole system, focusing on your happy paths and the most important error scenarios.
|
||||
|
||||
Paradise 🌅.
|
||||
|
||||
Now you know how to wrap your domain's dependencies in a `Service`, and you're happy that it's the service that gets injected into our handlers in `AppState`, let's check back in on `main`.
|
||||
|
||||
### main is for bootstrapping
|
||||
|
||||
The only responsibilities of your `main` function are to bring your application online and clean up once it's done.
|
||||
|
||||
Some developers delegate bootstrapping to a `setup` function that does the hard work and passes the result back to `main`, which just decides how to exit. This works too, and the differences don't matter for this discussion.
|
||||
|
||||
`main` must construct the `Service` s required by the application, inject them into our handlers, and set the whole program in motion:
|
||||
|
||||
```
|
||||
rust
|
||||
```
|
||||
|
||||
To do this, `main` needs to know which adapters to slot into the domain's ports [`38`](https://www.howtocodeit.com/articles/#code-ref-38). This example uses an SQLite `AuthorRepository`, Prometheus `AuthorMetrics` and an email-based `AuthorNotifier`.
|
||||
|
||||
It combines these implementations of the domain traits into an `AuthorService` [`39`](https://www.howtocodeit.com/articles/#code-ref-39) using the author domain's `Service` constructor.
|
||||
|
||||
Finishing up, it injects the `AuthorService` into an HTTP server and runs it [`40`](https://www.howtocodeit.com/articles/#code-ref-40).
|
||||
|
||||
Even though `main` knows which adapters we want to use, we still aim to not leak implementation details of third-party crates. Here are the `use` statements for this `main.rs` file:
|
||||
|
||||
```
|
||||
rustuse hexarch::config::Config;use hexarch::domain::author::service::Service;use hexarch::inbound::http::{HttpServer, HttpServerConfig};use hexarch::outbound::email_client::EmailClient;use hexarch::outbound::prometheus::Prometheus;use hexarch::outbound::sqlite::Sqlite;
|
||||
```
|
||||
|
||||
This is all proprietary to our application. Even though we're using an axum HTTP server, `main` doesn't know about axum.
|
||||
|
||||
Instead, we've created our own `HttpServer` wrapper around axum that exposes only the functionality the rest of the application needs.
|
||||
|
||||
Configuration of routes, ports, timeouts, etc. lives in a predictable place isolated from unrelated code. If axum were to make changes to its API, we'd need to update our `HttpServer` internals, but they'd be invisible to main.
|
||||
|
||||
There's another motivating factor behind this: `main` is pretty resistant to testing. It composes unmockable dependencies and handles errors by logging to stdout and exiting. The less code we put here, the smaller this testing dead zone.
|
||||
|
||||
Setup and configuration for integration tests is often subtly different from `main`, too. Imagine having to configure all the routes and middleware for an axum server separately for `main` and tests. What a chore!
|
||||
|
||||
By defining our own `HttpServer` type, both `main` and tests can easily spin up our app's server with the config they require. No duplication.
|
||||
|
||||
### Why hexagons?
|
||||
|
||||
Ok, it's time. It's actually happening.
|
||||
|
||||
I've shown you the key, practical components of hexagonal architecture: services, ports, adapters, and the encapsulation of third-party dependencies.
|
||||
|
||||
Now some theory – why hexagons?
|
||||
|
||||
Well, I hate to break it to you, but hexagons aren't special. There's no six-sided significance to hexagonal architecture. The truth is, any polygon will do.
|
||||
|
||||
Hexagonal architecture was [originally proposed by Alistair Cockburn](https://alistair.cockburn.us/hexagonal-architecture/), who chose hexagons to represent the way adapters surround the business domain at the core of the application. The symmetry of hexagons also reflects the duality of inbound and outbound adapters.
|
||||
|
||||
I've been holding off on a classic hexagonal architecture diagram until I showed you how the ports and adapters compose. Here you go:
|
||||
|
||||
|
||||
|
||||
A schematic representation of hexagonal architecture
|
||||
|
||||
The outside world is a scary, ever-changing place. Anything can go wrong at any time.
|
||||
|
||||
Your domain logic, on the other hand, is a calm and tranquil glade. It changes if, and only if, the requirements of your business change.
|
||||
|
||||
The adapters are the bouncers enforcing the domain's dress code on anything from the outside that wants to get in.
|
||||
|
||||
### How to choose the right domain boundaries
|
||||
|
||||
What belongs in a domain? What models and ports should it include? How many domains should a single application have?
|
||||
|
||||
These are the questions many people struggle with when adopting hexagonal architecture, or domain-driven design more generally.
|
||||
|
||||
I've got good news and bad news 💁.
|
||||
|
||||
The bad news is that I can't answer these questions for you, because they depend heavily on variables like your scale, your overall system architecture and your requirements around synchronicity.
|
||||
|
||||
The good news is, I have two powerful rules of thumb to help you make the right decision, and we'll go through some examples together.
|
||||
|
||||
Firstly, a domain represents some tangible arm of your business.
|
||||
|
||||
I've been discussing an "author domain", because a using single-entity domain makes it easier to teach the concepts of hexagonal architecture.
|
||||
|
||||
For a small blogging app, however, it's likely that a single "blog domain" would be the correct boundary to draw, since there is only one business concern – running a blog.
|
||||
|
||||
For a site like Medium, there would be multiple domains: blogging, user identity, billing, customer support, and so on. These are related but distinct business functions, that communicate using each other's `Service` APIs.
|
||||
|
||||
If this is starting to sound like microservices to you, you're not imagining things. We'll talk about the relationship between hexagonal architecture and microservices in Part IV.
|
||||
|
||||
Secondly, a domain should include all entities that must change together as part of a single, atomic operation.
|
||||
|
||||
Consider our blogging app. The author domain manages the lifecycle of an `Author`. But what about blog posts?
|
||||
|
||||
If an `Author` is deleted, do we require that all of their posts are deleted atomically, or is it acceptable for their posts to be accessible for a short time after the deletion of the author?
|
||||
|
||||
In the first case, authors and posts *must* be part of the same domain, since the deletion of an author must be atomic with the deletion of their blog posts.
|
||||
|
||||
In the second case, authors and posts could *theoretically* be represented as separate domains, which communicate to coordinate deletion events.
|
||||
|
||||
This communication could be synchronous (the author domain calls and awaits `PostService::delete_by_author_id` ) or asynchronous (the author domain pushes some `AuthorDeletionEvent` onto a message queue, for the post domain to process later).
|
||||
|
||||
Neither of these cases are atomic. Business logic, being unaware of repository implementation details, has no concept of transactions in the SQL sense.
|
||||
|
||||
If you find that you're leaking transactions into your business logic to perform cross-domain operations atomically, your domain boundaries are wrong. Cross-domain operations are never atomic. These entities should be part of the same domain.
|
||||
|
||||
#### Start with large domains
|
||||
|
||||
According to the first rule of thumb, we wouldn't actually want to separate authors and posts into different domains. They're part of the same business function, and cross-domain communication complicates your application. It has to be worth the cost.
|
||||
|
||||
We're happy to pay this cost when different parts of our business rely on each other, but need to change often and independently. We don't want these domains to be tightly coupled.
|
||||
|
||||
Identifying these related but independent components is an ongoing, iterative process based on the friction you experience as your application grows.
|
||||
|
||||
This is why starting with a single, large domain is preferable to designing many small ones upfront.
|
||||
|
||||
If you jump the gun and build a fragmented system before you have first-hand experience of the points of friction in both the system and the business, you pay a huge penalty.
|
||||
|
||||
You must write and maintain the glue code for inter-domain communication before you know if it's needed. You sacrifice atomicity which you might later find you need. You will have to undo this work and merge domains when your first guess at domain boundaries is inevitably wrong.
|
||||
|
||||
A fat domain makes no assumptions about how different business functions will evolve over time. It can be decomposed as the need arises, and maintains all the benefits of easy atomicity until that time comes.
|
||||
|
||||
#### Authentication and authorization with hexagonal architecture
|
||||
|
||||
I was deliberate in choosing `Author` s rather than `User` s for our example application. If you're used to working on smaller, monolithic apps, it's not obvious where entities like `User` s belong in hexagonal architecture.
|
||||
|
||||
If you're comfortable in a microservices context, you'll have an easier time.
|
||||
|
||||
The primary entity for authentication and authorization will "own" many other entities. A `User` for a social network will own one or more `Profile` s, `Settings`, `Subscription` s, `AccountStatus` es, and so on. All of these, and all the data that they own in turn, are traceable back to the `User`.
|
||||
|
||||
If we follow our rule of thumb – that entities that change together atomically belong in the same domain – the presence of master records causes *everything* to belong in the same domain. If you delete a `User`, and require synchronous deletion of related entities, everything must be deleted in the same, atomic operation.
|
||||
|
||||
Isn't this the same as having no domain boundaries at all?
|
||||
|
||||
For a small to medium application, where you roll your own auth and aren't expecting massive growth, this is fine. Overly granular domains will cause you more problems than they solve.
|
||||
|
||||
However, for larger applications and apps that use third-party auth providers like Auth0, a single domain is unworkable.
|
||||
|
||||
The `User` entity and associated auth code should live in its own domain, with entities in other domains retaining a unique reference to the owner. Then, depending on your level of scale, deletions can happen in two ways:
|
||||
|
||||
- Synchronously, with the auth domain calling each of the other domains' `Service::delete_by_user_id` methods.
|
||||
- Asynchronously, where the auth domain publishes a deletion event for other domains to process on their own time.
|
||||
|
||||
Neither of these scenarios is atomic.
|
||||
|
||||
Regardless of what architecture you use, atomic deletion of a `User` and all their dependent records get taken off the table once you reach a certain scale. Hexagonal architecture just makes this explicit.
|
||||
|
||||
To use an extreme example, deletion of a Facebook account, including everything it has ever posted, [takes up to 90 days](https://www.facebook.com/help/224562897555674) (including a 30-day grace period). Even then, copies may remain in backups.
|
||||
|
||||
In addition to the vast volume of data to be processed, there will be a huge amount of internal and regulatory process to follow in the course of this deletion. This can't be modeled as an atomic operation.
|
||||
|
||||
### A Rust project template for hexagonal architecture
|
||||
|
||||
Until now, I've avoided discussing module paths and file structures because I didn't want to distract from the core concepts of domains, ports and adapters.
|
||||
|
||||
Now you have the full picture, I'll let you explore [this example repository](https://github.com/howtocodeit/hexarch) at your leisure and take inspiration from its folder structure.
|
||||
|
||||
Branch `3-simple-service` contains the code we've discussed in part three of this guide, and provides a basic but representative example of a hexagonal app.
|
||||
|
||||
Dividing `src/lib` into `domain` (for business logic) `inbound` and `outbound` (for adapters) has worked well at scale for several teams I've been part of. It's not sacred though. How you name these modules and the level of granularity you choose should suit your own needs.
|
||||
|
||||
All I ask is that, whatever convention you adopt, you document it for both new and existing team members to refer to.
|
||||
|
||||
Document your decisions, *I beg you*.
|
||||
|
||||
### Make an informed decision
|
||||
|
||||
In Part IV, we'll be discussing the trade-offs of using hexagonal architecture compared with other common architectures, and see how it simplifies the jump to microservices when the time is right.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
### Put down the Kool-Aid
|
||||
|
||||
By this point in the guide, you likely fall into one of two camps.
|
||||
|
||||
In the first camp, my converts have sold their possessions and donated the proceeds to the six-sided church. They gather round the fire to sing songs in praise of Hexagonal Architecture, hallowed be its name.
|
||||
|
||||
Across the creek, the second camp hunger for blood. Triggered by the structure, formality and upfront complexity of hexagonal architecture, they prepare to sacrifice the false idol on the bonfire of software engineering trends. They're incensed by the suggestion that hexagonal architecture is superior to others.
|
||||
|
||||
Each camp checks its map of the software development landscape, seeking the most effective path to destroy the other. To their surprise, however, the map shows nothing but a great swamp, without end or beginning. This is "The Middle Ground".
|
||||
|
||||
### Strengths and weaknesses of hexagonal architecture
|
||||
|
||||
Hexagonal architecture is a power tool. It's the hydraulic press of software architectures, and whether it's the optimal architecture for you depends on whether you want to crush a car or a Coke can.
|
||||
|
||||
Parts I to III showed off the strengths of hexagonal architecture:
|
||||
|
||||
- It's highly decoupled, making it a pleasure to evolve and scale.
|
||||
- It greatly increases your unit test surface for rigorous testing of code with complex failure modes.
|
||||
- There's a single source of truth for the logic of each business domain, with a correspondingly simple dependency graph.
|
||||
- There's a home for everything. A predictable project structure keeps your code organized and your team happy.
|
||||
|
||||
Nothing comes for free, though. What are the costs?
|
||||
|
||||
Compared to the Very Bad Application [`1`](https://www.howtocodeit.com/articles/#code-ref-1), our hexagonal app takes a lot more code to achieve the same result. Instead of a raw, axum HTTP handler that simply takes the request body and shoves it straight into an SQLite database, we have multiple layers of abstraction:
|
||||
|
||||
- axum becomes an implementation detail, concealed by our own HTTP package.
|
||||
- The request body must be converted to a domain representation before we can work with it.
|
||||
- Business logic is encapsulated by the `Service` trait and injected into the handler.
|
||||
- SQLite is an implementation detail hidden behind a repository trait implementation.
|
||||
- Anything we pull out of the database has to be converted to a domain representation before it can be used.
|
||||
|
||||
This isn't boilerplate. It's not useless filler. All this extra code is required to achieve the benefits listed above. But clearly there's a threshold below which you'll spend more time writing abstractions and transformations than you'll save through easy scaling and fewer production incidents.
|
||||
|
||||
Translations from transport data types to domain data types aren't free, either. For many apps, the cost is negligible – a tiny fraction of the compute required by the business logic. But for some apps this matters. For embedded software, every byte of memory might count. High-performance systems, such as high-frequency trading software, sacrifice readability for speed. Hexagonal architecture would be a poor fit.
|
||||
|
||||
Let's not forget the barrier to entry. Here we are, thousands of words deep into a hexagonal architecture tutorial. Getting it right requires time and space for active learning. Sustaining a hexagonal codebase requires a clear technical vision and a well-trained team. *Everyone* must understand the rationale and implementation of the architecture.
|
||||
|
||||
Most tech companies fail to invest in their people this way. The training and development available to professional software engineers is dire, and initiatives like adopting hexagonal architecture are led by evangelists learning on their own time. Sadly, they're doomed to fail, because building this way requires a culture that gets everyone on the same page.
|
||||
|
||||
Assuming I haven't scared you off, let's go through some examples to help you decide if hexagonal architecture is right for you.
|
||||
|
||||
#### Solo developers and personal projects
|
||||
|
||||
If you're in the blessed position of being able to keep your entire codebase in your head – and you don't plan to share it – hexagonal architecture will slow you down.
|
||||
|
||||
As a solo dev, you'll have a clear idea of how likely you are to swap out your database, introduce async messaging or migrate to RPC from REST (probably never). And what good will increasing your test surface do if you can just eyeball your app to see that it's working?
|
||||
|
||||
In this scenario, abstractions like services and repositories make your code *more* fragile, not less. It's more code to mentally account for, with no practical upside.
|
||||
|
||||
However, I do recommend small, personal projects as playgrounds to learn and experiment with hexagonal architecture. Building a complete application, even a trivial one, will develop your ability to think hexagonally.
|
||||
|
||||
Legacy code is created by engineers learning new techniques on the job. Take the time to build your intuition in a low-stakes environment. Go deep on details like domain boundaries and error handling. Write *better-than-production* code at home, then bring your expertise to work.
|
||||
|
||||
#### Applications with little business logic
|
||||
|
||||
Does your program tick along happily on an eighth of a vCPU? Is it a lightweight CRUD app that just writes what it's given and reads what it's asked for? Is deserializing a kilobyte of JSON the most ambitious thing it's done this week?
|
||||
|
||||
Don't overcomplicate things. Apps that don't have any business logic don't need ports and adapters – there's nothing to encapsulate.
|
||||
|
||||
If you're compelled to test your request handlers in isolation from your data store, you might still consider using the repository pattern. On the other hand, if your app is so basic that this would be more effort than comprehensively integration testing, int test instead.
|
||||
|
||||
#### Startups that want to scale hard
|
||||
|
||||
You're a one-man band or a small team. Your code just about fits in your head, and the business logic doesn't do anything crazy. But you've got dreams. You want to take this all the way, and you need a rocket to get you there.
|
||||
|
||||
Build hexagonally. If you can do this from day one, all the better. Don't find yourself cruising towards your series A with the engines on fire and half your dev team trying to put it out.
|
||||
|
||||
Hexagonal architecture gives you comprehensive test coverage from the start. It allows you to make the wrong choice of database and spring gracefully away from danger. It lets you support new customer needs without mangling what already works. It's not just an architecture *of* scale, it's an architecture *for scaling*.
|
||||
|
||||
Hexagonal architecture also saves you from true folly – launching your product as microservices.
|
||||
|
||||
In ["How to choose the right domain boundaries"](https://www.howtocodeit.com/articles/#how-to-choose-the-right-domain-boundaries), we learned about the importance of starting with few, large business domains. Each domain encapsulates [entities](https://www.howtocodeit.com/articles/#entities-vs-records) that change atomically.
|
||||
|
||||
We start with large domains because our instincts about where domain boundaries should be are often wrong. User behavior causes applications to evolve organically. As domains get smaller, you'll find yourself correcting the boundaries – and their dependent code – more often.
|
||||
|
||||
Now imagine you work for a stealth start-up building its MVP. Karl, the founder, calls you over to talk architecture. You're concerned by Karl's recent weight loss and accelerated balding. Did he always have that facial tic?
|
||||
|
||||
Your company doesn't have customers yet, but Karl claims to know what the correct domain boundaries are, having seen them in a dream. You think this unlikely, since he doesn't appear to have slept.
|
||||
|
||||
Karl is so confident in these boundaries that he orders you to place each domain in a separate microservice. In the face of your protests, he mutters something about "extreme scale" and "the valuation", and sacrifices a goat to the dark god of network partitions\*.
|
||||
|
||||
This is what go-live looks like with microservices. All the pain of incorrect domain boundaries, now with network hops.
|
||||
|
||||
By starting with a coarse-grained hexagonal monolith, you can refine your domain boundaries in response to observed use patterns. If and when you reach the *organizational* scale where microservices are necessary, it's a relatively simple matter of extracting these battle-tested domains into their own microservices.
|
||||
|
||||
Remember – a hexagonal domain doesn't care where it gets its requests from. It could be a request from another domain running in the same process. It could be an RPC from an internal microservice, or a RESTful request from the outside world. It doesn't matter.
|
||||
|
||||
#### Big team, big monolith, big headache
|
||||
|
||||
Most teams reach for microservices when their monolith has become too large, overloaded and impenetrable to manage. They're resigned to PR conflict purgatory because everyone's code is interdependent and build times are charted by the passage of seasons.
|
||||
|
||||
If this is you, and you have the power to lead architectural change, please consider refactoring your chaotic evil monolith to a hexagonal monolith before making the leap to microservices.
|
||||
|
||||
The situation won't be improved by pulling out a group of features that look like they belong together, putting them somewhere else on the network, and calling it a microservice.
|
||||
|
||||
That initial decomposition is a guess at where the domain boundaries are. Code that once depended on the extracted service will now be making fallible network calls. You will find, inevitably, that some of these should have stayed in-process. You might find that *more* should have been cut away from the monolithic flank. Unfortunately, now that there are many theoretically – but not practically – independent microservices, it's unclear where this orphaned code should live.
|
||||
|
||||
Migration to a hexagonal monolith turns the difficulty down by taking out the networking element. Start by identifying just one business domain you'd like to extract from the monolith. Your first stab at decomposition shouldn't move this to a microservice, but to a clearly bounded domain within the existing monolith, called via ports and adapters.
|
||||
|
||||
Observe how the the rest of the tangled, heretical codebase interfaces with your hexagonal sanctuary. Refine the boundaries until they stabilize. This is much easier without the network hop. When the API to your domain is reasonably stable, it's ready to become a microservice.
|
||||
|
||||
Of course, the reason microservices seem so appealing is because they solve organizational pressures (teams treading on each other's toes) and resource pressures (big boxes to run big apps). How does hexagonal decomposition address that if all the code still lives in the same app?
|
||||
|
||||
An old monolith may take years to decompose, but it's not an all-or-nothing process. Prioritize the code that causes the biggest organizational and resource pressures, grit your teeth for a couple of months to make it hexagonal – *get the domain boundaries right* – then pull those domains into microservices. You don't have to refactor the whole application before extracting stable domain APIs.
|
||||
|
||||
By rushing towards a distributed architecture, you'll turn a bad monolith into bad microservices. *Legacy®: Networked Edition*.
|
||||
|
||||
By guinea-pigging internal domains, you introduce the network complexity only after the business complexity is solved.
|
||||
|
||||
#### Greenfield projects in established companies
|
||||
|
||||
If you work for the kind of large, established business where success is more about saying yes to the right people than writing good code, you may be tempted to stop reading here and go back to speculating when your next stock options will vest. You have my full support.
|
||||
|
||||
However, if you find yourself in a position to influence the direction of a new codebase within a well-resourced, established organization, use hexagonal architecture to cultivate a serene glade within Mirkwood.
|
||||
|
||||
Here's why:
|
||||
|
||||
- The business logic must be at least moderately complex, or the business wouldn't bother assembling a team for it.
|
||||
- Dependencies like databases, message queues, etc. will *certainly* change based on the whims and shifting preferences of higher-ranking managers.
|
||||
- This project – assuming it isn't canned when the quarterly earnings fall short – may be maintained for years, by hundreds of people who aren't you. You owe them a sane project structure with proper test coverage.
|
||||
|
||||
Cultural inertia may be against you. The whole team needs to buy in to hexagonal architecture and understand how it hangs together. If they're as excited as you are to start fresh and do better, you might just pull it off.
|
||||
|
||||
#### High-performance applications
|
||||
|
||||
We all like our apps to go fast, but "fast" is a relative term.
|
||||
|
||||
No user will perceive a speed difference between web app that lets its HTTP request types flow through the whole codebase, and a hexagonal app that parses transport-layer models into domain representations. But these transformations do have a cost, and if you're working on the kind of project where these costs matter, you already know it's too steep.
|
||||
|
||||
If you rely heavily on [zerocopy](https://docs.rs/zerocopy/latest/zerocopy/), if your application shares memory with your network card, if you ever find yourself wondering if rustc is outputting the optimal assembly... my apologies – you don't have the nanoseconds to spare for hexagonal architecture.
|
||||
|
||||
### Adopting hexagonal architecture
|
||||
|
||||
If you've decided that hexagonal architecture meets your needs, the fifth and final section of this guide will leave you with a wealth of practical Rust recipes. Each one will address a specific problem you might encounter as you adopt hexagonal architecture. I'm so excited to hear what you build.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
*Part five is coming next!*
|
||||
964
Clippings/Master Hexagonal Architecture in Rust.md
Normal file
964
Clippings/Master Hexagonal Architecture in Rust.md
Normal file
@ -0,0 +1,964 @@
|
||||
---
|
||||
title: "Master Hexagonal Architecture in Rust"
|
||||
source: "https://www.howtocodeit.com/articles/master-hexagonal-architecture-rust#the-repository-pattern-in-rust"
|
||||
author:
|
||||
- "[[How To Code It]]"
|
||||
published:
|
||||
created: 2025-08-07
|
||||
description: "Everything you need to write flexible, future-proof Rust applications using hexagonal architecture."
|
||||
tags:
|
||||
- "clippings"
|
||||
---
|
||||
Contents[Introduction](https://www.howtocodeit.com/articles/#introduction)
|
||||
|
||||
[
|
||||
|
||||
Part I:Anatomy of a bad Rust application
|
||||
|
||||
](https://www.howtocodeit.com/articles/#anatomy-of-a-bad-rust-application)
|
||||
1. [What problems does hexagonal architecture solve?](https://www.howtocodeit.com/articles/#what-problems-does-hexagonal-architecture-solve)
|
||||
2. [Hard dependencies and hexagonal architecture: how to make the right call](https://www.howtocodeit.com/articles/#hard-dependencies-and-hexagonal-architecture-how-to-make-the-right-call)
|
||||
|
||||
[
|
||||
|
||||
Part II:Separation of concerns, the Rust way
|
||||
|
||||
](https://www.howtocodeit.com/articles/#separation-of-concerns-the-rust-way)
|
||||
1. [Getting started with hexagonal architecture](https://www.howtocodeit.com/articles/#getting-started-with-hexagonal-architecture)
|
||||
2. [The repository pattern in Rust](https://www.howtocodeit.com/articles/#the-repository-pattern-in-rust)
|
||||
3. [Domain models](https://www.howtocodeit.com/articles/#domain-models)
|
||||
4. [Error types and hexagonal architecture](https://www.howtocodeit.com/articles/#error-types-and-hexagonal-architecture)
|
||||
1. [Don't panic](https://www.howtocodeit.com/articles/#dont-panic)
|
||||
6. [Everything but the kitchen async](https://www.howtocodeit.com/articles/#everything-but-the-kitchen-async)
|
||||
7. [From the Very Bad Application to the merely Bad Application](https://www.howtocodeit.com/articles/#from-the-very-bad-application-to-the-merely-bad-application)
|
||||
8. [Testing HTTP handlers with injected repositories](https://www.howtocodeit.com/articles/#testing-http-handlers-with-injected-repositories)
|
||||
|
||||
[
|
||||
|
||||
Part III:`Service`, the heart of hexagonal architecture
|
||||
|
||||
](https://www.howtocodeit.com/articles/#service-the-heart-of-hexagonal-architecture)
|
||||
1. [Introducing the `Service` trait](https://www.howtocodeit.com/articles/#introducing-the-service-trait)
|
||||
2. [Why hexagons?](https://www.howtocodeit.com/articles/#why-hexagons)
|
||||
3. [How to choose the right domain boundaries](https://www.howtocodeit.com/articles/#how-to-choose-the-right-domain-boundaries)
|
||||
1. [Start with large domains](https://www.howtocodeit.com/articles/#start-with-large-domains)
|
||||
5. [A Rust project template for hexagonal architecture](https://www.howtocodeit.com/articles/#a-rust-project-template-for-hexagonal-architecture)
|
||||
6. [Make an informed decision](https://www.howtocodeit.com/articles/#make-an-informed-decision)
|
||||
|
||||
[
|
||||
|
||||
Part IV:Trade-offs of hexagonal architecture in Rust
|
||||
|
||||
](https://www.howtocodeit.com/articles/#trade-offs-of-hexagonal-architecture-in-rust)
|
||||
1. [Put down the Kool-Aid](https://www.howtocodeit.com/articles/#put-down-the-kool-aid)
|
||||
2. [Strengths and weaknesses of hexagonal architecture](https://www.howtocodeit.com/articles/#strengths-and-weaknesses-of-hexagonal-architecture)
|
||||
3. [Is hexagonal architecture right for you?](https://www.howtocodeit.com/articles/#is-hexagonal-architecture-right-for-you)
|
||||
1. [Solo developers and personal projects](https://www.howtocodeit.com/articles/#solo-developers-and-personal-projects)
|
||||
2. [Applications with little business logic](https://www.howtocodeit.com/articles/#applications-with-little-business-logic)
|
||||
3. [Startups that want to scale hard](https://www.howtocodeit.com/articles/#startups-that-want-to-scale-hard)
|
||||
4. [Big team, big monolith, big headache](https://www.howtocodeit.com/articles/#big-team-big-monolith-big-headache)
|
||||
5. [Greenfield projects in established companies](https://www.howtocodeit.com/articles/#greenfield-projects-in-established-companies)
|
||||
6. [High-performance applications](https://www.howtocodeit.com/articles/#high-performance-applications)
|
||||
5. [Adopting hexagonal architecture](https://www.howtocodeit.com/articles/#adopting-hexagonal-architecture)[Part V:Advanced hexagonal architecture in Rust](https://www.howtocodeit.com/articles/#advanced-hexagonal-architecture-in-rust)[Exercises](https://www.howtocodeit.com/articles/#exercises)[Discussion](https://www.howtocodeit.com/articles/#discussion)
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
## Introduction
|
||||
|
||||
Hexagonal Architecture. You've heard the buzzwords. You've wondered, "why hexagons?". You think domain-driven design is involved, somehow. Your company probably says they're using it, but you suspect they're doing it wrong.
|
||||
|
||||
Let me clear things up for you.
|
||||
|
||||
By the end of this guide, you'll have everything you need to write ironclad Rust applications using hexagonal architecture.
|
||||
|
||||
I will get you writing the most maintainable Rust of your life. Your production errors will fall. Test coverage with skyrocket. Scaling will get less painful.
|
||||
|
||||
If you haven't read [*The Ultimate Guide to Rust Newtypes*](https://www.howtocodeit.com/articles/ultimate-guide-rust-newtypes) yet, I recommend doing so first – type-driven design is the cherry to hexagonal architecture's sundae, and you'll see many examples of newtypes in this tutorial.
|
||||
|
||||
Now, this is a big topic. Huge (O'Reilly, hit me up). I'm going to publish it section by section, releasing the next only once you've had a chance to digest the last and tackle the [exercises](https://www.howtocodeit.com/articles/#exercises) for each new concept. Bookmark this page if you don't want to miss anything – I'll add every new section here.
|
||||
|
||||
I'll be using a blogging engine with an [axum](https://docs.rs/axum/latest/axum/) web server as our primary example throughout this guide. Over time, we'll build it into an application of substantial complexity.
|
||||
|
||||
The type of app and the crates it uses are ultimately irrelevant, though. The principles of hexagonal architecture are not confined to web apps – any application that receives external input or makes requests to the outside world can benefit.
|
||||
|
||||
Let's get into it.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
### What problems does hexagonal architecture solve?
|
||||
|
||||
The answer to the question "why hexagons?" is boring, so we're not going to start there.
|
||||
|
||||
How To Code It is all about code! I'm going to start by showing you how *not* to write applications in Rust. By studying a Very Bad Application, you'll see the problems that hexagonal architecture solves clearly.
|
||||
|
||||
The Very Bad Application is the most common way to write production services. Your company will have code that looks just like it. [*Zero To Production In Rust*](https://www.zero2prod.com/index.html) writes its tutorial app in a similar way. In fairness, it has its hands full with teaching us Rust, and it only promised to *get* us to production, not keep us there.
|
||||
|
||||
The Very Bad Application is a scaling and maintainability time bomb. It is a misery to test and refactor. It will increase your staff turnover and lower your annual bonus.
|
||||
|
||||
Here's my take on `main.rs` for such a program:
|
||||
|
||||
```
|
||||
rustsrc/bin/server/main.rs#[tokio::main]async fn main() -> anyhow::Result<()> { let config = Config::from_env()?;
|
||||
// A minimal tracing middleware for request logging. tracing_subscriber::fmt::init(); let trace_layer = tower_http::trace::TraceLayer::new_for_http().make_span_with( |request: &axum::extract::Request<_>| { let uri = request.uri().to_string(); tracing::info_span!("http_request", method = ?request.method(), uri) },1 );
|
||||
let sqlite = SqlitePool::connect_with(2 SqliteConnectOptions::from_str(&config.database_url) .with_context(|| format!("invalid database path {}", &config.database_url))? .pragma("foreign_keys", "ON"), ) .await .with_context(|| format!("failed to open database at {}", &config.database_url))?;
|
||||
let app_state = AppState { sqlite: Arc::new(sqlite),3 }; let router = axum::Router::new()4 .route("/authors", post(create_author)) .layer(trace_layer) .with_state(app_state); let listener = net::TcpListener::bind(format!("0.0.0.0:{}", &config.server_port)) .await .with_context(|| format!("failed to listen on {}", &config.server_port))?;
|
||||
tracing::debug!("listening on {}", listener.local_addr().unwrap()); axum::serve(listener, router) .await .context("received error from running server")?;
|
||||
Ok(())}
|
||||
```
|
||||
|
||||
This code loads the application config from the environment, configures some tracing middleware, creates an Sqlite connection pool, and injects it into an axum HTTP router. We have one route: `POST /authors`, for creating blog post authors. Finally, it binds Tokio `TcpListener` to the application port and fires up the server.
|
||||
|
||||
We're concerned about *architecture*, so I've omitted details like a panic recovery layer, the finer points of tracing, graceful shutdown, and most of the routes a full app would have.
|
||||
|
||||
Even so, this is fat `main` function. If you're tempted to say that it could be improved by moving the application setup logic to a dedicated `setup` module, you're not wrong – but your priorities are. There is much greater evil here.
|
||||
|
||||
Firstly, why is `main` configuring HTTP middleware [`1`](https://www.howtocodeit.com/articles/#code-ref-1)? In fact, it looks like `main` needs an intimate understanding of the whole axum crate just to get the server running [`4`](https://www.howtocodeit.com/articles/#code-ref-4)! axum isn't even part of our application – it's a third-party dependency that has escaped containment.
|
||||
|
||||
You'd have the same problem if this code lived in a `setup` module. It's not the location of the setup, but the failure to encapsulate and abstract dependencies that makes this code hard to maintain.
|
||||
|
||||
If you ever change your HTTP server, `main` has to change too. To add middleware, you modify `main`. Major version changes in axum could force you to change `main`.
|
||||
|
||||
We have the same issue with the database at [`2`](https://www.howtocodeit.com/articles/#code-ref-2), where we shackle our `main` function to one particular, third-party implementation of an Sqlite client. Next, we make things *so* much worse by flowing this concrete representation – an imported struct entirely outside our control – through the *entire application*. See how we pass `sqlite` into axum as a field of `AppState` [`3`](https://www.howtocodeit.com/articles/#code-ref-3) to make it accessible to our HTTP handlers?
|
||||
|
||||
To change your database client – not even to change the kind of database, just the code that calls it – you'd have to rip out this hard dependency from every corner of your application.
|
||||
|
||||
This isn't a leaky abstraction, it's a broken dam.
|
||||
|
||||
Take a moment to recover, because I'm about to show you the `create_author` handler, and it's a bloodbath.
|
||||
|
||||
```
|
||||
rustsrc/lib/routes.rspub async fn create_author( State(state): State<AppState>,5 Json(author): Json<CreateAuthorRequestBody>,) -> Result<ApiSuccess<CreateAuthorResponseData>, ApiError> { if author.name.is_empty() {6 return Err(ApiError::UnprocessableEntity( "author name cannot be empty".to_string(), )); }
|
||||
let mut tx = state7 .sqlite .begin() .await .context("failed to start transaction")?;
|
||||
let author_id = save_author(&mut tx, &author.name).await.map_err(|e| { if is_unique_constraint_violation(&e) {8 ApiError::UnprocessableEntity(format!( "author with name {} already exists", &author.name )) } else { anyhow!(e).into() } })?;
|
||||
tx.commit().await.context("failed to commit transaction")?;
|
||||
Ok(ApiSuccess::new( StatusCode::CREATED, CreateAuthorResponseData { id: author_id.to_string(), }, ))}
|
||||
```
|
||||
|
||||
Stay with me! Suppress the urge to vomit. We'll get through this together and come out as better Rust devs.
|
||||
|
||||
Look, there's that hard dependency on sqlx [`5`](https://www.howtocodeit.com/articles/#code-ref-5), polluting the system on cue 🙄. And holy good god, our HTTP handler is orchestrating database transactions [`7`](https://www.howtocodeit.com/articles/#code-ref-7). An HTTP handler shouldn't even know what a database *is*, but this one knows SQL!
|
||||
|
||||
```
|
||||
rustsrc/lib/routes.rsasync fn save_author(tx: &mut Transaction<'_, Sqlite>, name: &str) -> Result<Uuid, sqlx::Error> { let id = Uuid::new_v4(); let id_as_string = id.to_string(); let query = sqlx::query!( "INSERT INTO authors (id, name) VALUES ($1, $2)", id_as_string, name ); tx.execute(query).await?; Ok(id)}
|
||||
```
|
||||
|
||||
And the horrifying consequence of this is that the handler also has to understand the specific error type of the database crate – and the database itself [`8`](https://www.howtocodeit.com/articles/#code-ref-8):
|
||||
|
||||
```
|
||||
rustsrc/lib/routes.rsconst UNIQUE_CONSTRAINT_VIOLATION_CODE: &str = "2067";
|
||||
fn is_unique_constraint_violation(err: &sqlx::Error) -> bool { if let sqlx::Error::Database(db_err) = err { if let Some(code) = db_err.code() { if code == UNIQUE_CONSTRAINT_VIOLATION_CODE { return true; } } }
|
||||
false}
|
||||
```
|
||||
|
||||
Refactoring this kind of code is miserable, you get that. But here's the kicker – unit testing this kind of code is impossible.
|
||||
|
||||
You cannot call this handler without a real, concrete instance of an sqlx SQLite connection pool.
|
||||
|
||||
And don't come at me with "it's fine, we can still integration test it", because that's not enough. Look at how complex the error handling is. We've got inline request body validation [`6`](https://www.howtocodeit.com/articles/#code-ref-6), transaction management [`7`](https://www.howtocodeit.com/articles/#code-ref-7), and sqlx errors [`8`](https://www.howtocodeit.com/articles/#code-ref-8) in one function.
|
||||
|
||||
Integration tests are slow and expensive – they aren't suited to exhaustive coverage. And how are you going to test the scenario where the transaction fails to start? Will you make the real database fall over?
|
||||
|
||||
This architecture is game over for maintainability. Nightmare fuel.
|
||||
|
||||
### Hard dependencies and hexagonal architecture: how to make the right call
|
||||
|
||||
Hard dependencies aren't irredeemably evil – you'll see several as we build our hexagonal answer to the Very Bad Application – but they are use-case-dependent.
|
||||
|
||||
Tokio is a hard dependency of most production Rust applications. This is by necessity. An async runtime is a dependency on a grand scale, practically part of the language itself. Your application can't function without it, and its purpose is so fundamental that you'd gain nothing from attempting to abstract it away.
|
||||
|
||||
In these situations, consider the few alternatives carefully, and accept that changing your mind later will mean a painful refactor. Most of all, look for evidence of widespread community adoption and support.
|
||||
|
||||
HTTP packages, database clients, message queues, etc. do not fall into this category. Teams opt to change these dependencies regularly, for reasons including:
|
||||
|
||||
- scaling pressures that require new technical solutions,
|
||||
- deprecation of key libraries,
|
||||
- security threats,
|
||||
- someone more senior said so.
|
||||
|
||||
It's critical that we abstract these packages behind our own, clean interfaces, forcing conformity with our application. In the next part of this guide, you'll learn how to do exactly that.
|
||||
|
||||
Hexagonal architecture brings order to chaos and flexibility to fragile programs by making it easy to create modular applications where connections to the outside world always adhere to the most important API of all: your business domain.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
Part II
|
||||
|
||||
## Separation of concerns, the Rust way
|
||||
|
||||
### Getting started with hexagonal architecture
|
||||
|
||||
Our transition to hexagonal architecture begins here. We'll move from a tightly coupled, untestable nightmare to a happy place where production doesn't fall over at 3am.
|
||||
|
||||
We're going to transform the Very Bad Application gradually, zooming out a little at a time until you see the whole hexagon. Then I'll answer "why hexagons?". Promise.
|
||||
|
||||
I've omitted details like module names and folder structure for simplicity. Don't worry, though. Before this guide is over, you'll have a complete application template you can reuse across all your projects.
|
||||
|
||||
### The repository pattern in Rust
|
||||
|
||||
The worst part of the Very Bad Application is undoubtedly having an HTTP handler making direct queries to an SQL database. This is a plus-sized violation of the Single Responsibility Principle.
|
||||
|
||||
Code that understands the HTTP request-response cycle shouldn't also understand SQL. Code that needs a database doesn't need to know how that database is implemented. These could not be more different concerns.
|
||||
|
||||
Hard-coding your handler to manage SQL transactions will come back to bite you if you switch to Mongo. That Mongo connection will need ripping out if you move to event streaming, to querying a CQRS service, or to making an intern do it by hand.
|
||||
|
||||
All of these are valid data stores. If you overcommit by hard-wiring any one of them into your system, you guarantee future pain when you can least afford it – when you need to scale.
|
||||
|
||||
Repository is the general term for "some store of data". Our first step is to move the `create_author` handler away from SQL and towards the abstract concept of a repository.
|
||||
|
||||
A handler that says "give me any store of data" is much better than a handler that says "give me this specific store of data, because it's the only one I know how to use".
|
||||
|
||||
Your mind has undoubtedly turned to traits as Rust's way of defining behaviour as opposed to structure. How very astute of you. Let's define an `AuthorRepository` trait:
|
||||
|
||||
```
|
||||
rust/// \`AuthorRepository\` represents a store of author data.pub trait AuthorRepository { /// Persist a new [Author]. /// /// # Errors /// /// - MUST return [CreateAuthorError::Duplicate] if an [Author] with the same [AuthorName] /// already exists. fn create_author( &self, req: &CreateAuthorRequest,9 ) -> Result<Author, CreateAuthorError>>;10}
|
||||
```
|
||||
|
||||
An `AuthorRepository` is some store of author data with (currently) one method: `create_author`.
|
||||
|
||||
`create_author` takes a reference to the data required to create an author [`9`](https://www.howtocodeit.com/articles/#code-ref-9), and returns a `Result` containing either a saved `Author`, or a specific error type describing everything that might go wrong while creating an author [`10`](https://www.howtocodeit.com/articles/#code-ref-10). Right now, that's just the existence of duplicate authors, but we'll come back to error handling.
|
||||
|
||||
`AuthorRepository` is what's known as a domain trait. You might also have heard the term "port" before – a point of entry to your business logic. A concrete implementation of a port (say, an SQLite `AuthorRepository`) is called an adapter. Starting to sound familiar?
|
||||
|
||||
For any code that requires access to a store of author data, this port is the source of truth for how every implementation behaves. Callers no longer have to think about SQL or message queues, they just invoke this API, and the underlying adapter does all the hard work.
|
||||
|
||||
### Domain models
|
||||
|
||||
`CreateAuthorRequest`, `Author` and `CreateAuthorError` are all examples of *domain models*.
|
||||
|
||||
Domain models are the canonical representations of data accepted by your business logic. Nothing else will do. Let's see some definitions:
|
||||
|
||||
```
|
||||
rust/// A uniquely identifiable author of blog posts.#[derive(Clone, Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]pub struct Author {11 id: Uuid, name: AuthorName,}
|
||||
impl Author { pub fn new(id: Uuid, name: &str) -> Self { Self { id, name: AuthorName::new(name), } }
|
||||
pub fn id(&self) -> &Uuid { &self.id }
|
||||
pub fn name(&self) -> &AuthorName { &self.name }}
|
||||
/// A validated and formatted name.#[derive(Clone, Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]pub struct AuthorName(String);
|
||||
#[derive(Clone, Debug, Error)]#[error("author name cannot be empty")]pub struct AuthorNameEmptyError;
|
||||
impl AuthorName { pub fn new(raw: &str) -> Result<Self, AuthorNameEmptyError> { let trimmed = raw.trim(); if trimmed.is_empty() { Err(AuthorNameEmptyError) } else { Ok(Self(trimmed.to_string())) } }}
|
||||
/// The fields required by the domain to create an [Author].#[derive(Clone, Debug, PartialEq, Eq, PartialOrd, Ord, Hash, From)]pub struct CreateAuthorRequest {12 name: AuthorName,}
|
||||
impl CreateAuthorRequest { // Constructor and getters ommitted}
|
||||
#[derive(Debug, Clone, PartialEq, Eq, Error)]pub enum CreateAuthorError {13 #[error("author with name {name} already exists")] Duplicate { name: AuthorName }, // to be extended as new error scenarios are introduced}
|
||||
```
|
||||
|
||||
Now, these aren't very exciting models (they'll get more exciting when we talk about identifying the correct domain boundaries and the special concern of authentication in [Part III](https://www.howtocodeit.com/articles/#service-the-heart-of-hexagonal-architecture)). But they demonstrate how the domain defines what data flowing through the system must look like.
|
||||
|
||||
If you don't construct a valid `CreateAuthorRequest` from the raw parts you've received over the wire (or from that intern), you can't call `AuthorRepository::create_author`. Sorry, jog on. 🤷
|
||||
|
||||
This pattern of newtyping should be familiar if you've read [*The Ultimate Guide to Rust Newtypes*](https://www.howtocodeit.com/articles/ultimate-guide-rust-newtypes). If you haven't, I'll wait for you here.
|
||||
|
||||
Four special properties arise from this:
|
||||
|
||||
1. Your business domain becomes the single source of truth for what it means to be an author, user, bank transaction or stock trade.
|
||||
2. The flow of dependencies in your application points in only one direction: towards your domain.
|
||||
3. Data structures within your domain are guaranteed to be in a valid state.
|
||||
4. You don't allow third-party implementation details, like SQL transactions or RPC messages to flow through unrelated code.
|
||||
|
||||
And this has immediate practical benefits:
|
||||
|
||||
- Easier navigation of the codebase for veterans and new joiners.
|
||||
- It's trivial to implement new data stores or input sources – you just implement the corresponding domain trait.
|
||||
- Refactoring is dramatically simplified thanks to the absence of hard-coded implementation details. If an implementation of a domain trait changes, nothing about the domain code or anything downstream from it needs to change.
|
||||
- Testability skyrockets, because any domain trait, like `AuthorRepository` can be mocked. We'll see this in action shortly.
|
||||
|
||||
Why do we distinguish `CreateAuthorRequest` [`12`](https://www.howtocodeit.com/articles/#code-ref-12) from `Author` [`11`](https://www.howtocodeit.com/articles/#code-ref-11)? Surely we could represent both saved and unsaved `Author` s as
|
||||
|
||||
```
|
||||
rustpub struct Author { id: Option<Uuid>, name: AuthorName,}
|
||||
```
|
||||
|
||||
Right now, with this exact application, this would be fine. It might be annoying to check whether `id` is `Some` or `None` to distinguish whether `Author` is saved or unsaved, but it would work.
|
||||
|
||||
However, we'd be mistaken in assuming that the data required to create an `Author` and the representation of an existing `Author` will never diverge. This is not at all true of real applications.
|
||||
|
||||
I've done a lot of work in onboarding and ID verification for fintechs. The data required to fully represent a customer is extensive. It can take many weeks to collect it and make an account fully operational.
|
||||
|
||||
This is pretty poor as a customer experience, and abandonment would be high if you took an all-or-nothing approach to account creation.
|
||||
|
||||
Instead, an initial outline of a customer's details is usually enough to create a basic profile. You get the customer interacting with the platform as soon as possible, and stagger the collection of the remaining data, fleshing out the model over time.
|
||||
|
||||
In this scenario, you don't want to represent some `CreateCustomerRequest` and `Customer` in the same way. `Customer` may contain dozens of optional fields and relations that aren't required to create a record in the database. It would be brittle and inefficient to pass such a needlessly large struct when creating a customer.
|
||||
|
||||
What happens when the domain representation of a customer changes, but the data required to create one remains the same? You'd be forced to change your request handling code too. Or, you'd be forced to do what you should have done from the start – decouple these models.
|
||||
|
||||
Hexagonal architecture is about building for change. Although these models may look like duplicative boilerplate to begin with, don't be fooled. Your application will change. Your API *will* diverge from your domain representation.
|
||||
|
||||
By modeling persistent entities separately from requests to create them, you encode an incredible capacity to scale.
|
||||
|
||||
Let's zoom in on `CreateAuthorError` [`13`](https://www.howtocodeit.com/articles/#code-ref-13). It reveals some important properties of domain models and traits.
|
||||
|
||||
`CreateAuthorError` doesn't define failure cases such as an input name being invalid. This is the responsibility of the `CreateAuthorRequest` constructor (which in this case delegates to the `AuthorName` constructor). Here's more on [using newtype constructors as the source of truth](https://www.howtocodeit.com/articles/ultimate-guide-rust-newtypes#constructors-as-the-source-of-truth) if you're unclear on this point.
|
||||
|
||||
`CreateAuthorError` defines failures that arise from coordinating the action of adapters. There are two categories: violations of business rules, like attempting to create a duplicate author, and unexpected errors that the domain doesn't know how to handle.
|
||||
|
||||
Much as our domain would like to pretend the real world doesn't exist, *many* things can go wrong when calling a database. We could fail to start a transaction, or fail to commit it. The database could literally catch fire in the course of a request.
|
||||
|
||||
The domain doesn't know anything about database implementations. It doesn't know about transactions. It doesn't know about the fire hazards posed by large datacenters and your pyromaniac intern. It's oblivious to retry strategies, cache layers and dead letter queues (we'll talk about these in [Part V: *Advanced Hexagonal Architecture in Rust*](https://www.howtocodeit.com/articles/#advanced-hexagonal-architecture-in-rust)).
|
||||
|
||||
But it needs some mechanism to propagate unexpected errors back up the call chain. This is typically achieved with a catch-all variant, `Unknown`, which wraps a general error type. `anyhow::Error` is particularly convenient for this, since it includes a backtrace for any error it wraps.
|
||||
|
||||
As a result (no pun intended), `CreateAuthorError` is a complete description of everything that can go wrong when creating an author.
|
||||
|
||||
This is incredible news for callers of domain traits – immensely powerful. Any code calling a port has a complete description of every error scenario it's expected to handle, and the compiler will make sure that it does.
|
||||
|
||||
But enough theorizing! Let's see this in practice.
|
||||
|
||||
### Implementing AuthorRepository
|
||||
|
||||
Here, I move the code required to interact with an SQLite database out of the Very Bad Application's `create_author` handler and into an implementation of `AuthorRepository`.
|
||||
|
||||
We start by wrapping an sqlx connection pool in our own `Sqlite` type. Module paths for sqlx types are fully qualified to avoid confusion:
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]pub struct Sqlite { pool: sqlx::SqlitePool,}
|
||||
impl Sqlite { pub async fn new(path: &str) -> anyhow::Result<Sqlite> {14 let pool = sqlx::SqlitePool::connect_with( sqlx::sqlite::SqliteConnectOptions::from_str(path) .with_context(|| format!("invalid database path {}", path))?15 .pragma("foreign_keys", "ON"), ) .await .with_context(|| format!("failed to open database at {}", path))?;
|
||||
Ok(Sqlite { pool }) }}
|
||||
```
|
||||
|
||||
Wrapping types like `sqlx::SqlitePool` has the benefit of encapsulating a third-party dependencies within code of our own design. Remember the Very Bad Application's leaky `main` function [`1`](https://www.howtocodeit.com/articles/#code-ref-1)? Wrapping external libraries and exposing only the functionality your application needs is how we plug the leaks.
|
||||
|
||||
Again, don't worry about module structure for now. Get comfortable with the type definitions, then we'll assemble the pieces.
|
||||
|
||||
This constructor does what you'd expect, with the possible exception of the result it returns. This constructor isn't part of the `AuthorRepository` trait, so we're not bound by its strict opinions on the types of allowable error.
|
||||
|
||||
[anyhow](https://docs.rs/anyhow/latest/anyhow/) is an excellent crate for working with non-specific errors. `anyhow::Result` is equivalent to `Result<T, anyhow::Error>`, and `anyhow::Error` says we don't care *which* error occurred, just that one did.
|
||||
|
||||
At the point where most applications are instantiating databases, the only reasonable thing to do with an error is log it to `stdout` or some log aggregation service. `Sqlite::new` simply wraps any sqlx error it encounters with some extra context [`15`](https://www.howtocodeit.com/articles/#code-ref-15).
|
||||
|
||||
Now, the exciting stuff – the implementation of `AuthorRepository`:
|
||||
|
||||
```
|
||||
rustimpl AuthorRepository for Sqlite { async fn create_author(&self, req: &CreateAuthorRequest) -> Result<Author, CreateAuthorError> { let mut tx = self16 .pool .begin() .await .unwrap_or_else(|e| panic!("failed to start SQLite transaction: {}", e));
|
||||
let author_id = self.save_author(&mut tx, req.name())17 .await .map_err(|e| { if is_unique_constraint_violation(&e) {18 CreateAuthorError::Duplicate { name: req.name().clone(), } } else { anyhow!(e) .context(format!("failed to save author with name {:?}", req.name())) .into()19 } })?;
|
||||
tx.commit() .await .unwrap_or_else(|e| panic!("failed to commit SQLite transaction: {}", e));
|
||||
Ok(Author::new(author_id, req.name().clone())) }}
|
||||
```
|
||||
|
||||
Look! Transaction management is now encapsulated within our `Sqlite` implementation of `AuthorRepository`. The HTTP handler no longer has to know about it.
|
||||
|
||||
`create_author` invokes the `save_author` method on `Sqlite`, which isn't specified by the `AuthorRepository` trait, but gives `Sqlite` the freedom to set up and pass around transactions as it requires.
|
||||
|
||||
This is the beauty of abstracting implementation details behind traits. The trait defines what needs to happen, and the implementation decides how. None of the *how* is visible to code calling a trait method.
|
||||
|
||||
`Sqlite` 's implementation of `AuthorRepository` knows all about SQLite error codes, and transforms any error corresponding to a duplicate author into the domain's preferred representation [`18`](https://www.howtocodeit.com/articles/#code-ref-18).
|
||||
|
||||
Of course, `Sqlite`, not being part of the domain's Garden of Eden, may encounter an error that the domain can't do much with [`19`](https://www.howtocodeit.com/articles/#code-ref-19).
|
||||
|
||||
This is a `500 Internal Server Error` in the making, but repositories shouldn't know about HTTP status codes. We need to pass it back up the chain in the form of `CreateAuthorError::Unknown`, both to inform the end user that something fell over, and to capture for debugging.
|
||||
|
||||
This is a situation that the program – or at least the request handler – can't recover from. Couldn't we `panic`? The domain can't do anything useful here, so why not skip the middleman and let the panic recovery middleware handle it?
|
||||
|
||||
#### Don't panic
|
||||
|
||||
Until very recently, I would have said yes – if the domain can't do any useful work with an error, panicking will save you from duplicating error handling logic between your request handler and your panic-catching middleware.
|
||||
|
||||
However, thanks to [a comment from matta](https://www.howtocodeit.com/articles/master-hexagonal-architecture-rust#discussion) and a horrible realization I had in the shower, I've reversed my position.
|
||||
|
||||
Whether or not you consider the database falling over a recoverable error, there are two incontrovertible reasons not to panic:
|
||||
|
||||
1. Panicking poisons held mutexes. If your application state is protected by an `Arc<Mutex<T>>`, panicking while you hold the guard will mean no other thread will ever be able to acquire it again. Your program is dead, and no amount of panic recovery middleware will bring it back.
|
||||
2. Other Rust devs won't expect you to panic. Most likely, you won't be the person woken at 3am to debug your code. Strive to make it as unsurprising as possible. Follow established error handling conventions diligently. Return errors, don't panic.
|
||||
|
||||
What about retry handling? Good question. We'll cover that in [Part V: *Advanced Hexagonal Architecture in Rust*](https://www.howtocodeit.com/articles/#advanced-hexagonal-architecture-in-rust).
|
||||
|
||||
### Everything but the kitchen async
|
||||
|
||||
Have you spotted it? The mismatch between our repository implementation and the trait definition.
|
||||
|
||||
Ok, you caught me. I simplified the definition of `AuthorRepository`. There's actually more to it, because of course we want database calls to be async.
|
||||
|
||||
Writing to a file or calling a database server is precisely the kind of slow, blocking IO that we don't want to stall on.
|
||||
|
||||
We need to make `AuthorRepository` an async trait. Unfortunately, it's not quite as simple as writing
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository { async fn create_author( &self, req: &CreateAuthorRequest, ) -> Result<Author, CreateAuthorError>>;}
|
||||
```
|
||||
|
||||
Rust understands this, and it will compile, but probably won't do what you expect.
|
||||
|
||||
Although writing `async fn` will cause your method's return value to be sugared into `Future<Output = Result<Author, CreateAuthorError>>`, it *won't* get an automatic `Send` bound.
|
||||
|
||||
As a result, your future can't be sent between threads. For web applications, this is useless.
|
||||
|
||||
Let's spell things out for the compiler!
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository { fn create_author( &self, req: &CreateAuthorRequest, ) -> impl Future<Output = Result<Author, CreateAuthorError>> + Send;20}
|
||||
```
|
||||
|
||||
Since our `Author` and `CreateAuthorError` are both `Send`, a `Future` that wraps them can be too [`20`](https://www.howtocodeit.com/articles/#code-ref-20).
|
||||
|
||||
But what good is a repository if its methods return thread-safe `Future` s, but the repo itself is bound to a single thread? Let's ensure `AuthorRepository` is `Send` too.
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Send { // ...}
|
||||
```
|
||||
|
||||
Ugh, we're not done. Remember about 4,000 words ago when we wrapped our application state in an `Arc` to inject into an HTTP handler? Well, trust me, we did.
|
||||
|
||||
`Arc` requires its contents to be both `Send` and `Sync` to be either `Send` *or* `Sync` itself! [Here's a good discussion](https://stackoverflow.com/questions/41909811/why-does-arct-require-t-to-be-both-send-and-sync-in-order-to-be-send) on the topic if you'd like to know more.
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Send + Sync { // ...}
|
||||
```
|
||||
|
||||
Your instinct might now be to implement `AuthorRepository` for `&Sqlite` instead of `Sqlite`, since `&T` is immutable and therefore `Send + Sync`. However, sqlx's connection pools are themselves `Send + Sync`, meaning `Sqlite` is too.
|
||||
|
||||
Are we done yet?
|
||||
|
||||
🙃
|
||||
|
||||
Naturally, if we're shuffling a repo between threads, Rust wants to be sure it won't be dropped unexpectedly. Let's reassure the compiler that every `AuthorRepository` will live for the whole program:
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Send + Sync + 'static { // ...}
|
||||
```
|
||||
|
||||
Finally, our web server, axum, requires injected data to be `Clone`, giving our final trait definition:
|
||||
|
||||
```
|
||||
rustpub trait AuthorRepository: Clone + Send + Sync + 'static { /// Asynchronously persist a new [Author]. /// /// # Errors /// /// - MUST return [CreateAuthorError::Duplicate] if an [Author] with the same [AuthorName] /// already exists. fn create_author( &self, req: &CreateAuthorRequest, ) -> impl Future<Output = Result<Author, CreateAuthorError>> + Send;}
|
||||
```
|
||||
|
||||
### From the Very Bad Application to the merely Bad Application
|
||||
|
||||
It's time to start putting these pieces together. Let's reassemble our `create_author` HTTP handler to take advantage of the `AuthorRepository` abstraction.
|
||||
|
||||
First, the definition of `AppState`, which is the struct that contains the resources that should be available to every HTTP handler. This pattern should be familiar to users of both [axum](https://docs.rs/axum/latest/axum/) and [Actix Web](https://actix.rs/).
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]/// The application state available to all request handlers.struct AppState<AR: AuthorRepository> { author_repo: Arc<AR>,21}
|
||||
```
|
||||
|
||||
`AppState` is now generic over `AuthorRepository`. That is, `AppState` provides HTTP handlers with access to "some store of author data", giving them the ability to create authors without knowledge of the implementation.
|
||||
|
||||
We wrap whatever instance of `AuthorRepository` we receive in an `Arc`, because axum is going to share it between as many async tasks as there are requests to our application.
|
||||
|
||||
This isn't our final destination – eventually our HTTP handler won't even know it has to save something (ah, sweet oblivion).
|
||||
|
||||
We're not quite there yet, but this is a vast improvement. Check out the handler!
|
||||
|
||||
```
|
||||
rustpub async fn create_author<AR: AuthorRepository>( State(state): State<AppState<AR>>,22 Json(body): Json<CreateAuthorHttpRequestBody>,) -> Result<ApiSuccess<CreateAuthorResponseData>, ApiError> { let domain_req = body.try_into_domain()?;23 state .author_repo .create_author(&domain_req) .await .map_err(ApiError::from)24 .map(|ref author| ApiSuccess::new(StatusCode::CREATED, author.into()))25}
|
||||
```
|
||||
|
||||
Oh my.
|
||||
|
||||
Isn't it beautiful?
|
||||
|
||||
Doesn't your nervous system feel calmer to behold it?
|
||||
|
||||
Go on, take some deep breaths. Enjoy the moment. [Here's the crime scene we started from](https://www.howtocodeit.com/articles/master-hexagonal-architecture-rust#code-ref-5) if you need a reminder.
|
||||
|
||||
Ok, the walkthrough. `create_author` has access to an `AuthorRepository` [`22`](https://www.howtocodeit.com/articles/#code-ref-22), which it makes good use of. But first, it converts the raw `CreateAuthorHttpRequestBody` it received from the client into the holy domain representation [`23`](https://www.howtocodeit.com/articles/#code-ref-23). Here's how:
|
||||
|
||||
```
|
||||
rust/// The body of an [Author] creation request.#[derive(Debug, Clone, PartialEq, Eq, Deserialize)]pub struct CreateAuthorHttpRequestBody { name: String,}
|
||||
impl CreateAuthorHttpRequestBody { /// Converts the HTTP request body into a domain request. fn try_into_domain(self) -> Result<CreateAuthorRequest, AuthorNameEmptyError> { let author_name = AuthorName::new(&self.name)?; Ok(CreateAuthorRequest::new(author_name)) }}
|
||||
```
|
||||
|
||||
Nothing fancy! Boilerplatey, you might think. This is by design. We have preemptively decoupled the HTTP API our application exposes to the world from the internal domain representation.
|
||||
|
||||
As you scale, you will thank this so-called boilerplate. You will name your firstborn child for it.
|
||||
|
||||
These two things can now change independently. Changing the domain doesn't necessarily force a new web API version. Changing the HTTP request structure does not require any change to the domain. Only the mapping in `CreateAuthorHttpRequestBody::into_domain` and its corresponding unit tests get updated.
|
||||
|
||||
This is a very special property. Changes to transport concerns or business logic no longer spread through your program like wildfire. Abstraction has been achieved.
|
||||
|
||||
Thanks to the pains we took to define all the errors an `AuthorRepository` is allowed to return, constructing an HTTP response is dreamy. In the error case, we map seamlessly to a serializable `ApiError` using `ApiError::from` [`24`](https://www.howtocodeit.com/articles/#code-ref-24):
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone, PartialEq, Eq)]pub enum ApiError { InternalServerError(String),26 UnprocessableEntity(String),27}
|
||||
impl From<CreateAuthorError> for ApiError { fn from(e: CreateAuthorError) -> Self { match e { CreateAuthorError::Duplicate { name } => { Self::UnprocessableEntity(format!("author with name {} already exists", name))28 } CreateAuthorError::Unknown(cause) => { tracing::error!("{:?}\n{}", cause, cause.backtrace()); Self::InternalServerError("Internal server error".to_string()) } } }}
|
||||
impl From<AuthorNameEmptyError> for ApiError { fn from(_: AuthorNameEmptyError) -> Self { Self::UnprocessableEntity("author name cannot be empty".to_string()) }}
|
||||
```
|
||||
|
||||
If the author was found to be a duplicate, it means the client's request was correctly structured, but that the contents were unprocessable. Hence, we're aiming to respond `422 Unprocessable Entity` [`27`](https://www.howtocodeit.com/articles/#code-ref-27).
|
||||
|
||||
Important detail alert! Do you see how we're manually building an error message at [`28`](https://www.howtocodeit.com/articles/#code-ref-28), even though `CreateAuthorError::to_string` could have produced this error for us?
|
||||
|
||||
This is another instance of aggressive decoupling of our transport concern (JSON over HTTP) from the domain. Returning full-fat, unpasteurised domain errors to users is an easy way to leak private details of your application. It also results in unexpected changes to HTTP responses when domain implementation details change!
|
||||
|
||||
If we get an error the domain didn't expect – `CreateAuthorError::Unknown` here – that maps straight to `InternalServerError` [`26`](https://www.howtocodeit.com/articles/#code-ref-26).
|
||||
|
||||
The finer points of how you log the underlying cause will vary according to your needs. Crucially, however, the error itself is not exposed to the end user.
|
||||
|
||||
Finally, our success case [`25`](https://www.howtocodeit.com/articles/#code-ref-25). We take a reference to the returned `Author` and transform it into its public API counterpart. It gets sent on its way with status `201 Created`.
|
||||
|
||||
```
|
||||
rust/// The response body data field for successful [Author] creation.#[derive(Debug, Clone, PartialEq, Eq, Serialize)]pub struct CreateAuthorResponseData { id: String,}
|
||||
impl From<&Author> for CreateAuthorResponseData { fn from(author: &Author) -> Self { Self { id: author.id().to_string(), } }}
|
||||
```
|
||||
|
||||
Chef's kiss. 🧑🍳
|
||||
|
||||
### Testing HTTP handlers with injected repositories
|
||||
|
||||
Oh, it gets better.
|
||||
|
||||
Previously, our handler code was impossible to unit test, because we needed a real database instance to call them. Trying to exercise every failure mode of a database call with a real database is pure pain.
|
||||
|
||||
Those days are over. By injecting any type that implements `AuthorRepository`, we open our HTTP handlers to unit testing with mock repositories.
|
||||
|
||||
```
|
||||
rust#[cfg(test)]mod tests { // Imports omitted.
|
||||
#[derive(Clone)] struct MockAuthorRepository { create_author_result: Arc<Mutex<Result<Author, CreateAuthorError>>>,29 }
|
||||
impl AuthorRepository for MockAuthorRepository { async fn create_author( &self, _: &CreateAuthorRequest, ) -> Result<Author, CreateAuthorError> { let mut guard = self.create_author_result.lock().await; let mut result = Err(CreateAuthorError::Unknown(anyhow!("substitute error"))); mem::swap(guard.deref_mut(), &mut result); result30 } }}
|
||||
```
|
||||
|
||||
`MockAuthorRepository` is defined to hold the `Result` it should return in response `AuthorRepository::create_author` calls [`29`](https://www.howtocodeit.com/articles/#code-ref-29) [`30`](https://www.howtocodeit.com/articles/#code-ref-30).
|
||||
|
||||
The rather nasty type signature at [`29`](https://www.howtocodeit.com/articles/#code-ref-29) is due to the fact that `AuthorRepository` has a `Clone` bound, which means `MockAuthorRespository` must be `Clone`.
|
||||
|
||||
Unfortunately for us, `CreateAuthorError` isn't `Clone`, because its `Unknown` variant contains `anyhow::Error`. `anyhow::Error` isn't `Clone` since it's designed to wrap unknown errors, which may not be `Clone` themselves. `std::io::Error` is one common non- `Clone` error.
|
||||
|
||||
Rather than passing `MockAuthorRepository` a convenient `Result<Author, CreateAuthorError>`, we need to give it something cloneable – `Arc`. But, as discussed, `Arc` 's contents need to be `Send + Sync` for `Arc` to be `Send + Sync`, so we're forced to wrap the `Result` in a `Mutex`. (I'm using a `tokio::sync::Mutex` here, hence the `await`, but `std::sync::Mutex` also works with minor changes to the supporting code).
|
||||
|
||||
The mock implementation of `create_author` then deals with swapping a dummy value with the real result in order to return it to the test caller.
|
||||
|
||||
Here's the test for the case where the repository call succeeds. I leave the error case to your powerful imagination, but if you crave more Rust testing pearls, I'll have a comprehensive guide to unit testing for you soon!
|
||||
|
||||
```
|
||||
rust#[tokio::test(flavor = "multi_thread")]async fn test_create_author_success() { let author_name = AuthorName::new("Angus").unwrap(); let author_id = Uuid::new_v4(); let repo = MockAuthorRepository {31 create_author_result: Arc::new(Mutex::new(Ok(Author::new( author_id, author_name.clone(), )))), }; let state = axum::extract::State(AppState { author_repo: Arc::new(repo), }); let body = axum::extract::Json(CreateAuthorHttpRequestBody { name: author_name.to_string(), }); let expected = ApiSuccess::new(32 StatusCode::CREATED, CreateAuthorResponseData { id: author_id.to_string(), }, );
|
||||
let actual = create_author(state, body).await;33 assert!( actual.is_ok(), "expected create_author to succeed, but got {:?}", actual );
|
||||
let actual = actual.unwrap(); assert_eq!( actual, expected, "expected ApiSuccess {:?}, but got {:?}", expected, actual )}
|
||||
```
|
||||
|
||||
At [`31`](https://www.howtocodeit.com/articles/#code-ref-31), we construct a `MockAuthorRepository` with an arbitrary success `Result`. We expect that a `Result::Ok(Author)` from the repo should produce a `Result::Ok(ApiSuccess<CreateAuthorResponseData>)` from the handler [`32`](https://www.howtocodeit.com/articles/#code-ref-32).
|
||||
|
||||
This situation is simple to set up – we just call the `create_author` handler with a `State` object constructed from the `MockAuthorRepository` in place of a real one [`33`](https://www.howtocodeit.com/articles/#code-ref-33). The assertions are self-explanatory.
|
||||
|
||||
I know, I know – you're itching to see what `main` looks like with these improvements, but we're about to take a much bigger and more important leap in our understanding of hexagonal architecture.
|
||||
|
||||
In Part III, coming next, I'll introduce you to the beating heart of an application domain: the `Service`.
|
||||
|
||||
We'll ratchet up the complexity of our example application to understand how to set domain boundaries. We'll confront the tricky problem of *master records* through the lens of authentication, and explore the interface between hexagonal applications and distributed systems.
|
||||
|
||||
And yes, we'll finally answer, "why hexagons?".
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
Part III
|
||||
|
||||
## Service, the heart of hexagonal architecture
|
||||
|
||||
### Introducing the Service trait
|
||||
|
||||
The `Repository` trait does a great job at getting datastore implementation details out of code that handles incoming requests.
|
||||
|
||||
If our application really was as simple as the one I've described so far, this would be good enough.
|
||||
|
||||
But most real applications aren't this simple, and their domain logic involves more than writing to a database and responding `201`.
|
||||
|
||||
For example, each time a new author is successfully created, we may want to dispatch an event for other parts of our system to consume asynchronously.
|
||||
|
||||
Perhaps we want to track metrics related to author creation in a time series database like Prometheus? Or send a welcome email?
|
||||
|
||||
This sequence of conditional steps is domain logic. We've already seen that domain logic doesn't belong in adapters. Otherwise, when you swap out the adapter, you have to rewrite domain code that has nothing to do with the adapter implementation.
|
||||
|
||||
So, domain logic can't go in our HTTP handler, and it can't go in our `AuthorRepository`. Where does it live?
|
||||
|
||||
A `Service`.
|
||||
|
||||
A `Service` refers to both a trait that declares the methods of your business API, and an implementation that's provided by the domain to your inbound adapters.
|
||||
|
||||
It encapsulates calls to databases, sending of notifications and collection of metrics from your handlers behind a clean, mockable interface.
|
||||
|
||||
Currently, our axum application state looks like this:
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]/// The application state available to all request handlers.struct AppState<AR: AuthorRepository> { author_repo: Arc<AR>,}
|
||||
```
|
||||
|
||||
Let's spice up our application with some more domain traits:
|
||||
|
||||
```
|
||||
rust
|
||||
```
|
||||
|
||||
Together with `AuthorRepository`, these ports illustrate the kinds of dependencies you might expect of a real production app.
|
||||
|
||||
`AuthorMetrics` [`34`](https://www.howtocodeit.com/articles/#code-ref-34) describes an aggregator of author-related metrics, such as a time-series database. `AuthorNotifier` [`35`](https://www.howtocodeit.com/articles/#code-ref-35) triggers notifications to authors.
|
||||
|
||||
Rather than stuffing these domain dependencies into `AppState` directly, we're aiming for this:
|
||||
|
||||
```
|
||||
rust#[derive(Debug, Clone)]/// The application state available to all request handlers.struct AppState<AS: AuthorService> { author_service: Arc<AS>,}
|
||||
```
|
||||
|
||||
How do we get there? Let's start with the `Service` trait definition:
|
||||
|
||||
```
|
||||
rustpub trait AuthorService: Clone + Send + Sync + 'static { /// Asynchronously create a new [Author]. /// /// # Errors /// /// - [CreateAuthorError::Duplicate] if an [Author] with the same [AuthorName] already exists. fn create_author( &self, req: &CreateAuthorRequest, ) -> impl Future<Output = Result<Author, CreateAuthorError>> + Send;}
|
||||
```
|
||||
|
||||
Much like `AuthorRepository`, the `Service` trait has an async method, `create_author`, that takes a `CreateAuthorRequest` by reference and returns a `Future` that outputs either an `Author`, if creation was successful, or a `CreateAuthorError` if not.
|
||||
|
||||
Although the signatures of `AuthorService` and `AuthorRepository` look similar, this is a byproduct of a simple domain. They aren't required to match, and by separating our concerns with traits in this way, we allow them to diverge in future.
|
||||
|
||||
Now, the implementation of `AuthorService`:
|
||||
|
||||
```
|
||||
rust/// Canonical implementation of the [AuthorService] port, through which the author domain API is/// consumed.#[derive(Debug, Clone)]pub struct Service<R, M, N>36where R: AuthorRepository, M: AuthorMetrics, N: AuthorNotifier,{ repo: R, metrics: M, notifier: N,}
|
||||
// Constructor implementation omitted
|
||||
impl<R, M, N> AuthorService for Service<R, M, N>where R: AuthorRepository, M: AuthorMetrics, N: AuthorNotifier,{ /// Create the [Author] specified in \`req\` and trigger notifications. /// /// # Errors /// /// - Propagates any [CreateAuthorError] returned by the [AuthorRepository]. async fn create_author(&self, req: &CreateAuthorRequest) -> Result<Author, CreateAuthorError> { let result = self.repo.create_author(req).await;37 if result.is_err() { self.metrics.record_creation_failure().await; } else { self.metrics.record_creation_success().await; self.notifier.author_created(result.as_ref().unwrap()).await; }
|
||||
result }}
|
||||
```
|
||||
|
||||
The `Service` struct encapsulates the dependencies required to execute our business logic [`36`](https://www.howtocodeit.com/articles/#code-ref-36).
|
||||
|
||||
The implementation of `AuthorService::create_author` [`37`](https://www.howtocodeit.com/articles/#code-ref-37) illustrates why we don't want to embed these calls directly in handler code, which has enough work to do just managing the request-response cycle.
|
||||
|
||||
First, we call the `AuthorRepository` to persist the new author, then we branch. On a failed repository call, we call `AuthorMetrics` to track the failure. On success, we submit success metrics, then trigger notifications. In both cases, we propagate the repository `Result` to the caller.
|
||||
|
||||
I defined the `AuthorMetrics` and `AuthorNotifier` methods as infallible, since metric aggregation and notification dispatch typically takes place concurrently, with separate error handling paths.
|
||||
|
||||
Not always, though. Imagine if the metrics and notifier calls also returned errors. Suddenly, our test scenarios include:
|
||||
|
||||
- Calls to all three dependencies succeed.
|
||||
- The repo call fails, and the metrics call fails too.
|
||||
- The repo call fails, and the metrics call succeeds.
|
||||
- The repo call succeeds, but the metrics fall over.
|
||||
- The repo and metrics calls succeed, but the notifier returns an error.
|
||||
|
||||
Now picture every permutation of these cases with all of the `Result` s produced when receiving, parsing and responding to HTTP requests 🤯.
|
||||
|
||||
This is what happens if you stick domain logic in your handlers. Without a `Service` abstraction, you have to *integration* test this hell.
|
||||
|
||||
Nope. No. Not today, thank you.
|
||||
|
||||
To test handlers that call a `Service`, you just mock the service, returning whatever success or error variant you need to check the handler's output.
|
||||
|
||||
To test a `Service`, you mock each of its dependencies, returning the successes and errors required to exercise all of the paths described above.
|
||||
|
||||
Finally, you integration test the whole system, focusing on your happy paths and the most important error scenarios.
|
||||
|
||||
Paradise 🌅.
|
||||
|
||||
Now you know how to wrap your domain's dependencies in a `Service`, and you're happy that it's the service that gets injected into our handlers in `AppState`, let's check back in on `main`.
|
||||
|
||||
### main is for bootstrapping
|
||||
|
||||
The only responsibilities of your `main` function are to bring your application online and clean up once it's done.
|
||||
|
||||
Some developers delegate bootstrapping to a `setup` function that does the hard work and passes the result back to `main`, which just decides how to exit. This works too, and the differences don't matter for this discussion.
|
||||
|
||||
`main` must construct the `Service` s required by the application, inject them into our handlers, and set the whole program in motion:
|
||||
|
||||
```
|
||||
rust
|
||||
```
|
||||
|
||||
To do this, `main` needs to know which adapters to slot into the domain's ports [`38`](https://www.howtocodeit.com/articles/#code-ref-38). This example uses an SQLite `AuthorRepository`, Prometheus `AuthorMetrics` and an email-based `AuthorNotifier`.
|
||||
|
||||
It combines these implementations of the domain traits into an `AuthorService` [`39`](https://www.howtocodeit.com/articles/#code-ref-39) using the author domain's `Service` constructor.
|
||||
|
||||
Finishing up, it injects the `AuthorService` into an HTTP server and runs it [`40`](https://www.howtocodeit.com/articles/#code-ref-40).
|
||||
|
||||
Even though `main` knows which adapters we want to use, we still aim to not leak implementation details of third-party crates. Here are the `use` statements for this `main.rs` file:
|
||||
|
||||
```
|
||||
rustuse hexarch::config::Config;use hexarch::domain::author::service::Service;use hexarch::inbound::http::{HttpServer, HttpServerConfig};use hexarch::outbound::email_client::EmailClient;use hexarch::outbound::prometheus::Prometheus;use hexarch::outbound::sqlite::Sqlite;
|
||||
```
|
||||
|
||||
This is all proprietary to our application. Even though we're using an axum HTTP server, `main` doesn't know about axum.
|
||||
|
||||
Instead, we've created our own `HttpServer` wrapper around axum that exposes only the functionality the rest of the application needs.
|
||||
|
||||
Configuration of routes, ports, timeouts, etc. lives in a predictable place isolated from unrelated code. If axum were to make changes to its API, we'd need to update our `HttpServer` internals, but they'd be invisible to main.
|
||||
|
||||
There's another motivating factor behind this: `main` is pretty resistant to testing. It composes unmockable dependencies and handles errors by logging to stdout and exiting. The less code we put here, the smaller this testing dead zone.
|
||||
|
||||
Setup and configuration for integration tests is often subtly different from `main`, too. Imagine having to configure all the routes and middleware for an axum server separately for `main` and tests. What a chore!
|
||||
|
||||
By defining our own `HttpServer` type, both `main` and tests can easily spin up our app's server with the config they require. No duplication.
|
||||
|
||||
### Why hexagons?
|
||||
|
||||
Ok, it's time. It's actually happening.
|
||||
|
||||
I've shown you the key, practical components of hexagonal architecture: services, ports, adapters, and the encapsulation of third-party dependencies.
|
||||
|
||||
Now some theory – why hexagons?
|
||||
|
||||
Well, I hate to break it to you, but hexagons aren't special. There's no six-sided significance to hexagonal architecture. The truth is, any polygon will do.
|
||||
|
||||
Hexagonal architecture was [originally proposed by Alistair Cockburn](https://alistair.cockburn.us/hexagonal-architecture/), who chose hexagons to represent the way adapters surround the business domain at the core of the application. The symmetry of hexagons also reflects the duality of inbound and outbound adapters.
|
||||
|
||||
I've been holding off on a classic hexagonal architecture diagram until I showed you how the ports and adapters compose. Here you go:
|
||||
|
||||

|
||||
|
||||
A schematic representation of hexagonal architecture
|
||||
|
||||
The outside world is a scary, ever-changing place. Anything can go wrong at any time.
|
||||
|
||||
Your domain logic, on the other hand, is a calm and tranquil glade. It changes if, and only if, the requirements of your business change.
|
||||
|
||||
The adapters are the bouncers enforcing the domain's dress code on anything from the outside that wants to get in.
|
||||
|
||||
### How to choose the right domain boundaries
|
||||
|
||||
What belongs in a domain? What models and ports should it include? How many domains should a single application have?
|
||||
|
||||
These are the questions many people struggle with when adopting hexagonal architecture, or domain-driven design more generally.
|
||||
|
||||
I've got good news and bad news 💁.
|
||||
|
||||
The bad news is that I can't answer these questions for you, because they depend heavily on variables like your scale, your overall system architecture and your requirements around synchronicity.
|
||||
|
||||
The good news is, I have two powerful rules of thumb to help you make the right decision, and we'll go through some examples together.
|
||||
|
||||
Firstly, a domain represents some tangible arm of your business.
|
||||
|
||||
I've been discussing an "author domain", because a using single-entity domain makes it easier to teach the concepts of hexagonal architecture.
|
||||
|
||||
For a small blogging app, however, it's likely that a single "blog domain" would be the correct boundary to draw, since there is only one business concern – running a blog.
|
||||
|
||||
For a site like Medium, there would be multiple domains: blogging, user identity, billing, customer support, and so on. These are related but distinct business functions, that communicate using each other's `Service` APIs.
|
||||
|
||||
If this is starting to sound like microservices to you, you're not imagining things. We'll talk about the relationship between hexagonal architecture and microservices in Part IV.
|
||||
|
||||
Secondly, a domain should include all entities that must change together as part of a single, atomic operation.
|
||||
|
||||
Consider our blogging app. The author domain manages the lifecycle of an `Author`. But what about blog posts?
|
||||
|
||||
If an `Author` is deleted, do we require that all of their posts are deleted atomically, or is it acceptable for their posts to be accessible for a short time after the deletion of the author?
|
||||
|
||||
In the first case, authors and posts *must* be part of the same domain, since the deletion of an author must be atomic with the deletion of their blog posts.
|
||||
|
||||
In the second case, authors and posts could *theoretically* be represented as separate domains, which communicate to coordinate deletion events.
|
||||
|
||||
This communication could be synchronous (the author domain calls and awaits `PostService::delete_by_author_id` ) or asynchronous (the author domain pushes some `AuthorDeletionEvent` onto a message queue, for the post domain to process later).
|
||||
|
||||
Neither of these cases are atomic. Business logic, being unaware of repository implementation details, has no concept of transactions in the SQL sense.
|
||||
|
||||
If you find that you're leaking transactions into your business logic to perform cross-domain operations atomically, your domain boundaries are wrong. Cross-domain operations are never atomic. These entities should be part of the same domain.
|
||||
|
||||
#### Start with large domains
|
||||
|
||||
According to the first rule of thumb, we wouldn't actually want to separate authors and posts into different domains. They're part of the same business function, and cross-domain communication complicates your application. It has to be worth the cost.
|
||||
|
||||
We're happy to pay this cost when different parts of our business rely on each other, but need to change often and independently. We don't want these domains to be tightly coupled.
|
||||
|
||||
Identifying these related but independent components is an ongoing, iterative process based on the friction you experience as your application grows.
|
||||
|
||||
This is why starting with a single, large domain is preferable to designing many small ones upfront.
|
||||
|
||||
If you jump the gun and build a fragmented system before you have first-hand experience of the points of friction in both the system and the business, you pay a huge penalty.
|
||||
|
||||
You must write and maintain the glue code for inter-domain communication before you know if it's needed. You sacrifice atomicity which you might later find you need. You will have to undo this work and merge domains when your first guess at domain boundaries is inevitably wrong.
|
||||
|
||||
A fat domain makes no assumptions about how different business functions will evolve over time. It can be decomposed as the need arises, and maintains all the benefits of easy atomicity until that time comes.
|
||||
|
||||
#### Authentication and authorization with hexagonal architecture
|
||||
|
||||
I was deliberate in choosing `Author` s rather than `User` s for our example application. If you're used to working on smaller, monolithic apps, it's not obvious where entities like `User` s belong in hexagonal architecture.
|
||||
|
||||
If you're comfortable in a microservices context, you'll have an easier time.
|
||||
|
||||
The primary entity for authentication and authorization will "own" many other entities. A `User` for a social network will own one or more `Profile` s, `Settings`, `Subscription` s, `AccountStatus` es, and so on. All of these, and all the data that they own in turn, are traceable back to the `User`.
|
||||
|
||||
If we follow our rule of thumb – that entities that change together atomically belong in the same domain – the presence of master records causes *everything* to belong in the same domain. If you delete a `User`, and require synchronous deletion of related entities, everything must be deleted in the same, atomic operation.
|
||||
|
||||
Isn't this the same as having no domain boundaries at all?
|
||||
|
||||
For a small to medium application, where you roll your own auth and aren't expecting massive growth, this is fine. Overly granular domains will cause you more problems than they solve.
|
||||
|
||||
However, for larger applications and apps that use third-party auth providers like Auth0, a single domain is unworkable.
|
||||
|
||||
The `User` entity and associated auth code should live in its own domain, with entities in other domains retaining a unique reference to the owner. Then, depending on your level of scale, deletions can happen in two ways:
|
||||
|
||||
- Synchronously, with the auth domain calling each of the other domains' `Service::delete_by_user_id` methods.
|
||||
- Asynchronously, where the auth domain publishes a deletion event for other domains to process on their own time.
|
||||
|
||||
Neither of these scenarios is atomic.
|
||||
|
||||
Regardless of what architecture you use, atomic deletion of a `User` and all their dependent records get taken off the table once you reach a certain scale. Hexagonal architecture just makes this explicit.
|
||||
|
||||
To use an extreme example, deletion of a Facebook account, including everything it has ever posted, [takes up to 90 days](https://www.facebook.com/help/224562897555674) (including a 30-day grace period). Even then, copies may remain in backups.
|
||||
|
||||
In addition to the vast volume of data to be processed, there will be a huge amount of internal and regulatory process to follow in the course of this deletion. This can't be modeled as an atomic operation.
|
||||
|
||||
### A Rust project template for hexagonal architecture
|
||||
|
||||
Until now, I've avoided discussing module paths and file structures because I didn't want to distract from the core concepts of domains, ports and adapters.
|
||||
|
||||
Now you have the full picture, I'll let you explore [this example repository](https://github.com/howtocodeit/hexarch) at your leisure and take inspiration from its folder structure.
|
||||
|
||||
Branch `3-simple-service` contains the code we've discussed in part three of this guide, and provides a basic but representative example of a hexagonal app.
|
||||
|
||||
Dividing `src/lib` into `domain` (for business logic) `inbound` and `outbound` (for adapters) has worked well at scale for several teams I've been part of. It's not sacred though. How you name these modules and the level of granularity you choose should suit your own needs.
|
||||
|
||||
All I ask is that, whatever convention you adopt, you document it for both new and existing team members to refer to.
|
||||
|
||||
Document your decisions, *I beg you*.
|
||||
|
||||
### Make an informed decision
|
||||
|
||||
In Part IV, we'll be discussing the trade-offs of using hexagonal architecture compared with other common architectures, and see how it simplifies the jump to microservices when the time is right.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
### Put down the Kool-Aid
|
||||
|
||||
By this point in the guide, you likely fall into one of two camps.
|
||||
|
||||
In the first camp, my converts have sold their possessions and donated the proceeds to the six-sided church. They gather round the fire to sing songs in praise of Hexagonal Architecture, hallowed be its name.
|
||||
|
||||
Across the creek, the second camp hunger for blood. Triggered by the structure, formality and upfront complexity of hexagonal architecture, they prepare to sacrifice the false idol on the bonfire of software engineering trends. They're incensed by the suggestion that hexagonal architecture is superior to others.
|
||||
|
||||
Each camp checks its map of the software development landscape, seeking the most effective path to destroy the other. To their surprise, however, the map shows nothing but a great swamp, without end or beginning. This is "The Middle Ground".
|
||||
|
||||
### Strengths and weaknesses of hexagonal architecture
|
||||
|
||||
Hexagonal architecture is a power tool. It's the hydraulic press of software architectures, and whether it's the optimal architecture for you depends on whether you want to crush a car or a Coke can.
|
||||
|
||||
Parts I to III showed off the strengths of hexagonal architecture:
|
||||
|
||||
- It's highly decoupled, making it a pleasure to evolve and scale.
|
||||
- It greatly increases your unit test surface for rigorous testing of code with complex failure modes.
|
||||
- There's a single source of truth for the logic of each business domain, with a correspondingly simple dependency graph.
|
||||
- There's a home for everything. A predictable project structure keeps your code organized and your team happy.
|
||||
|
||||
Nothing comes for free, though. What are the costs?
|
||||
|
||||
Compared to the Very Bad Application [`1`](https://www.howtocodeit.com/articles/#code-ref-1), our hexagonal app takes a lot more code to achieve the same result. Instead of a raw, axum HTTP handler that simply takes the request body and shoves it straight into an SQLite database, we have multiple layers of abstraction:
|
||||
|
||||
- axum becomes an implementation detail, concealed by our own HTTP package.
|
||||
- The request body must be converted to a domain representation before we can work with it.
|
||||
- Business logic is encapsulated by the `Service` trait and injected into the handler.
|
||||
- SQLite is an implementation detail hidden behind a repository trait implementation.
|
||||
- Anything we pull out of the database has to be converted to a domain representation before it can be used.
|
||||
|
||||
This isn't boilerplate. It's not useless filler. All this extra code is required to achieve the benefits listed above. But clearly there's a threshold below which you'll spend more time writing abstractions and transformations than you'll save through easy scaling and fewer production incidents.
|
||||
|
||||
Translations from transport data types to domain data types aren't free, either. For many apps, the cost is negligible – a tiny fraction of the compute required by the business logic. But for some apps this matters. For embedded software, every byte of memory might count. High-performance systems, such as high-frequency trading software, sacrifice readability for speed. Hexagonal architecture would be a poor fit.
|
||||
|
||||
Let's not forget the barrier to entry. Here we are, thousands of words deep into a hexagonal architecture tutorial. Getting it right requires time and space for active learning. Sustaining a hexagonal codebase requires a clear technical vision and a well-trained team. *Everyone* must understand the rationale and implementation of the architecture.
|
||||
|
||||
Most tech companies fail to invest in their people this way. The training and development available to professional software engineers is dire, and initiatives like adopting hexagonal architecture are led by evangelists learning on their own time. Sadly, they're doomed to fail, because building this way requires a culture that gets everyone on the same page.
|
||||
|
||||
Assuming I haven't scared you off, let's go through some examples to help you decide if hexagonal architecture is right for you.
|
||||
|
||||
#### Solo developers and personal projects
|
||||
|
||||
If you're in the blessed position of being able to keep your entire codebase in your head – and you don't plan to share it – hexagonal architecture will slow you down.
|
||||
|
||||
As a solo dev, you'll have a clear idea of how likely you are to swap out your database, introduce async messaging or migrate to RPC from REST (probably never). And what good will increasing your test surface do if you can just eyeball your app to see that it's working?
|
||||
|
||||
In this scenario, abstractions like services and repositories make your code *more* fragile, not less. It's more code to mentally account for, with no practical upside.
|
||||
|
||||
However, I do recommend small, personal projects as playgrounds to learn and experiment with hexagonal architecture. Building a complete application, even a trivial one, will develop your ability to think hexagonally.
|
||||
|
||||
Legacy code is created by engineers learning new techniques on the job. Take the time to build your intuition in a low-stakes environment. Go deep on details like domain boundaries and error handling. Write *better-than-production* code at home, then bring your expertise to work.
|
||||
|
||||
#### Applications with little business logic
|
||||
|
||||
Does your program tick along happily on an eighth of a vCPU? Is it a lightweight CRUD app that just writes what it's given and reads what it's asked for? Is deserializing a kilobyte of JSON the most ambitious thing it's done this week?
|
||||
|
||||
Don't overcomplicate things. Apps that don't have any business logic don't need ports and adapters – there's nothing to encapsulate.
|
||||
|
||||
If you're compelled to test your request handlers in isolation from your data store, you might still consider using the repository pattern. On the other hand, if your app is so basic that this would be more effort than comprehensively integration testing, int test instead.
|
||||
|
||||
#### Startups that want to scale hard
|
||||
|
||||
You're a one-man band or a small team. Your code just about fits in your head, and the business logic doesn't do anything crazy. But you've got dreams. You want to take this all the way, and you need a rocket to get you there.
|
||||
|
||||
Build hexagonally. If you can do this from day one, all the better. Don't find yourself cruising towards your series A with the engines on fire and half your dev team trying to put it out.
|
||||
|
||||
Hexagonal architecture gives you comprehensive test coverage from the start. It allows you to make the wrong choice of database and spring gracefully away from danger. It lets you support new customer needs without mangling what already works. It's not just an architecture *of* scale, it's an architecture *for scaling*.
|
||||
|
||||
Hexagonal architecture also saves you from true folly – launching your product as microservices.
|
||||
|
||||
In ["How to choose the right domain boundaries"](https://www.howtocodeit.com/articles/#how-to-choose-the-right-domain-boundaries), we learned about the importance of starting with few, large business domains. Each domain encapsulates [entities](https://www.howtocodeit.com/articles/#entities-vs-records) that change atomically.
|
||||
|
||||
We start with large domains because our instincts about where domain boundaries should be are often wrong. User behavior causes applications to evolve organically. As domains get smaller, you'll find yourself correcting the boundaries – and their dependent code – more often.
|
||||
|
||||
Now imagine you work for a stealth start-up building its MVP. Karl, the founder, calls you over to talk architecture. You're concerned by Karl's recent weight loss and accelerated balding. Did he always have that facial tic?
|
||||
|
||||
Your company doesn't have customers yet, but Karl claims to know what the correct domain boundaries are, having seen them in a dream. You think this unlikely, since he doesn't appear to have slept.
|
||||
|
||||
Karl is so confident in these boundaries that he orders you to place each domain in a separate microservice. In the face of your protests, he mutters something about "extreme scale" and "the valuation", and sacrifices a goat to the dark god of network partitions\*.
|
||||
|
||||
This is what go-live looks like with microservices. All the pain of incorrect domain boundaries, now with network hops.
|
||||
|
||||
By starting with a coarse-grained hexagonal monolith, you can refine your domain boundaries in response to observed use patterns. If and when you reach the *organizational* scale where microservices are necessary, it's a relatively simple matter of extracting these battle-tested domains into their own microservices.
|
||||
|
||||
Remember – a hexagonal domain doesn't care where it gets its requests from. It could be a request from another domain running in the same process. It could be an RPC from an internal microservice, or a RESTful request from the outside world. It doesn't matter.
|
||||
|
||||
#### Big team, big monolith, big headache
|
||||
|
||||
Most teams reach for microservices when their monolith has become too large, overloaded and impenetrable to manage. They're resigned to PR conflict purgatory because everyone's code is interdependent and build times are charted by the passage of seasons.
|
||||
|
||||
If this is you, and you have the power to lead architectural change, please consider refactoring your chaotic evil monolith to a hexagonal monolith before making the leap to microservices.
|
||||
|
||||
The situation won't be improved by pulling out a group of features that look like they belong together, putting them somewhere else on the network, and calling it a microservice.
|
||||
|
||||
That initial decomposition is a guess at where the domain boundaries are. Code that once depended on the extracted service will now be making fallible network calls. You will find, inevitably, that some of these should have stayed in-process. You might find that *more* should have been cut away from the monolithic flank. Unfortunately, now that there are many theoretically – but not practically – independent microservices, it's unclear where this orphaned code should live.
|
||||
|
||||
Migration to a hexagonal monolith turns the difficulty down by taking out the networking element. Start by identifying just one business domain you'd like to extract from the monolith. Your first stab at decomposition shouldn't move this to a microservice, but to a clearly bounded domain within the existing monolith, called via ports and adapters.
|
||||
|
||||
Observe how the the rest of the tangled, heretical codebase interfaces with your hexagonal sanctuary. Refine the boundaries until they stabilize. This is much easier without the network hop. When the API to your domain is reasonably stable, it's ready to become a microservice.
|
||||
|
||||
Of course, the reason microservices seem so appealing is because they solve organizational pressures (teams treading on each other's toes) and resource pressures (big boxes to run big apps). How does hexagonal decomposition address that if all the code still lives in the same app?
|
||||
|
||||
An old monolith may take years to decompose, but it's not an all-or-nothing process. Prioritize the code that causes the biggest organizational and resource pressures, grit your teeth for a couple of months to make it hexagonal – *get the domain boundaries right* – then pull those domains into microservices. You don't have to refactor the whole application before extracting stable domain APIs.
|
||||
|
||||
By rushing towards a distributed architecture, you'll turn a bad monolith into bad microservices. *Legacy®: Networked Edition*.
|
||||
|
||||
By guinea-pigging internal domains, you introduce the network complexity only after the business complexity is solved.
|
||||
|
||||
#### Greenfield projects in established companies
|
||||
|
||||
If you work for the kind of large, established business where success is more about saying yes to the right people than writing good code, you may be tempted to stop reading here and go back to speculating when your next stock options will vest. You have my full support.
|
||||
|
||||
However, if you find yourself in a position to influence the direction of a new codebase within a well-resourced, established organization, use hexagonal architecture to cultivate a serene glade within Mirkwood.
|
||||
|
||||
Here's why:
|
||||
|
||||
- The business logic must be at least moderately complex, or the business wouldn't bother assembling a team for it.
|
||||
- Dependencies like databases, message queues, etc. will *certainly* change based on the whims and shifting preferences of higher-ranking managers.
|
||||
- This project – assuming it isn't canned when the quarterly earnings fall short – may be maintained for years, by hundreds of people who aren't you. You owe them a sane project structure with proper test coverage.
|
||||
|
||||
Cultural inertia may be against you. The whole team needs to buy in to hexagonal architecture and understand how it hangs together. If they're as excited as you are to start fresh and do better, you might just pull it off.
|
||||
|
||||
#### High-performance applications
|
||||
|
||||
We all like our apps to go fast, but "fast" is a relative term.
|
||||
|
||||
No user will perceive a speed difference between web app that lets its HTTP request types flow through the whole codebase, and a hexagonal app that parses transport-layer models into domain representations. But these transformations do have a cost, and if you're working on the kind of project where these costs matter, you already know it's too steep.
|
||||
|
||||
If you rely heavily on [zerocopy](https://docs.rs/zerocopy/latest/zerocopy/), if your application shares memory with your network card, if you ever find yourself wondering if rustc is outputting the optimal assembly... my apologies – you don't have the nanoseconds to spare for hexagonal architecture.
|
||||
|
||||
### Adopting hexagonal architecture
|
||||
|
||||
If you've decided that hexagonal architecture meets your needs, the fifth and final section of this guide will leave you with a wealth of practical Rust recipes. Each one will address a specific problem you might encounter as you adopt hexagonal architecture. I'm so excited to hear what you build.
|
||||
|
||||
```
|
||||
🦀
|
||||
🦀
|
||||
🦀
|
||||
```
|
||||
|
||||
*Part five is coming next!*
|
||||
83
Clippings/Reinvent the Wheel.md
Normal file
83
Clippings/Reinvent the Wheel.md
Normal file
@ -0,0 +1,83 @@
|
||||
---
|
||||
title: Reinvent the Wheel
|
||||
source: https://endler.dev/2025/reinvent-the-wheel/
|
||||
author:
|
||||
- "[[Matthias Endler]]"
|
||||
published:
|
||||
created: 2025-05-25
|
||||
description: Personal website of Matthias Endler, a Software Engineer interested in low-level programming and Backend development. Rust, Go
|
||||
tags:
|
||||
- clippings
|
||||
categories:
|
||||
- Clipping
|
||||
---
|
||||
One of the most harmful pieces of advice is to not reinvent the wheel.
|
||||
|
||||
It usually comes from a good place, but is typically given by two groups of people:
|
||||
|
||||
- those who tried to invent a wheel themselves and know how hard it is
|
||||
- those who never tried to invent a wheel and blindly follow the advice
|
||||
|
||||
Either way, both positions lead to a climate where curiosity and exploration gets discouraged. I’m glad that some people didn’t follow that advice; we owe them many of the conveniences of modern life.
|
||||
|
||||
Even on a surface level, the advice is bad: We have much better wheels today than 4500–3300 BCE when the first wheel was invented. It was also *crucially* important that wheels got reinvented throughout civilizations and cultures.
|
||||
|
||||
**Note:** When I say “wheel” throughout this post, please replace it with whatever tool, protocol, service, technology, or other invention you’re personally interested in.
|
||||
|
||||
## Inventing Wheels Is Learning
|
||||
|
||||
> **“What I cannot create, I do not understand”**
|
||||
> – [Richard Feynman](https://en.wikipedia.org/wiki/Richard_Feynman), Physicist and Nobel Prize Winner
|
||||
|
||||
To *really* understand something on a fundamental level, you have to be able to implement a toy version first. It doesn’t matter if it’s any good; you can throw it away later.
|
||||
|
||||
In Computer Science, for example, there are many concepts that are commonly assumed to be beyond the abilities of mere mortals: protocols, cryptography, and web servers come to mind.
|
||||
|
||||
More people should know how these things work. And therefore I think people should not be afraid to recreate them.
|
||||
|
||||
## Everything Is A Rabbit Hole
|
||||
|
||||
Too often, fundamental things are taken for granted. For example strings or paths are super complicated concepts in programming. It’s a great exercise to implement a string or a path library yourself if you’re interested in how they work.
|
||||
|
||||
Even if nobody ends up using your work, I bet you’ll learn a lot. For example:
|
||||
|
||||
- There is an infinite complexity in everyday things.
|
||||
- Building something that even a single other person finds useful is a humbling experience.
|
||||
- Humans like you created these abstractions. They are not perfect and you can make different tradeoffs in your own design.
|
||||
|
||||
On the last point, everything is a tradeoff and there are dozens, sometimes hundreds of footguns with every toy problem.
|
||||
|
||||
Along the way, you will have to make decisions about correctness, simplicity, functionality, scalability, performance, resource usage, portability, and so on.
|
||||
|
||||
Your solution can be great in some of these things, but not all of them and not for all users. That also implies that existing solutions have flaws and might not be designed to solve your particular problem; no matter how well-established the solution is.
|
||||
|
||||
Going down rabbit holes is fun in its own way, but there is one other benefit: It is one of the few ways to level up as an engineer… but only if you don’t give up before you end up with a working version of what you tried to explore. If you jump between projects too often, you will learn nothing.
|
||||
|
||||
## Reasons for Reinventing the Wheel
|
||||
|
||||
There are great reasons to reinvent the wheel:
|
||||
|
||||
- Build a better wheel (for some definition of better)
|
||||
- Learn how wheels are made
|
||||
- Teach others about wheels
|
||||
- Learn about the inventors of wheels
|
||||
- Be able to change wheels or fix them when they break
|
||||
- Learn the tools needed to make wheels along the way
|
||||
- Learn a tiny slice of what it means to build a larger system (such as a vehicle)
|
||||
- Help someone in need of a very special wheel. Maybe for a wheelchair?
|
||||
|
||||
Who knows? The wheel you come up with might not be the best use for a car, but maybe for a… skateboard or a bike? Or you fail building a nicer wheel, but you come up with a better way to test wheels along the way. Heck, your wheel might not even be meant for transportation at all! It might be a potter’s wheel, “a machine used in the shaping (known as throwing) of clay into round ceramic ware” [according to Wikipedia](https://en.wikipedia.org/wiki/Wheel). You might end up building a totally different kind of wheel like a steering wheel or a flywheel. We need more people who think outside the box.
|
||||
|
||||
## Reuse vs Reinvent
|
||||
|
||||
Of course, don’t disregard the works of others – study their work and reuse where you see fit. Don’t reinvent the wheel out of distrust or ignorance of the work of others. On the other side, if you never tried to put your knowledge to the test, how would you ever learn enough about your field to advance it?
|
||||
|
||||
I observed you can move very quickly by running little experiments. Especially in software engineering, building small prototypes is cheap and quick. Solve your own problem, start small, keep it simple, iterate.
|
||||
|
||||
So, with all of the above, here’s my advice:
|
||||
|
||||
**Reinvent for insight. Reuse for impact.**
|
||||
|
||||
Thanks for reading! If you're looking to level up your programming skills, check out [CodeCrafters](https://app.codecrafters.io/join?via=mre) - it's the platform I genuinely recommend to friends. Try it free and get 40% off paid plans.
|
||||
|
||||
Full disclosure: I earn a commission on subscriptions, so you'll be supporting my work while improving your coding skills.
|
||||
366
Clippings/Sources, Bytecode, Debugging The IntelliJ IDEA Blog.md
Normal file
366
Clippings/Sources, Bytecode, Debugging The IntelliJ IDEA Blog.md
Normal file
@ -0,0 +1,366 @@
|
||||
---
|
||||
title: Sources, Bytecode, Debugging | The IntelliJ IDEA Blog
|
||||
source: https://blog.jetbrains.com/idea/2025/05/sources-bytecode-debugging/
|
||||
author:
|
||||
- "[[Igor Kulakov]]"
|
||||
published: 2025-05-26
|
||||
created: 2025-05-28
|
||||
description: This blog post explores how Java and debuggers work behind the scenes.
|
||||
tags:
|
||||
- clippings
|
||||
categories:
|
||||
- Clipping
|
||||
---
|
||||
## Sources, Bytecode, Debugging
|
||||
|
||||
When debugging Java programs, developers are often under the impression that they’re interacting directly with the source code. This isn’t surprising – Java’s tooling does such an excellent job of hiding the complexity that it almost feels as if the source code exists at runtime.
|
||||
|
||||
If you’re just starting with Java, you likely remember those diagrams showing how the compiler transforms source code into bytecode, which is then executed by the JVM. You might also wonder: if that’s the case, why do we examine and step through the source code rather than the bytecode? How does the JVM know anything about our sources?
|
||||
|
||||
This article is a little different from my on debugging. Instead of focusing on how to debug a specific problem, such as an unresponsive app or a memory leak, it explores how Java and debuggers work behind the scenes. Stick around – as always, a couple of handy tricks are included.
|
||||
|
||||
Let’s start with a quick recap. The diagrams found in Java books and guides are indeed correct – the JVM executes bytecode.
|
||||
|
||||
Consider the following class as an example:
|
||||
|
||||
package dev.flounder;
|
||||
|
||||
public class Calculator {
|
||||
|
||||
int sum (int a, int b) {
|
||||
|
||||
return a + b;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
package dev.flounder; public class Calculator { int sum(int a, int b) { return a + b; } }
|
||||
|
||||
```
|
||||
package dev.flounder;
|
||||
|
||||
public class Calculator {
|
||||
int sum(int a, int b) {
|
||||
return a + b;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
When compiled, the `sum()` method will turn into the following bytecode:
|
||||
|
||||
```
|
||||
int sum(int, int);
|
||||
descriptor: (II)I
|
||||
flags: (0x0000)
|
||||
Code:
|
||||
stack=2, locals=3, args_size=3
|
||||
0: iload_1
|
||||
1: iload_2
|
||||
2: iadd
|
||||
3: ireturn
|
||||
```
|
||||
|
||||
**Tip**: You can inspect the bytecode of your classes using the `javap -v` command included with the JDK. If you are using IntelliJ IDEA, you can also do this from the IDE: after building your project, select a class, and then click *View* | *Show Bytecode*.
|
||||
|
||||
**Note**: Since class files are binary, citing their raw contents would not be informative. For readability, the examples in this article follow the format of `javap -v` output.
|
||||
|
||||
Bytecode consists of a series of compact platform-independent instructions. In the example above:
|
||||
|
||||
1. `iload_1` and `iload_2` load the variables onto the operand stack.
|
||||
2. `iadd` adds the contents of the operand stack, leaving a single result value on it.
|
||||
3. `ireturn` returns the value from the operand stack.
|
||||
|
||||
In addition to instructions, bytecode files also include information on the constants, the number of parameters, local variables, and the depth of the operand stack. This is all the JVM needs to execute a program written in a JVM language, such as Java, Kotlin, or Scala.
|
||||
|
||||
Since bytecode looks completely different from your source code, referring to it while debugging would be inefficient. For this reason, the interfaces of Java debuggers – such as the JDB (the console debugger bundled with the JDK) or the one in IntelliJ IDEA – display the source code rather than bytecode. This allows you to debug the code that you wrote without having to think about the underlying bytecode being executed.
|
||||
|
||||
For example, your interaction with the JDB might look like this:
|
||||
|
||||
```
|
||||
Initializing jdb ...
|
||||
|
||||
> stop at dev.flounder.Calculator:5
|
||||
|
||||
Deferring breakpoint dev.flounder.Calculator:5.
|
||||
It will be set after the class is loaded.
|
||||
|
||||
> run
|
||||
|
||||
run dev/flounder/Main
|
||||
Set uncaught java.lang.Throwable
|
||||
Set deferred uncaught java.lang.Throwable
|
||||
VM Started: Set deferred breakpoint dev.flounder.Calculator:5
|
||||
Breakpoint hit: "thread=main", dev.flounder.Calculator.sum(), line=5 bci=0
|
||||
|
||||
> locals
|
||||
|
||||
Method arguments:
|
||||
a = 1
|
||||
b = 2
|
||||
```
|
||||
|
||||
IntelliJ IDEA will display the debug-related information in the editor and in the *Debug* tool window:
|
||||
|
||||
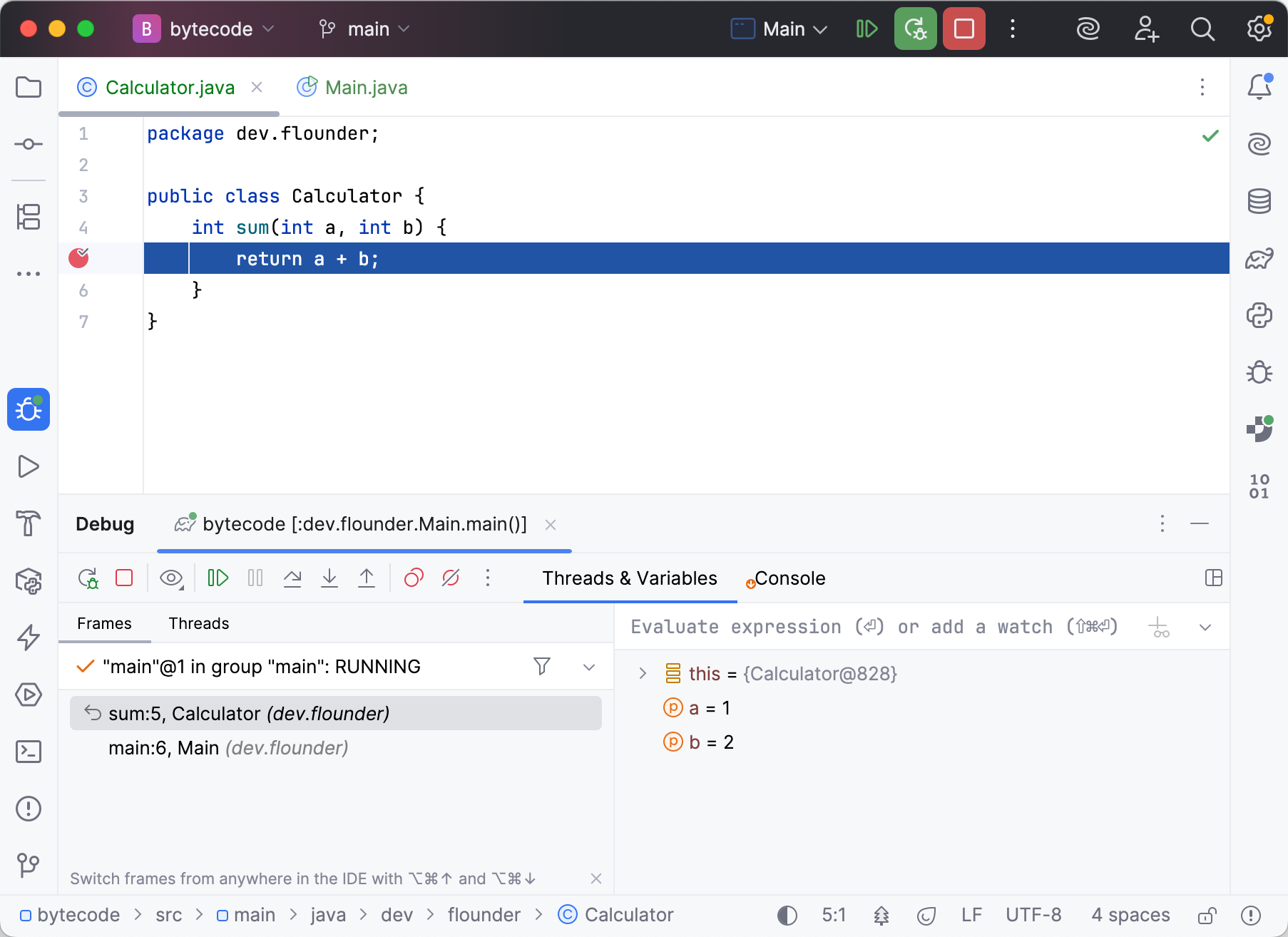
|
||||
|
||||
As you can see, both debuggers use the correct variable names and reference valid lines from our code snippet above.
|
||||
|
||||
Since the runtime doesn’t have access to the source files, it must collect this data elsewhere. This is where debug information comes into play. Debug information (also referred to as debug symbols) is compact data that links the bytecode to the application’s sources. It is included in the `.class` files during compilation.
|
||||
|
||||
There are three types of debug information:
|
||||
|
||||
- [Line numbers](https://blog.jetbrains.com/idea/2025/05/sources-bytecode-debugging/#line-numbers)
|
||||
- [Variable names](https://blog.jetbrains.com/idea/2025/05/sources-bytecode-debugging/#variable-names)
|
||||
- [Source file names](https://blog.jetbrains.com/idea/2025/05/sources-bytecode-debugging/#source-file-names)
|
||||
[
|
||||
|
||||
In the following chapters, I’ll briefly explain each type of debug information and how the debugger uses it.
|
||||
|
||||
Line number information is stored in the `LineNumberTable` attribute within the bytecode file, and it looks like this:
|
||||
|
||||
LineNumberTable:
|
||||
|
||||
line 5: 0
|
||||
|
||||
line 6: 2
|
||||
|
||||
LineNumberTable: line 5: 0 line 6: 2
|
||||
|
||||
```
|
||||
LineNumberTable:
|
||||
line 5: 0
|
||||
line 6: 2
|
||||
```
|
||||
|
||||
The table above tells the debugger the following:
|
||||
|
||||
- Line `5` contains the instruction at offset `0`
|
||||
- Line `6` contains the instruction at offset `2`
|
||||
|
||||
This type of debug information helps external tools, such as debuggers or profilers, trace the exact line where the program executes in the source code.
|
||||
|
||||
](https://blog.jetbrains.com/idea/2025/05/sources-bytecode-debugging/#source-file-names)
|
||||
|
||||
[Importantly, line number information is also used for source references in exception stack traces. In the following example, I compiled code from](https://blog.jetbrains.com/idea/2025/05/sources-bytecode-debugging/#source-file-names) [my other tutorial](https://flounder.dev/posts/efficient-debugging-exceptions) without line number information:
|
||||
|
||||
```
|
||||
Exception in thread "main" java.lang.NumberFormatException: For input string: ""
|
||||
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
|
||||
at java.base/java.lang.Integer.parseInt(Integer.java:672)
|
||||
at java.base/java.lang.Integer.parseInt(Integer.java:778)
|
||||
at dev.flounder.Airports.parse(Airports.java)
|
||||
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
|
||||
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:133)
|
||||
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1939)
|
||||
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
|
||||
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
|
||||
at java.base/java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
|
||||
at java.base/java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
|
||||
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
|
||||
at java.base/java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:596)
|
||||
at dev.flounder.Airports.main(Airports.java)
|
||||
```
|
||||
|
||||
The executable compiled without line number information produced a stack trace that lacks line numbers for the calls corresponding to my project code. The calls from the standard library and dependencies still include line numbers because they have been compiled separately and weren’t affected.
|
||||
|
||||
Besides stack traces, you may encounter a similar situation where line numbers are involved, for example, in IntelliJ IDEA’s *Frames* tab:
|
||||
|
||||

|
||||
|
||||
So, if you see `-1` instead of actual line numbers and want to avoid this, make sure your program is compiled with line number information.
|
||||
|
||||
**Tip**: You can view bytecode offset right in IntelliJ IDEA’s *Frames* tab. For this, add the following [registry key](https://youtrack.jetbrains.com/articles/SUPPORT-A-1030/How-to-edit-IntelliJ-IDE-registry): `debugger.stack.frame.show.code.index=true`.
|
||||
|
||||
|
||||
|
||||
Like line number information, variable names are stored in class files. The variable table for our example looks as follows:
|
||||
|
||||
LocalVariableTable:
|
||||
|
||||
Start Length Slot Name Signature
|
||||
|
||||
0 4 0 this Ldev/flounder/Calculator;
|
||||
|
||||
0 4 1 a I
|
||||
|
||||
0 4 2 b I
|
||||
|
||||
LocalVariableTable: Start Length Slot Name Signature 0 4 0 this Ldev/flounder/Calculator; 0 4 1 a I 0 4 2 b I
|
||||
|
||||
```
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 4 0 this Ldev/flounder/Calculator;
|
||||
0 4 1 a I
|
||||
0 4 2 b I
|
||||
```
|
||||
|
||||
It contains the following information:
|
||||
|
||||
1. **Start**: The bytecode offset where the scope of this variable begins.
|
||||
2. **Length**: The number of instructions during which this variable remains in scope.
|
||||
3. **Slot**: The index at which this variable is stored for reference.
|
||||
4. **Name**: The variable’s name as it appears in the source code.
|
||||
5. **Signature**: The variable’s data type, expressed in Java’s type signature notation.
|
||||
|
||||
If variables are missing from the debug information, some debugger functionality might not work as expected, and you will see `slot_1`, `slot_2`, etc. instead of the actual variable names.
|
||||
|
||||
|
||||
|
||||
This type of debug information indicates which source file was used to compile the class. Like line number information, its presence in the class files affects not only external tooling, but also the stack traces that your program generates:
|
||||
|
||||
```
|
||||
Exception in thread "main" java.lang.NumberFormatException: For input string: ""
|
||||
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
|
||||
at java.base/java.lang.Integer.parseInt(Integer.java:672)
|
||||
at java.base/java.lang.Integer.parseInt(Integer.java:778)
|
||||
at dev.flounder.Airports.parse(Unknown Source)
|
||||
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:197)
|
||||
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:133)
|
||||
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1939)
|
||||
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
|
||||
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
|
||||
at java.base/java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
|
||||
at java.base/java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
|
||||
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
|
||||
at java.base/java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:596)
|
||||
at dev.flounder.Airports.main(Unknown Source)
|
||||
```
|
||||
|
||||
Without source file names, the corresponding stack trace calls will be marked as `Unknown Source`.
|
||||
|
||||
As a developer, you have control over whether to include debug information in your executables and, if so, which types to include. You can manage this by using the `-g` compiler argument, like this:
|
||||
|
||||
`javac -g:lines,vars,source`
|
||||
|
||||
Here is the syntax:
|
||||
|
||||
| Command | Result |
|
||||
| --- | --- |
|
||||
| `javac` | Compiles the application with line numbers and source file names (default for most compilers) |
|
||||
| `javac -g` | Compiles the application with all available debug information: line numbers, variables, and source file names |
|
||||
| `javac -g:lines,source` | Compiles the application with the specified types of debug information – line numbers and source file names in this example |
|
||||
| `javac -g:none` | Compiles the application without the debug information |
|
||||
|
||||
**Note**: Defaults might vary between compilers. Some of them completely exclude debug information unless instructed otherwise.
|
||||
|
||||
If you are using a build system, such as Maven or Gradle, you can pass the same options through compiler arguments.
|
||||
|
||||
Maven example:
|
||||
|
||||
< plugin \>
|
||||
|
||||
< groupId \> org.apache.maven.plugins < /groupId \>
|
||||
|
||||
< artifactId \> maven-compiler-plugin < /artifactId \>
|
||||
|
||||
< version \> 3.11.0 < /version \>
|
||||
|
||||
< configuration \>
|
||||
|
||||
< compilerArgs \>
|
||||
|
||||
< arg \> \-g:vars,lines < /arg \>
|
||||
|
||||
< /compilerArgs \>
|
||||
|
||||
< /configuration \>
|
||||
|
||||
< /plugin \>
|
||||
|
||||
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.11.0</version> <configuration> <compilerArgs> <arg>-g:vars,lines</arg> </compilerArgs> </configuration> </plugin>
|
||||
|
||||
```
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-compiler-plugin</artifactId>
|
||||
<version>3.11.0</version>
|
||||
<configuration>
|
||||
<compilerArgs>
|
||||
<arg>-g:vars,lines</arg>
|
||||
</compilerArgs>
|
||||
</configuration>
|
||||
</plugin>
|
||||
```
|
||||
|
||||
Gradle example:
|
||||
|
||||
tasks.compileJava {
|
||||
|
||||
options.compilerArgs.add ("-g:vars,lines")
|
||||
|
||||
}
|
||||
|
||||
tasks.compileJava { options.compilerArgs.add("-g:vars,lines") }
|
||||
|
||||
```
|
||||
tasks.compileJava {
|
||||
options.compilerArgs.add("-g:vars,lines")
|
||||
}
|
||||
```
|
||||
|
||||
As we’ve just seen, debug symbols enable the debugging process, which is convenient during development. For this reason, debug symbols are usually included in development builds. In production builds, they are often excluded; However, this ultimately depends on the type of project you are working on.
|
||||
|
||||
Here are a couple of things you may want to consider:
|
||||
|
||||
Since a debugger can be used to tamper with your program, including debug information makes your application slightly more vulnerable to hacking and reverse engineering, which may be undesirable for some applications.
|
||||
|
||||
Although the absence of debug symbols might make it somewhat more difficult to interfere with your program using a debugger, it does not fully protect it. Debugging remains possible even with partial or missing debug information, so this alone will not prevent a determined individual from accessing your program’s internals. Therefore, if you are concerned about the risk of reverse engineering, you should employ additional measures, such as code obfuscation.
|
||||
|
||||
The more information an executable contains, the larger it becomes. Exactly how much larger depends on various factors. The size of a particular class file might easily be dominated by the number of instructions and the size of the constant pool, making it impractical to provide a universal estimate. Still, to demonstrate that the difference can be substantial, I experimented with [Airports.java](https://flounder.dev/posts/efficient-debugging-exceptions), which we used earlier to compare stack traces. The results are **4,460** bytes without debug information compared to **5,664** bytes with it.
|
||||
|
||||
In most cases, including debug symbols won’t hurt. However, if executable size is a concern, as is often the case with embedded systems, you might want to exclude debug symbols from your binaries.
|
||||
|
||||
Typically, the required sources reside within your project, so the IDE will have no trouble finding them. However, there are less common situations – for example, when the source code needed for debugging is outside your project, such as when stepping into a library used by your code.
|
||||
|
||||
In this case, you need to add source files manually: either by placing them under a [sources root](https://www.jetbrains.com/help/idea/content-roots.html) or by specifying them as a dependency. During debugging, IntelliJ IDEA will automatically detect and match these files with the classes executed by the JVM.
|
||||
|
||||
In most cases, you would build, launch, and debug an application in the same IDE, using the original project. But what if you have only a few source files, and the project itself is missing?
|
||||
|
||||
Here’s a bare-bones debugging setup that will do the trick:
|
||||
|
||||
1. Create an empty Java project.
|
||||
2. Add the source files under a sources root or specify them as a dependency.
|
||||
3. Launch the target application with the debug agent. In Java, this is typically done by adding a VM option, such as: `-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005`.
|
||||
4. Create a [Remote JVM Debug](https://www.jetbrains.com/help/idea/attach-to-process.html#create-rc) run configuration with the correct connection details. Use this run configuration to attach the debugger to the target application.
|
||||
|
||||
With this setup, you can debug a program without accessing the original project. IntelliJ IDEA will match the available sources with the runtime classes and let you use them in a debugging session. This way, even a single project or library class gives you an entry point for debugging.
|
||||
|
||||
For a hands-on example, check out [Debugger.godMode() – Hacking JVM Applications With the Debugger](https://flounder.dev/posts/debugger-god-mode), where we use this technique to change a program’s behavior without accessing its source code.
|
||||
|
||||
One confusing situation you might encounter during debugging is when your application appears suspended at a blank line or when the line numbers in the *Frames* tab don’t match those in the editor:
|
||||
|
||||
|
||||
|
||||
This occurs when debugging decompiled code (which we’ll discuss in another article) or when the source code doesn’t fully match the bytecode that the JVM is executing.
|
||||
|
||||
Since the only link between bytecode and a particular source file is the name of the file and its classes, the debugger has to rely on this information, assisted by some heuristics. This works well for most situations. However, the version of the file on disk may differ from the one used to compile the application. In the case of a partial match, the debugger will identify the discrepancies and attempt to reconcile them rather than failing fast. Depending on the extent of the differences, this might be useful, for example, if the only source that you have isn’t the closest match.
|
||||
|
||||
Fortunately, if you have the exact version of the sources elsewhere, you can fix this issue by adding them to the project and re-running the debug session.
|
||||
|
||||
In this article, we’ve explored the connection between source files, bytecode, and the debugger. While not strictly required for day-to-day coding, having a clearer picture of what happens under the hood can give you a stronger grasp of the ecosystem and may occasionally help you out of non-standard situations and configuration problems. I hope you found the theory and tips useful!
|
||||
|
||||
There are still many more topics to come in this series, so stay tuned for the next one. If there’s anything specific you’d like to see covered, or if you have ideas and feedback, we’d love to hear from you!
|
||||
|
||||
- Share
|
||||
|
||||
[](https://jb.gg/blog-idea-download)
|
||||
|
||||
#### Subscribe to IntelliJ IDEA Blog updates
|
||||
|
||||

|
||||
|
||||
[](https://blog.jetbrains.com/idea/2025/05/do-you-really-know-java/)
|
||||
|
||||
[](https://blog.jetbrains.com/idea/2025/05/finding-your-tribe-jugs-unveiled/)
|
||||
|
||||
[Everything you ever wanted to know about Java User Groups (JUGs)!](https://blog.jetbrains.com/idea/2025/05/finding-your-tribe-jugs-unveiled/)
|
||||
|
||||
[](https://blog.jetbrains.com/idea/2025/05/building-cloud-ready-apps-locally-spring-boot-aws-and-localstack-in-action/)
|
||||
|
||||
[Developing an application with AWS services can introduce significant local‑development hurdles. Often, developers don’t receive timely AWS access, or a sysadmin inadvertently grants credentials for the wrong account – only to fix the error a week later. Then, when engineers discover they still lack…](https://blog.jetbrains.com/idea/2025/05/building-cloud-ready-apps-locally-spring-boot-aws-and-localstack-in-action/)
|
||||
|
||||
[](https://blog.jetbrains.com/idea/2025/04/debugging-java-code-in-intellij-idea/)
|
||||
|
||||
[In this blog post, we will look at how to debug Java code using the IntelliJ IDEA debugger. We will look at how to fix a failing test, how to find out where an \`Exception\` is thrown, and how to find problems with our data. And we will learn some neat tricks about the debugger in the process! …](https://blog.jetbrains.com/idea/2025/04/debugging-java-code-in-intellij-idea/)
|
||||
155
Clippings/The Best Programmers I Know.md
Normal file
155
Clippings/The Best Programmers I Know.md
Normal file
@ -0,0 +1,155 @@
|
||||
---
|
||||
title: The Best Programmers I Know
|
||||
source: https://endler.dev/2025/best-programmers/
|
||||
author:
|
||||
- "[[Matthias Endler]]"
|
||||
published:
|
||||
created: 2025-05-25
|
||||
description: Personal website of Matthias Endler, a Software Engineer interested in low-level programming and Backend development. Rust, Go
|
||||
tags:
|
||||
- clippings
|
||||
categories:
|
||||
- Clipping
|
||||
---
|
||||
I have met a lot of developers in my life. Lately, I asked myself: “What does it take to be one of the best? What do they all have in common?”
|
||||
|
||||
In the hope that this will be an inspiration to someone out there, I wrote down the traits I observed in the most exceptional people in our craft. I wish I had that list when I was starting out. Had I followed this path, it would have saved me a lot of time.
|
||||
|
||||
## Read the Reference
|
||||
|
||||
If there was one thing that I should have done as a young programmer, it would have been to *read the reference* of the thing I was using. I.e. read the [Apache Webserver Documentation](https://httpd.apache.org/docs/2.4/), the [Python Standard Library](https://docs.python.org/3/library/index.html), or the [TOML spec](https://toml.io/en/v1.0.0).
|
||||
|
||||
Don’t go to Stack Overflow, don’t ask the LLM, don’t *guess*, just go straight to the **source**. Oftentimes, it’s surprisingly accessible and well-written.
|
||||
|
||||
## Know Your Tools Really Well
|
||||
|
||||
Great devs understand the technologies they use on a **fundamental level**.
|
||||
|
||||
It’s one thing to be able to *use* a tool and a whole other thing to truly *grok* (understand) it. A mere user will fumble around, get confused easily, hold it wrong and not optimize the config.
|
||||
|
||||
An expert goes in (after reading the reference!) and sits down to write a config for the tool of which they understand every single line and can explain it to a colleague. That leaves no room for doubt!
|
||||
|
||||
To know a tool well, you have to know:
|
||||
|
||||
- its history: who created it? Why? To solve which problem?
|
||||
- its present: who maintains it? Where do they work? On what?
|
||||
- its limitations: when is the tool not a good fit? When does it break?
|
||||
- its ecosystem: what libraries exist? Who uses it? What plugins?
|
||||
|
||||
For example, if you are a backend engineer and you make heavy use of Kafka, I expect you to know a lot about Kafka – not just things you read on Reddit. At least that’s what I expect if you want to be one of the best engineers.
|
||||
|
||||
As in **Really Read the Error Message and Try to Understand What’s Written**. Turns out, if you just sit and meditate about the error message, it starts to speak to you. The best engineers can infer a ton of information from very little context. Just by reading the error message, you can fix most of the problems on your own.
|
||||
|
||||
It also feels like a superpower if you help someone who doesn’t have that skill. Like [“reading from a cup”](https://en.m.wikipedia.org/wiki/Tasseography) or so.
|
||||
|
||||
## Break Down Problems
|
||||
|
||||
Everyone gets stuck at times. The best know how to get unstuck. They simplify problems until they become digestible. That’s a hard skill to learn and requires a ton of experience. Alternatively, you just have awesome problem-solving skills, e.g., you’re clever. If not, you can train it, but there is no way around breaking down hard problems. There are problems in this world that are too hard to solve at once for anyone involved.
|
||||
|
||||
If you work as a professional developer, that is the bulk of the work you get paid to do: breaking down problems. If you do it right, it will feel like cheating: you just solve simple problems until you’re done.
|
||||
|
||||
## Don’t Be Afraid To Get Your Hands Dirty
|
||||
|
||||
The best devs I know read a lot of code and they are not afraid to touch it. They never say “that’s not for me” or “I can’t help you here.” Instead, they just start and learn. Code is *just code*. They can just pick up any skill that is required with time and effort. Before you know it, they become the go-to person in the team for whatever they touched. Mostly because they were the only ones who were not afraid to touch it in the first place.
|
||||
|
||||
## Always Help Others
|
||||
|
||||
A related point. Great engineers are in high demand and are always busy, but they always try to help. That’s because they are naturally curious and their supportive mind is what made them great engineers in the first place. It’s a sheer joy to have them on your team, because they are problem solvers.
|
||||
|
||||
## Write
|
||||
|
||||
Most awesome engineers are well-spoken and happy to share knowledge.
|
||||
|
||||
The best have some outlet for their thoughts: blogs, talks, open source, or a combination of those.
|
||||
|
||||
I think there is a strong correlation between writing skills and programming. All the best engineers I know have good command over at least one human language – often more. Mastering the way you write is mastering the way you think and vice versa. A person’s writing style says so much about the way they think. If it’s confusing and lacks structure, their coding style will be too. If it’s concise, educational, well-structured, and witty at times, their code will be too.
|
||||
|
||||
Excellent programmers find joy in playing with words.
|
||||
|
||||
## Never Stop Learning
|
||||
|
||||
Some of the best devs I know are 60+ years old. They can run circles around me. Part of the reason is that they keep learning. If there is a new tool they haven’t tried or a language they like, they will learn it. This way, they always stay on top of things without much effort.
|
||||
|
||||
That is not to be taken for granted: a lot of people stop learning really quickly after they graduate from University or start in their first job. They get stuck thinking that what they got taught in school is the “right” way to do things. Everything new is bad and not worth their time. So there are 25-year-olds who are “mentally retired” and 68-year-olds who are still fresh in their mind. I try to one day belong to the latter group.
|
||||
|
||||
Somewhat related, the best engineers don’t follow trends, but they will always carefully evaluate the benefits of new technology. If they dismiss it, they can tell you exactly *why*, when the technology would be a good choice, and what the alternatives are.
|
||||
|
||||
## Status Doesn’t Matter
|
||||
|
||||
The best devs talk to principal engineers and junior devs alike. There is no hierarchy. They try to learn from everyone, young and old. The newcomers often aren’t entrenched in office politics yet and still have a fresh mind. They don’t know why things are *hard* and so they propose creative solutions. Maybe the obstacles from the past are no more, which makes these people a great source of inspiration.
|
||||
|
||||
## Build a Reputation
|
||||
|
||||
You can be a solid engineer if you **do** good work, but you can only be one of the best if you’re **known** for your good work; at least within a (larger) organization.
|
||||
|
||||
There are many ways to build a reputation for yourself:
|
||||
|
||||
- You built and shipped a critical service for a (larger) org.
|
||||
- You wrote a famous tool
|
||||
- You contribute to a popular open source tool
|
||||
- You wrote a book that is often mentioned
|
||||
|
||||
Why do I think it is important to be known for your work? All of the above are ways to extend your radius of impact in the community. Famous developers impact way more people than non-famous developers. There’s only so much code you can write. If you want to “scale” your impact, you have to become a thought leader.
|
||||
|
||||
Building a reputation is a long-term goal. It doesn’t happen overnight, nor does it have to. And it won’t happen by accident. You show up every day and do the work. Over time, the work will speak for itself. More people will trust you and your work and they will want to work with you. You will work on more prestigious projects and the circle will grow.
|
||||
|
||||
I once heard about this idea that your latest work should overshadow everything you did before. That’s a good sign that you are on the right track.
|
||||
|
||||
## Have Patience
|
||||
|
||||
You need patience with computers and humans. Especially with yourself. Not everything will work right away and people take time to learn. It’s not that people around you are stupid; they just have incomplete information. Without patience, it will feel like the world is against you and everyone around you is just incompetent. That’s a miserable place to be. You’re too clever for your own good.
|
||||
|
||||
To be one of the best, you need an incredible amount of patience, focus, and dedication. You can’t afford to get distracted easily if you want to solve hard problems. You have to return to the keyboard to get over it. You have to put in the work to push a project over the finishing line. And if you can do so while not being an arrogant prick, that’s even better. That’s what separates the best from the rest.
|
||||
|
||||
## Never Blame the Computer
|
||||
|
||||
Most developers blame the software, other people, their dog, or the weather for flaky, seemingly “random” bugs.
|
||||
|
||||
The best devs don’t.
|
||||
|
||||
No matter how erratic or mischievous the behavior of a computer seems, there is *always* a logical explanation: you just haven’t found it yet!
|
||||
|
||||
The best keep digging until they find the reason. They might not find the reason immediately, they might never find it, but they never blame external circumstances.
|
||||
|
||||
With this attitude, they are able to make incredible progress and learn things that others fail to. When you mistake bugs for incomprehensible magic, magic is what it will always be.
|
||||
|
||||
## Don’t Be Afraid to Say “I Don’t Know”
|
||||
|
||||
In job interviews, I pushed candidates hard to at least say “I don’t know” once. The reason was not that I wanted to look superior (although some people certainly had that impression). No, I wanted to reach the boundary of their knowledge. I wanted to stand with them on the edge of what they thought they knew. Often, I myself didn’t know the answer. And to be honest, I didn’t care about the answer. What I cared about was when people bullshitted their way through the interview.
|
||||
|
||||
The best candidates said “Huh, I don’t know, but that’s an interesting question! If I had to guess, I would say…” and then they would proceed to deduce the answer. That’s a sign that you have the potential to be a great engineer.
|
||||
|
||||
If you are afraid to say “I don’t know”, you come from a position of hubris or defensiveness. I don’t like bullshitters on my team. Better to acknowledge that you can’t know everything. Once you accept that, you allow yourself to learn. “The important thing is that you don’t stop asking questions,” said Albert Einstein.
|
||||
|
||||
## Don’t Guess
|
||||
|
||||
“In the Face of Ambiguity, Refuse the Temptation to Guess” That is one of my favorite rules in [PEP 20 – The Zen of Python](https://peps.python.org/pep-0020/).
|
||||
|
||||
And it’s so, so tempting to guess!
|
||||
|
||||
I’ve been there many times and I failed with my own ambition.
|
||||
|
||||
When you guess, two things can happen:
|
||||
|
||||
- In the **best case** you’re wrong and your incorrect assumptions lead to a bug.
|
||||
- In the **worst case** you are right… and you’ll never stop and second guess yourself. You build up your mental model based on the wrong assumptions. This can haunt you for a long time.
|
||||
|
||||
Again, resist the urge to guess. Ask questions, read the reference, use a debugger, be thorough. Do what it takes to get the answer.
|
||||
|
||||
## Keep It Simple
|
||||
|
||||
Clever engineers write clever code. Exceptional engineers write simple code.
|
||||
|
||||
That’s because most of the time, simple is enough. And simple is more maintainable than complex. Sometimes it *does* matter to get things right, but knowing the difference is what separates the best from the rest.
|
||||
|
||||
You can achieve a whole lot by keeping it simple. Focus on the right things.
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
The above is not a checklist or a competition; and great engineering is not a race.
|
||||
|
||||
Just don’t trick yourself into thinking that you can skip the hard work. There is no shortcut. Good luck with your journey.
|
||||
|
||||
Thanks for reading! If you're looking to level up your programming skills, check out [CodeCrafters](https://app.codecrafters.io/join?via=mre) - it's the platform I genuinely recommend to friends. Try it free and get 40% off paid plans.
|
||||
|
||||
Full disclosure: I earn a commission on subscriptions, so you'll be supporting my work while improving your coding skills.
|
||||
5
Daily/2025-05-22.md
Normal file
5
Daily/2025-05-22.md
Normal file
@ -0,0 +1,5 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
![[Lab Notebook Mai 2025_250523_103854.jpg]]
|
||||
8
Daily/2025-05-27.md
Normal file
8
Daily/2025-05-27.md
Normal file
@ -0,0 +1,8 @@
|
||||
# Cross Invoicing Workshop
|
||||
|
||||
1. Introduce the goal of the workshop
|
||||
1. We want to tailor the cross invoicing application to the new data mesh architecture -> show data mesh architecture
|
||||
2. Architecture of current cross invoicing (pavel)
|
||||
3. Live Discussion of possible Data Mesh solution
|
||||
4. Identifying work packages for implementation -> create epics
|
||||
5. Vereinbarungen festhalten
|
||||
11
Daily/2025-05-28.md
Normal file
11
Daily/2025-05-28.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
# Tasks
|
||||
|
||||
- [x] #task Connect [[Supabase]] ✅ 2025-05-28
|
||||
|
||||
# Notes
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
16
Daily/2025-06-04.md
Normal file
16
Daily/2025-06-04.md
Normal file
@ -0,0 +1,16 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
created: 2025-06-04
|
||||
brushed: "true"
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Tests für https://jira.vi.vector.int/browse/VTR-3549 ✅ 2025-06-04
|
||||
- [ ] Concept for keeping the history of memberships in RMS #retention
|
||||
- [x] Rollout RMS to test ✅ 2025-06-04
|
||||
- [x] Schutzwerk Angebot prüfen und weiterleiten zur Freigabe ✅ 2025-06-04
|
||||
- [x] Rollout RMS to prod 📅 2025-06-06 ✅ 2025-06-06
|
||||
- [x] Fetch managers faster in RMS for the employee list 📅 2025-06-05 ✅ 2025-06-06
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
12
Daily/2025-06-05.md
Normal file
12
Daily/2025-06-05.md
Normal file
@ -0,0 +1,12 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
brushed: true
|
||||
created: 2025-06-05
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Bestellvorgang Schutzwerk fertigstellen (siehe TAR) 📅 2025-06-05 ✅ 2025-06-06
|
||||
- [x] Einarbeitungsaufgabe für Praktikanten 📅 2025-07-01 ✅ 2025-07-02
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
20
Daily/2025-06-06.md
Normal file
20
Daily/2025-06-06.md
Normal file
@ -0,0 +1,20 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
brushed: true
|
||||
created: 2025-06-06
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Sprint vorbereiten ✅ 2025-06-06
|
||||
- [x] Review vorbereiten ✅ 2025-06-06
|
||||
- [x] Zertifikate für NVRam anpassen -> siehe [2025_04_07_New_CertManager.pptx](https://vgroup-my.sharepoint.com/:p:/g/personal/marc_manz_vector_com/EY36orSIhMVJqRSKQ30C1SIBptWDGz40YHAhMTnuNyVwdA?e=sLlCXc) ✅ 2025-06-06
|
||||
- [x] SSL Zertifikat für Supabase einrichten ✅ 2025-06-12
|
||||
- [x] Review [DFD NES App](https://github1.vg.vector.int/pes/team-services-nvram-endurance-simulation-app/pull/80) ✅ 2025-06-12
|
||||
- [x] Review [Mayer, Jürgen: Hallo Günther, ich habe jetzt einen ersten Stand des "Working with...](https://teams.microsoft.com/l/message/19:5a2d2bf1-d3f0-45ba-9b8b-c4893b40f614_90289b73-4794-484c-9534-20e2be3f9fef@unq.gbl.spaces/1749055066261?context=%7B%22contextType%22%3A%22chat%22%7D) ✅ 2025-06-12
|
||||
- [ ] Activate Vector France Absence transformation (contact Felicien duplan) #planned 🆔 xtdyyl ➕ 2025-06-06
|
||||
- [ ] Make a ticket #rms ⛔ xtdyyl
|
||||
- [ ] Implementation (basically deploy to RMS namespace) #rms ⛔ xtdyyl
|
||||
- [ ] Support Request Ticket for RMS is wrong -> create a Ticket #rms
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
12
Daily/2025-06-12.md
Normal file
12
Daily/2025-06-12.md
Normal file
@ -0,0 +1,12 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
created: 2025-06-12
|
||||
brushed: "false"
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Review [[Alena]]s Supabase MR -> [MR](https://gitlab.vi.vector.int/pes/infrastructure/services/data-mesh/infrastructure/pes-supabase/-/merge_requests/1) ✅ 2025-07-04
|
||||
- [x] Technischer User für DataMesh anlegen ✅ 2025-09-01
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
10
Daily/2025-06-13.md
Normal file
10
Daily/2025-06-13.md
Normal file
@ -0,0 +1,10 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Ersten Meilenstein in Epics zerstückeln [[DataMesh - Meilensteine]] ✅ 2025-06-18
|
||||
- [x] Roadmap erstellen und Vorschlag an Torsten schicken ✅ 2025-07-04
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
9
Daily/2025-06-16.md
Normal file
9
Daily/2025-06-16.md
Normal file
@ -0,0 +1,9 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Es scheint als ob wir über unsere Domain nicht auf den Postgres Port zugreifen können -> nochmal testen und eventuell ein Ticket anlegen ✅ 2025-09-01 (habs getestet und man kann schon via URI data-mesh-test.vi.vector.int zugreifen)
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
10
Daily/2025-06-18.md
Normal file
10
Daily/2025-06-18.md
Normal file
@ -0,0 +1,10 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Deploy into dev + rev and also to ppi ✅ 2025-06-18
|
||||
- Created a view for managers in RMS
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
26
Daily/2025-06-30.md
Normal file
26
Daily/2025-06-30.md
Normal file
@ -0,0 +1,26 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
Abstimmung weiteres Vorgehen CapaPlan CAT3
|
||||
- Tool Handling zu kompliziert
|
||||
- GIT als Dateiablage zu umständlich
|
||||
|
||||
Mögliche Lösungen
|
||||
- Toollösung noch passend (generell)?
|
||||
- Thomas: Standalone Tool wünschenswert
|
||||
- Klaus: Hört sich so an als wünscht ihr euch ein Web Tool
|
||||
- Nutzer des Tools/Weblösung ca. 24. Wächst aber nicht mehr als 30
|
||||
|
||||
- Theia ist raus
|
||||
- Jürgen besprechen wie man Capaplan als Webtool anbieten könnte
|
||||
- Navigation flache Liste
|
||||
- Andere Möglichkeit: abstrahiertes Filesystem via https://code.visualstudio.com/api/references/vscode-api#FileSystemProvider -> man könnte XaC Filesystem anbieten
|
||||
|
||||
RMS
|
||||
|
||||
-
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
13
Daily/2025-07-03.md
Normal file
13
Daily/2025-07-03.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- Termin CAT3 ausfallen lassen
|
||||
- Lupe um Details offensichtlicher zu machen bei Team Services
|
||||
- "Open Dialog" -> "New Simulation"
|
||||
- Falls man config in der Web Applikation ausliest -> man kann auch die Variante auslesen (also FeeFlexNor oder FeeClassic)
|
||||
- Backstage Roadmap
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
29
Daily/2025-07-04.md
Normal file
29
Daily/2025-07-04.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
## Notes
|
||||
- Deployment für RMS in Dev failed weil "Forbidden"
|
||||
- [x] Team Services Systemtest wenn hängt weil z. B. der Storage Service nicht gefunden wird, sollte abbrechen anstatt weiter zu laufen (undefiniert wie lange) ✅ 2025-12-18
|
||||
- RMS Pipeline fehlgeschlagen - vermutlich weil im Test H2 benutzt wird und das View Script nur für MSSQL funktioniert.
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-07-07.md
Normal file
32
Daily/2025-07-07.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
## Notes
|
||||
|
||||
- Deployed RMS 0.20.8 into **test** environment
|
||||
- Klaus im Teammeeting: Nicht wahrscheinlich, dass wir andere Dinge machen müssen in Zukunft
|
||||
- [x] Repo anlegen für Moritz und Einarbeitungsaufgaben pushen ✅ 2025-07-31
|
||||
- [x] Tomas vistmm Urlaube überprüfen ✅ 2025-07-08
|
||||
- Offensichtlich ist Tomas in keinem PES Team mehr und deswegen kriegen wir keine Absence Informationen für ihn
|
||||
- [x] Multiline Feld für Kommentare für Primary Organization ✅ 2025-09-01
|
||||
- [ ] Suche nach Manager bzw. nach Linienteam / Primary Team #rms
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
54
Daily/2025-07-08.md
Normal file
54
Daily/2025-07-08.md
Normal file
@ -0,0 +1,54 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] Abstimmen mit Stefan bezüglich vTime Daten ✅ 2025-07-08
|
||||
Sie brauchen die Zeiten von Mitarbeitern auf die verschiedenen Projekte
|
||||
> [!NOTE]- Email
|
||||
> Hallo Günther,
|
||||
>
|
||||
> kannst Du das mit Stefan abstimmen?
|
||||
>
|
||||
> Gruß
|
||||
>
|
||||
> Klaus
|
||||
>
|
||||
> **From:** Schorer, Stefan <[Stefan.Schorer@vector.com](mailto:Stefan.Schorer@vector.com)>
|
||||
> **Sent:** Tuesday, July 8, 2025 7:31 AM
|
||||
> **To:** Bergdolt, Klaus <[Klaus.Bergdolt@vector.com](mailto:Klaus.Bergdolt@vector.com)>
|
||||
> **Cc:** Gronbach, Alexander <[Alexander.Gronbach@vector.com](mailto:Alexander.Gronbach@vector.com)>
|
||||
> **Subject:** vTime Daten in der Supabase
|
||||
>
|
||||
> Hi Klaus,
|
||||
>
|
||||
> wir haben eigentlich noch die Aufnahme von vTime Daten in unser Squore Resource Management Dashboard auf der Roadmap. Ein Student bei uns hat sich hierzu auch schonmal angeschaut, wie wir an die Daten aus vTime rankommen würden.
|
||||
>
|
||||
> Da vTime aber weder eine RestAPI noch eine richtige CLI bietet kommt er aktuell hier nicht wirklich weiter.
|
||||
>
|
||||
> Denkst du es wäre möglich, dass er mit eurer Unterstützung versucht die vTime Daten anstatt auf unseren Squore Server direkt in die Supabase für das Data Mesh zu bekommen?
|
||||
>
|
||||
> Gruß
|
||||
>
|
||||
> Stefan
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-07-11.md
Normal file
27
Daily/2025-07-11.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [Polly](https://github.com/App-vNext/Polly) für Retry -> nur bei sinnvollen Errorcodes vom StorageService einen Retry versuchen. Bei 404 einen Error zur App schicken
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-07-17.md
Normal file
27
Daily/2025-07-17.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
31
Daily/2025-07-21.md
Normal file
31
Daily/2025-07-21.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- RMS Datenanpassung für Anja Unnasch. #info inaktive Employees können nicht mehr nachträglich angepasst werden!
|
||||
- Marc hat noch den keda scaler angepasst. Ich hatte letzte Woche noch die Queue Namen für die App <--> Worker Kommunikation angepasst, da dort keine versioned entity abgebildet war. Aber der Scaler liest ja eine dieser Queues mit weswegen das Scaling nicht mehr funktionierte
|
||||
- Manuelles Upload von Daten (z. B. Excel)
|
||||
- Dashboard Applikation. Vorgehen und Einsatzzwecke
|
||||
- CrossInvoicing Extract & Load hätte von Pascal gemacht werden sollen -> nachfragen
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
52
Daily/2025-07-22.md
Normal file
52
Daily/2025-07-22.md
Normal file
@ -0,0 +1,52 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- DataMesh Vortrag GruppenMeeting
|
||||
- Motivation (Klaus technisch, Torsten fachlich)
|
||||
- Architektur + Technologie (Klaus)
|
||||
- MVP (Günther) + veHub Budget information
|
||||
- Workflow lokale Entwicklung (Datenschutz, test und prod soll niemand direkt nutzen) (Günther)
|
||||
- Komplette Developer Story (Vision)
|
||||
- Dashboard Entwicklung Story fehlt noch
|
||||
- Wie gehts weiter?
|
||||
- Dashboard Verwaltung (Günther)
|
||||
- Assistenz-Integration (Günther - kurz)
|
||||
- Zukunftsthemen (Torsten)
|
||||
- Squore Ablösung
|
||||
- QDP
|
||||
|
||||
- NVRam goes live
|
||||
- Disclaimer fehlt
|
||||
- Einige Texte noch anpassen
|
||||
- Resourcelimits noch einstellen für den Worker
|
||||
- Evaluation wird in diesem Sprint gemacht
|
||||
- CSP muss aufgeschlaut werden
|
||||
- Silent deployen weil wir Pilotkunden erstmal onboarden wollen
|
||||
- PenTest:
|
||||
- HTML Injection verhindern
|
||||
- StorageService Problem analysieren
|
||||
- Introduction & FAQ -> Michael
|
||||
- Sortierung der Fee Varianten nicht stabil -> Issue
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-07-23.md
Normal file
27
Daily/2025-07-23.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
31
Daily/2025-07-24.md
Normal file
31
Daily/2025-07-24.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- HTML Injection Problem fertig gestellt
|
||||
- Data Mesh Folien für morgen erstellt
|
||||
- NVRam TEG Feedback
|
||||
- NVRam Partition Names -> ohne Leerzeichen und ohne Unicode (Regex anpassen)
|
||||
- NVRam Project Names -> html sanitazion verwenden (um )
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
34
Daily/2025-07-25.md
Normal file
34
Daily/2025-07-25.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- sanitation als bad request zurückgeben
|
||||
- Frontend validierung für project name
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
|
||||
# Day planner
|
||||
|
||||
- [x] 12:00 - 12:30 NVRam Storage Service ✅ 2025-07-25
|
||||
- [x] 12:30 - 12:45 Daily ✅ 2025-07-25
|
||||
- [x] 12:45 - 13:30 NVRam Storage Service ✅ 2025-07-31
|
||||
49
Daily/2025-07-28.md
Normal file
49
Daily/2025-07-28.md
Normal file
@ -0,0 +1,49 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- Backstage
|
||||
- Software Catalog
|
||||
- TechDoc
|
||||
- LDAP Signin
|
||||
- Single Sign on? Möglich über veHub?
|
||||
- Owner -> abhängig vom catalog.info -> Möglichkeit des Bulk-Changes
|
||||
- Todo:
|
||||
- Instanz aufsetzen?! Oder die bestehende "hijacken"
|
||||
- Templating
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
|
||||
# Day planner
|
||||
|
||||
- [x] 09:00 - 10:00 Cross Invoicing Requirements ✅ 2025-07-28
|
||||
- [x] 10:30 - 11:00 1 on 1 Moritz ✅ 2025-07-28
|
||||
- [x] 13:00 - 13:30 Backstage Sync ✅ 2025-07-28
|
||||
- [x] 13:30 - 14:00 Monitoring ✅ 2025-07-28
|
||||
- [x] 14:00 - 14:30 TeamServices ✅ 2025-07-28
|
||||
- [x] 15:00 - 15:30 Rücksprache ✅ 2025-07-28
|
||||
- [x] 11:00 - 11:30 Resourcelimits für worker/container ✅ 2025-07-28
|
||||
- [x] 11:30 - 12:00 FeeVarianten sortieren ✅ 2025-07-28
|
||||
- [x] 12:00 - 12:30 Mittag ✅ 2025-07-28
|
||||
- [x] 12:30 - 12:45 Daily ✅ 2025-07-28
|
||||
- [x] 14:30 - 15:00 Praktikumsaufgaben ✅ 2025-07-28
|
||||
34
Daily/2025-07-29.md
Normal file
34
Daily/2025-07-29.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- [x] RMS it test failure ➕ 2025-07-29 📅 2025-07-30 ✅ 2025-09-01
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
|
||||
# Day planner
|
||||
|
||||
- [x] 14:00 - 15:15 SBA Produkt Roadmap ✅ 2025-07-29
|
||||
- [x] 08:00 - 08:30 Backstage Issues anlegen ✅ 2025-07-29
|
||||
- [x] 08:30 - 09:00 Cross Invoicing: Auslesen von Issues zusammen mit Worklogs ✅ 2025-07-29
|
||||
- [x] 09:00 - 11:00 Complete Planner tasks ✅ 2025-07-29
|
||||
27
Daily/2025-07-30.md
Normal file
27
Daily/2025-07-30.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- Fix the test errors in NVram
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-08-01.md
Normal file
27
Daily/2025-08-01.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- Superset `docker-compose` für mich selbst einrichten -> Als entsprechendes docker image in gitlab repo festhalten
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-08-04.md
Normal file
27
Daily/2025-08-04.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-08-06.md
Normal file
27
Daily/2025-08-06.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
43
Daily/2025-08-08.md
Normal file
43
Daily/2025-08-08.md
Normal file
@ -0,0 +1,43 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- GeneralExceptionFilter in ScriptService als Beispiel
|
||||
- AccountExceptionFilter in AccountService als Beispiel
|
||||
|
||||
|
||||
| produkt | done | Notes |
|
||||
| ------------- | ---- | ----------------------------------- |
|
||||
| vds-prod | ✅ | |
|
||||
| xac-prod | ✅ | nicht base64 encodiert |
|
||||
| superset-prod | ❌ | keine Pipeline aktuell beim rollout |
|
||||
| snds-prod | ✅ | |
|
||||
| rms-prod | ✅ | |
|
||||
| pkgm-prod | | |
|
||||
| lds-prod | ✅ | |
|
||||
| fps-prod | ✅ | |
|
||||
| crs-prod | ✅ | |
|
||||
| | | |
|
||||
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
29
Daily/2025-08-11.md
Normal file
29
Daily/2025-08-11.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- 08:14: Passe den SimulationController an und harmonisiere die benutzten Model Klassen. Klare Trennung zwischen Read/Create Models und internen Entities.
|
||||
- 08:38: Planung CAT3 mit Jürgen als Backlog Refinement
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
39
Daily/2025-08-18.md
Normal file
39
Daily/2025-08-18.md
Normal file
@ -0,0 +1,39 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Tasks
|
||||
|
||||
- [x] 08:00 - 10:30 Fix Hexagonal Review von Marc ✅ 2025-08-18
|
||||
- [x] 10:30 - 11:00 1 on 1 Moritz ✅ 2025-08-18
|
||||
- [x] 11:00 - 11:30 Check developer documentation sqlmesh ✅ 2025-08-18
|
||||
- [x] 14:30 - 15:30 ALMplus & Datamesh ✅ 2025-08-19
|
||||
- [x] 11:30 - 14:30 Implement Statusmonitor SNDS ✅ 2025-09-01
|
||||
- [x] Implement Shutdown Signal for Team Services ✅ 2025-11-14
|
||||
## Notes
|
||||
|
||||
|
||||
|
||||
## Accomplishment makes the day great
|
||||
|
||||
- [x] Clean the desk
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
27
Daily/2025-08-19.md
Normal file
27
Daily/2025-08-19.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- #daily Influxdb: wie erstellt man da eine neue Datenbank? Gibt es ein Dashboard oder ähnliches?
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
28
Daily/2025-08-20.md
Normal file
28
Daily/2025-08-20.md
Normal file
@ -0,0 +1,28 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
|
||||
33
Daily/2025-08-22.md
Normal file
33
Daily/2025-08-22.md
Normal file
@ -0,0 +1,33 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Notes
|
||||
|
||||
- 08:39 Vorbereiten des Tages
|
||||
- 11:19 Hab den Bug gefixt in RMS. Die Calendar Dates sind wieder zu kurz und mussten verlängert werden.
|
||||
|
||||
## Tasks
|
||||
|
||||
- [x] RMS IT test failure untersuchen ✅ 2025-08-22
|
||||
- [ ] Docker compose für [[Local Development Setup DataMesh.canvas|Local Development Setup DataMesh]] fertig machen #datamesh
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
39
Daily/2025-08-25.md
Normal file
39
Daily/2025-08-25.md
Normal file
@ -0,0 +1,39 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
## Todos
|
||||
|
||||
- [x] [Meetingnotes](https://vgroup-my.sharepoint.com/:fl:/r/personal/guenther_wagner_vector_com/Documents/Besprechungen/Epics%20%26%20PI-Planung.loop?d=w9409a7f04a3a4f1998f49b0cb969032c&csf=1&web=1&e=sBKRIT&nav=cz0lMkZwZXJzb25hbCUyRmd1ZW50aGVyX3dhZ25lcl92ZWN0b3JfY29tJmQ9YiUyMUl2RlhuMW5YdFV1NkxxRGZhVHNIT3F5QThWT2tHd0ZMaTQ0b3hXVmZZekg3M3puWVJoQXVSYVY0RnFtNXI5ZnMmZj0wMUxJUVlZUlhRVTRFWklPU0tERkhaUjVFM0JTNFdTQVpNJmM9JTJGJmE9TG9vcEFwcA%3D%3D) in Epics transferieren ✅ 2025-12-18
|
||||
- [x] Teilweise - habs im Loop markiert ✅ 2025-08-25
|
||||
- [x] Invoiceservice überprüfen ✅ 2025-08-25
|
||||
- [x] Sprint vorbereiten ✅ 2025-08-25
|
||||
- [ ] Import Skript vervollständigen
|
||||
|
||||
## Notes
|
||||
|
||||
- 07:59 Habe mir gerade einen Überblick verschafft, was ich heute schaffen will.
|
||||
- 10:00 Notizen zu InvoiceService überprüfung:
|
||||
- CS0979039 wurde am 15.07 um 14:17 geschlossen
|
||||
- Am 19.08 wurde das Ticket dann im Budget geändert
|
||||
- Anscheinend wurden dir Requirements geändert und man kann jetzt doch Service Now Cases nachdem sie geschlossen wurden später als 12 Stunden nochmal ändern. Das ursprüngliche Requirement war: nachdem geschlossen wurde kann innerhalb von 12 Stunden das Ticket nochmal geöffnet werden. Das würde bedeuten: Nach 12 Stunden geht nichts mehr. **Jetzt kann man allerdings Service Now Cases nach 12 Stunden sogar noch ändern ohne diese wieder zu öffnen**.
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
31
Daily/2025-08-26.md
Normal file
31
Daily/2025-08-26.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-08-25|← 2025-08-25]] | [[2025-08-27|2025-08-27 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
31
Daily/2025-08-27.md
Normal file
31
Daily/2025-08-27.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-08-26|← 2025-08-26]] | [[2025-08-28|2025-08-28 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
29
Daily/2025-08-28.md
Normal file
29
Daily/2025-08-28.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
[[2025-08-27|← 2025-08-27]] | [[2025-08-29|2025-08-29 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Simulator Version anzeigen im Frontend bei der NES App ✅ 2025-08-29
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
31
Daily/2025-08-29.md
Normal file
31
Daily/2025-08-29.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-08-28|← 2025-08-28]] | [[2025-08-30|2025-08-30 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
36
Daily/2025-08-31.md
Normal file
36
Daily/2025-08-31.md
Normal file
@ -0,0 +1,36 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-08-30|← 2025-08-30]] | [[2025-09-01|2025-09-01 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Stunden aufschreiben ✅ 2025-08-31
|
||||
- [x] TISAX Training machen ✅ 2025-08-31
|
||||
- [x] ServiceNowDataservice Monitoring implementieren ✅ 2025-08-31
|
||||
- [x] Ich muss noch eine @Configuration in die spring starter machen um den StatusMonitorAspect als Bean zu exportieren. Nur dann funktioniert die Annotation innerhalb der Spring Application ✅ 2025-09-01
|
||||
- [x] Ebenfalls muss ich dann noch einen Tag anlegen für die Änderung im Spring starter da ich 1.2 deployed habe aber noch keinen MR dafür angelegt habe. Ebenfalls keine Tests ✅ 2025-09-01
|
||||
- [x] Die ServiceNowDataservice Implementierung muss ich ebenfalls noch commiten. Ich warte aber jetzt erstmal auf die Spring Starter Implementierung, da ich dafür vermutlich noch eine Version publishen muss und den Aspect (den ich Testweise in die Applikation implementiert habe) noch entfernen muss. ✅ 2025-09-01
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
31
Daily/2025-09-01.md
Normal file
31
Daily/2025-09-01.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-08-31|← 2025-08-31]] | [[2025-09-02|2025-09-02 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
35
Daily/2025-09-02.md
Normal file
35
Daily/2025-09-02.md
Normal file
@ -0,0 +1,35 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-09-01|← 2025-09-01]] | [[2025-09-03|2025-09-03 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- 10:17 Fixed the RMS tests
|
||||
- 16:01 Realized that RMS still tries to push absences to BigPicture (which is not installed anymore in Jira)
|
||||
- [x] Remove Bigpicture sync in RMS ✅ 2025-09-04
|
||||
|
||||
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-09-04.md
Normal file
32
Daily/2025-09-04.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-09-03|← 2025-09-03]] | [[2025-09-05|2025-09-05 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- 09:10 Created a [MR](https://gitlab.vi.vector.int/pes/infrastructure/services/jiraservices/services/pes-resource-management-service/-/merge_requests/376) for the removal of BigPicture in RMS. To be sure that this change is valid I informed Sebastian Gayer about this and wait now for a response. If 👌 I will add Pavel as reviewer
|
||||
-
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
36
Daily/2025-09-08.md
Normal file
36
Daily/2025-09-08.md
Normal file
@ -0,0 +1,36 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
[[2025-09-07|← 2025-09-07]] | [[2025-09-09|2025-09-09 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Deployment NVram Stage für [[NVRam Endurance Simulation]] ✅ 2025-09-09
|
||||
|
||||
- 10:12: Hab bei Billmann Andreas mal nachgefragt, warum in meinem NVram Stage der Keycloak nicht hochkommt bzw. warum das Secret `keycloak-db` nicht erstellt wird. Eventuell ist das noch nicht notwendig und ich kann auf dem alten Keycloak bleiben
|
||||
|
||||
- [x] 16:02: Reise nach Stuttgart im Oktober buchen ✅ 2025-09-09
|
||||
- [x] Termin Mittwoch für Dashboard Entwicklung DataMesh ✅ 2025-09-08
|
||||
- [x] Termin Mittowoch für XaC Platform vs Generator ✅ 2025-09-08
|
||||
- 12:09: Merge Request bezüglich sqlmesh muss noch angeschaut werden
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-09-09.md
Normal file
32
Daily/2025-09-09.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-09-08|← 2025-09-08]] | [[2025-09-10|2025-09-10 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Retro anlegen für Punkte in Konzepte & ADRs
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
35
Daily/2025-09-10.md
Normal file
35
Daily/2025-09-10.md
Normal file
@ -0,0 +1,35 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-09-09|← 2025-09-09]] | [[2025-09-11|2025-09-11 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Rollout SNDS to production ✅ 2025-09-10
|
||||
- 07:16: Start to rollout TeamServices to DEV## Other
|
||||
- 07:21: Updated Simulator to 0.3.0 and updated the nvram stage to use 0.9.52 (the next version after the merge) to take the new simulator
|
||||
- [x] 09:27: Install kubectl in Devcontainer ✅ 2025-09-10
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
37
Daily/2025-10-13.md
Normal file
37
Daily/2025-10-13.md
Normal file
@ -0,0 +1,37 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-12|← 2025-10-12]] | [[2025-10-14|2025-10-14 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] TEG Rev Instance funktioniert nicht mehr bzw. ist abgestürzt
|
||||
-
|
||||
- [x] svc-jira-rms-001 Passwort läuft ab ✅ 2025-10-17
|
||||
- [x] vistrpesdmt01 airflow läuft nicht ✅ 2025-10-15
|
||||
- [ ] Manager fixen!
|
||||
- [x] Update Simulator 0.3.2 ✅ 2025-10-15
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-10-14.md
Normal file
32
Daily/2025-10-14.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-13|← 2025-10-13]] | [[2025-10-15|2025-10-15 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
-
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-10-15.md
Normal file
32
Daily/2025-10-15.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-14|← 2025-10-14]] | [[2025-10-16|2025-10-16 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Sidebar öffnet sich zu weit wenn der Logtext lange ist 📅 2025-10-21 ✅ 2025-10-16
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-10-17.md
Normal file
32
Daily/2025-10-17.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-16|← 2025-10-16]] | [[2025-10-18|2025-10-18 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
-
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
32
Daily/2025-10-21.md
Normal file
32
Daily/2025-10-21.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-20|← 2025-10-20]] | [[2025-10-22|2025-10-22 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- [x] Reisekostenabrechnung ✅ 2025-10-21
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
60
Daily/2025-10-22.md
Normal file
60
Daily/2025-10-22.md
Normal file
@ -0,0 +1,60 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-21|← 2025-10-21]] | [[2025-10-23|2025-10-23 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
|
||||
|
||||
## Tasks
|
||||
|
||||
- [x] 10:30 - 11:00 Dashboard für Rev anpassen (Grafana) #nvram ✅ 2025-10-22
|
||||
- [x] Wird der Pod Log in Azure gespeichert? #nvram ✅ 2025-10-23
|
||||
- [x] Zusammenfassen der Execution State und Simulator State #nvram
|
||||
- [x] 10:00 - 10:30 README eintragen wie man eine neue Version release #nvram ✅ 2025-10-22
|
||||
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
|
||||
# Day planner
|
||||
|
||||
- [x] 11:00 - 11:30 Zwischenfeedbackgespräch Moritz ✅ 2025-10-23
|
||||
- Arbeit soweit super
|
||||
- Wichtig ist, falls man KI verwendet, auch zu verstehen, was die KI wirklich gemacht hat
|
||||
- Themen bzgl. Data Engineering vielfältig -> Analysten Sparte aktuell etwas dürftig. Wenn DataMesh Akzeptanz und Benutzung steigt hoffentlich größer werden.
|
||||
- Vielleicht sollte man schonmal über den Praktikumsbericht sprechen? Frühzeitig beginnen!
|
||||
- Feedback von Moritz:
|
||||
- Im großen und ganzen passt alles
|
||||
- Datenanalyse kommt jetzt erst
|
||||
- Row Level Security hat mir am besten gefallen
|
||||
- Einführungsaufgaben waren gut
|
||||
- Airflow war nicht so schön
|
||||
- Räumliche Trennung ist blöd
|
||||
- Roter Faden für Praktikum bzw. Roadmap
|
||||
- [x] 11:30 - 12:30 NVRam Team Services Sync ✅ 2025-10-23
|
||||
- [x] 13:00 - 14:00 Weekly ✅ 2025-10-23
|
||||
- [x] 14:00 - 15:00 Sprint Planning ✅ 2025-10-23
|
||||
- [x] 15:00 - 17:00 Portfolio Strategy ✅ 2025-10-23
|
||||
32
Daily/2025-10-23.md
Normal file
32
Daily/2025-10-23.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- daily
|
||||
---
|
||||
|
||||
|
||||
[[2025-10-22|← 2025-10-22]] | [[2025-10-24|2025-10-24 →]]
|
||||
|
||||
## Notes
|
||||
|
||||
- Frage: Ownership verhindert, dass man als Individual Contributor (IC) nicht auf E5 oder höher aufsteigen kann?
|
||||
## Other
|
||||
|
||||
```meta-bind-button
|
||||
label: New Meeting
|
||||
icon: building
|
||||
style: default
|
||||
class: ""
|
||||
cssStyle: ""
|
||||
backgroundImage: ""
|
||||
tooltip: ""
|
||||
id: ""
|
||||
hidden: false
|
||||
actions:
|
||||
- type: templaterCreateNote
|
||||
templateFile: "Templates/Meeting Template.md"
|
||||
folderPath: Vector
|
||||
fileName: "Rename me"
|
||||
openNote: true
|
||||
```
|
||||
|
||||
![[System/Bases/Daily.base]]
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user